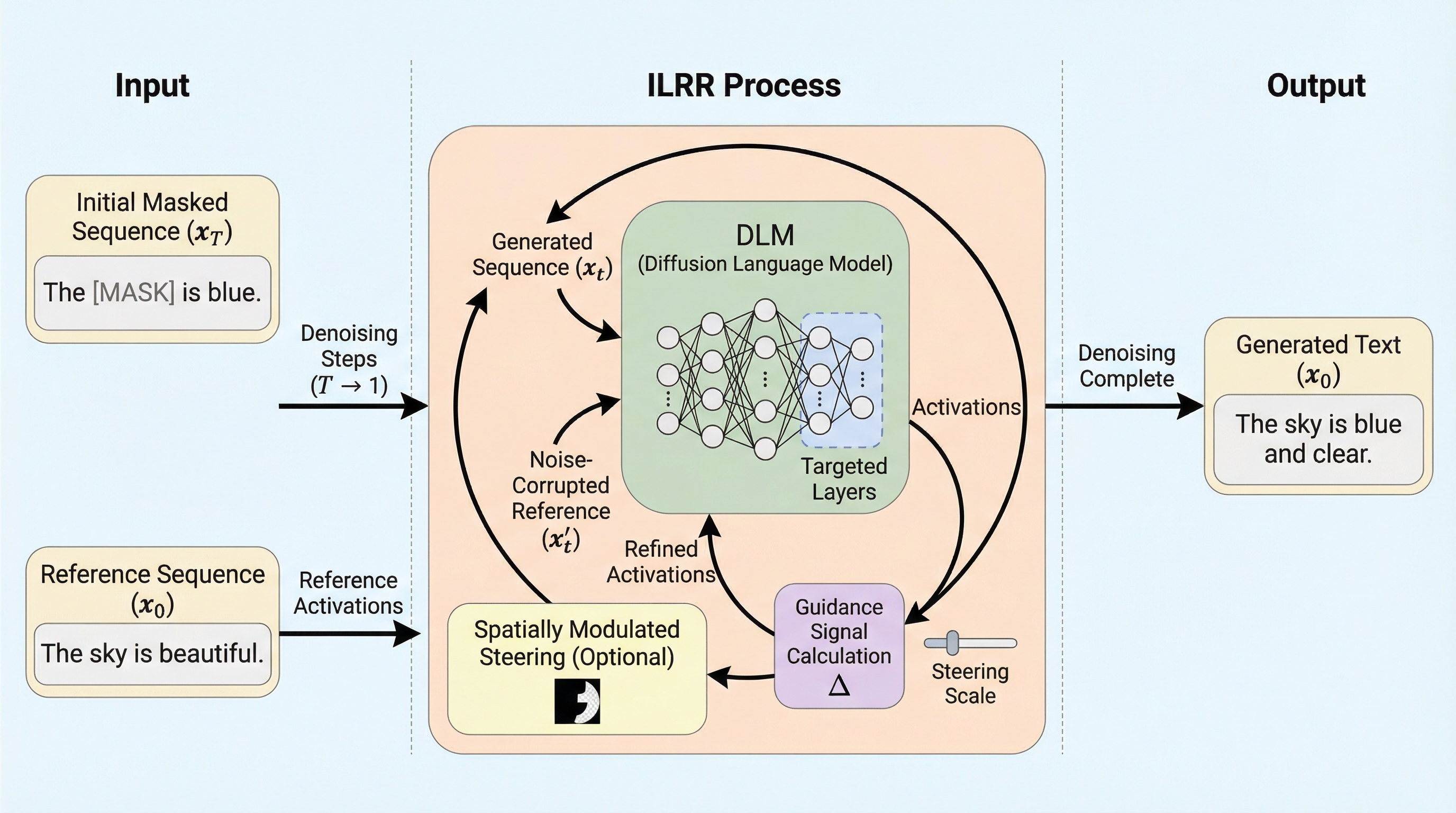
ILRR: マスク型拡散言語モデルのための推論時ステアリング手法
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
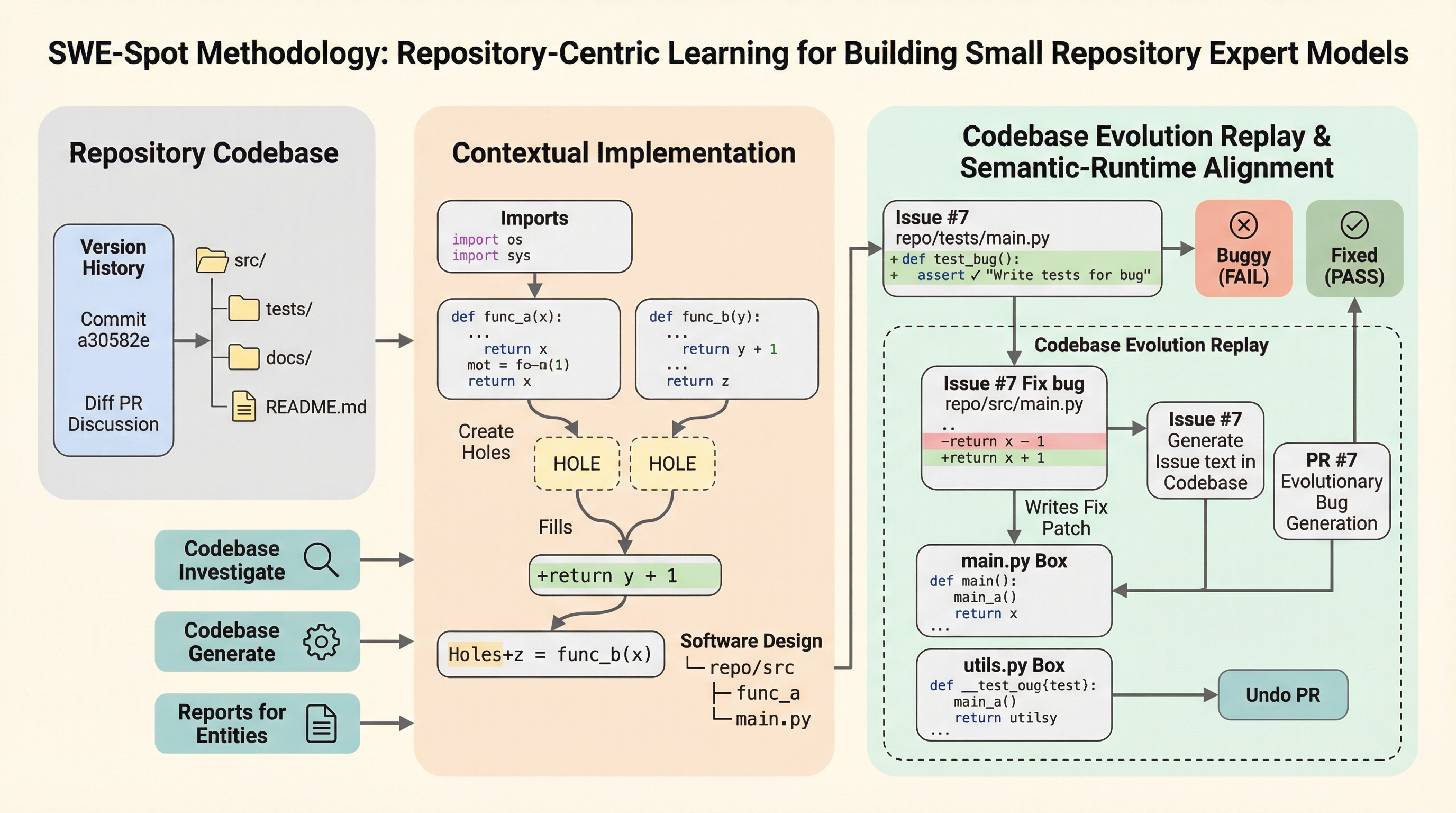
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。
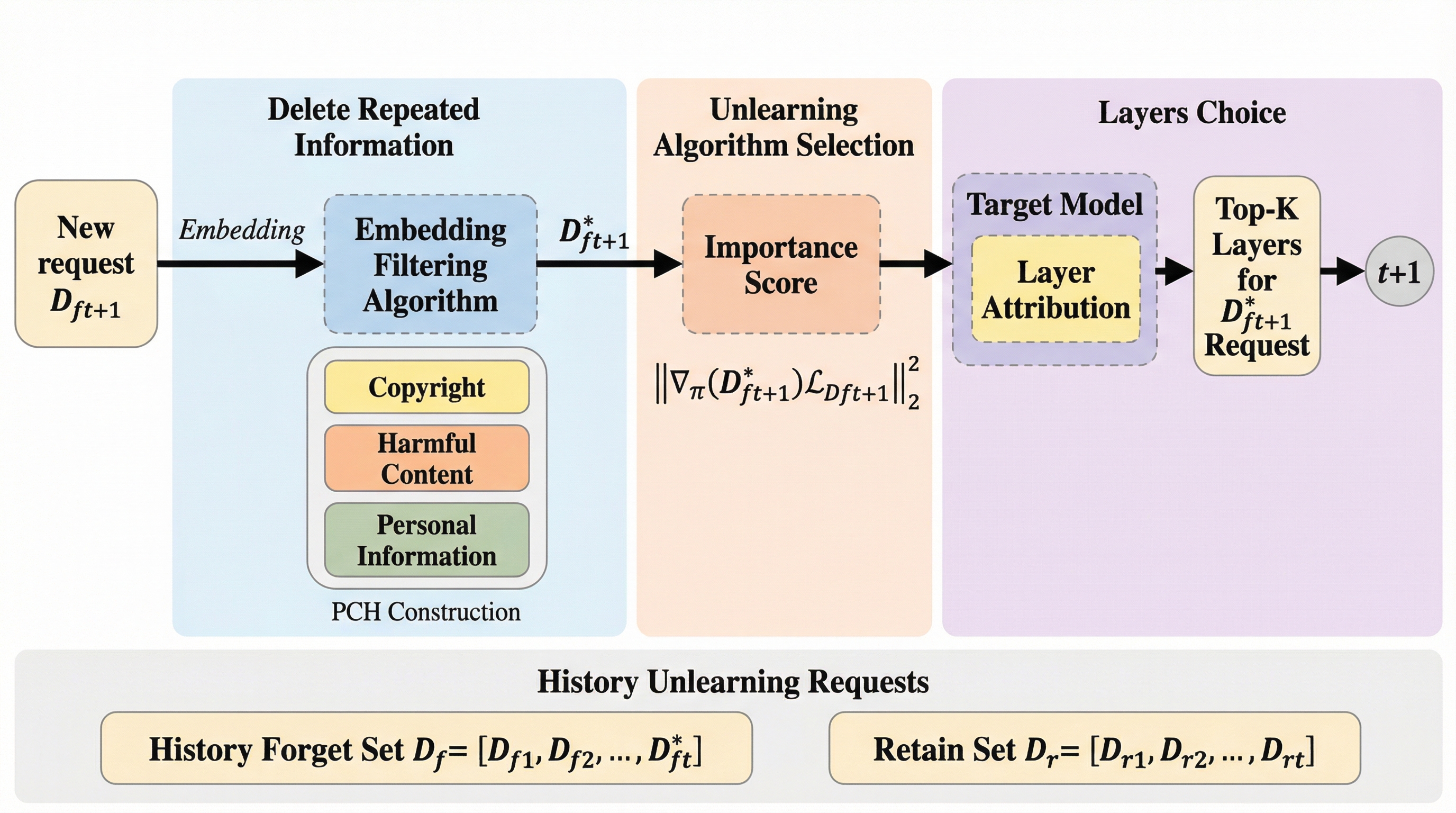
FITは、大規模言語モデル(LLM)が連続的なデータ削除要求を受けた際に発生する「破滅的忘却」を防ぐための新しい学習フレームワークである。 この手法は、重複情報のフィルタリング、重要度に応じたアルゴリズムの適応的選択、そして影響の大きい層に限定した更新という3つの戦略を統合することで、モデルの性能維持と確実な情報消去を両立させている。 また、個人情報や著作権、有害コンテンツを網羅した評価ベンチマーク「PCH」と、消去の度合いと性能維持を統合的に測る新指標を提案し、300件もの連続的な要求に対しても既存手法を凌駕する堅牢性を実証した。
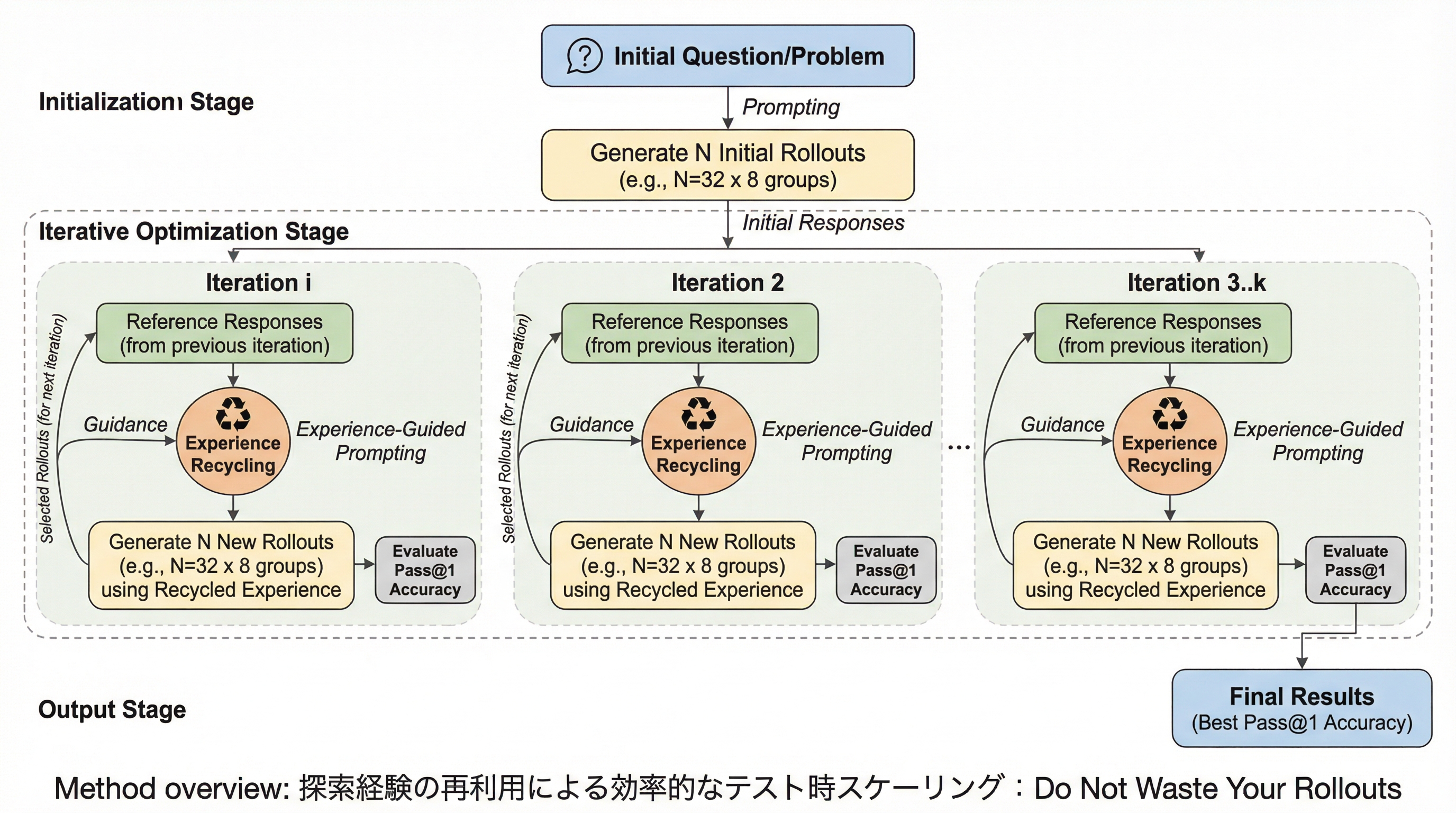
大規模言語モデルの推論能力を高めるテスト時スケーリングにおいて、従来の探索手法が各試行(ロールアウト)を使い捨てにしていた非効率性を指摘し、中間的な洞察を蓄積して再利用する「Recycling Search Experience(RSE)」を提案している。
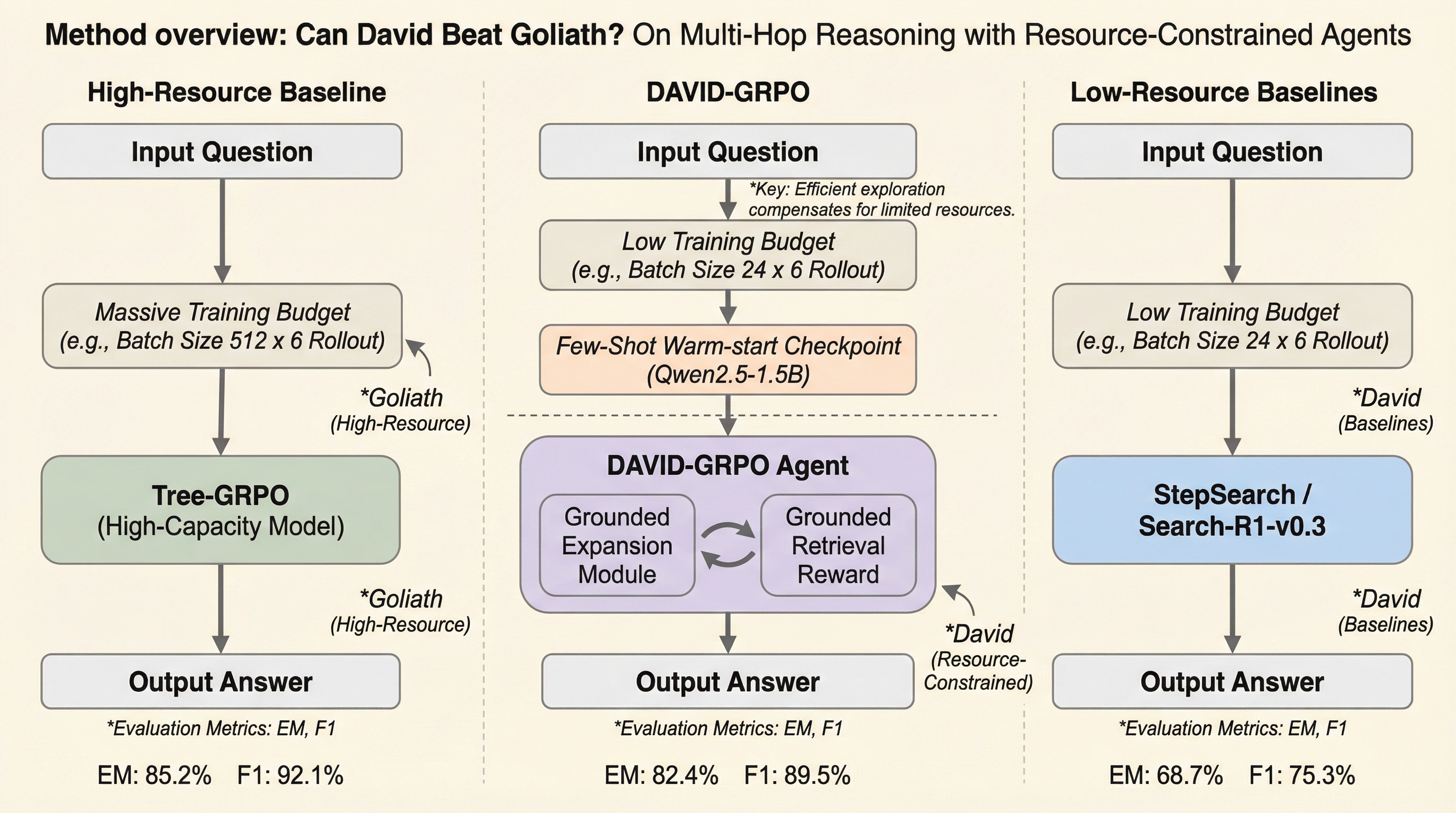
本研究は、計算リソースが極めて限定された環境において、小規模な言語モデルエージェントが大規模モデルに匹敵する高度なマルチホップ推論能力を獲得するための新しい強化学習フレームワーク「DAVID-GRPO」を提案しています。
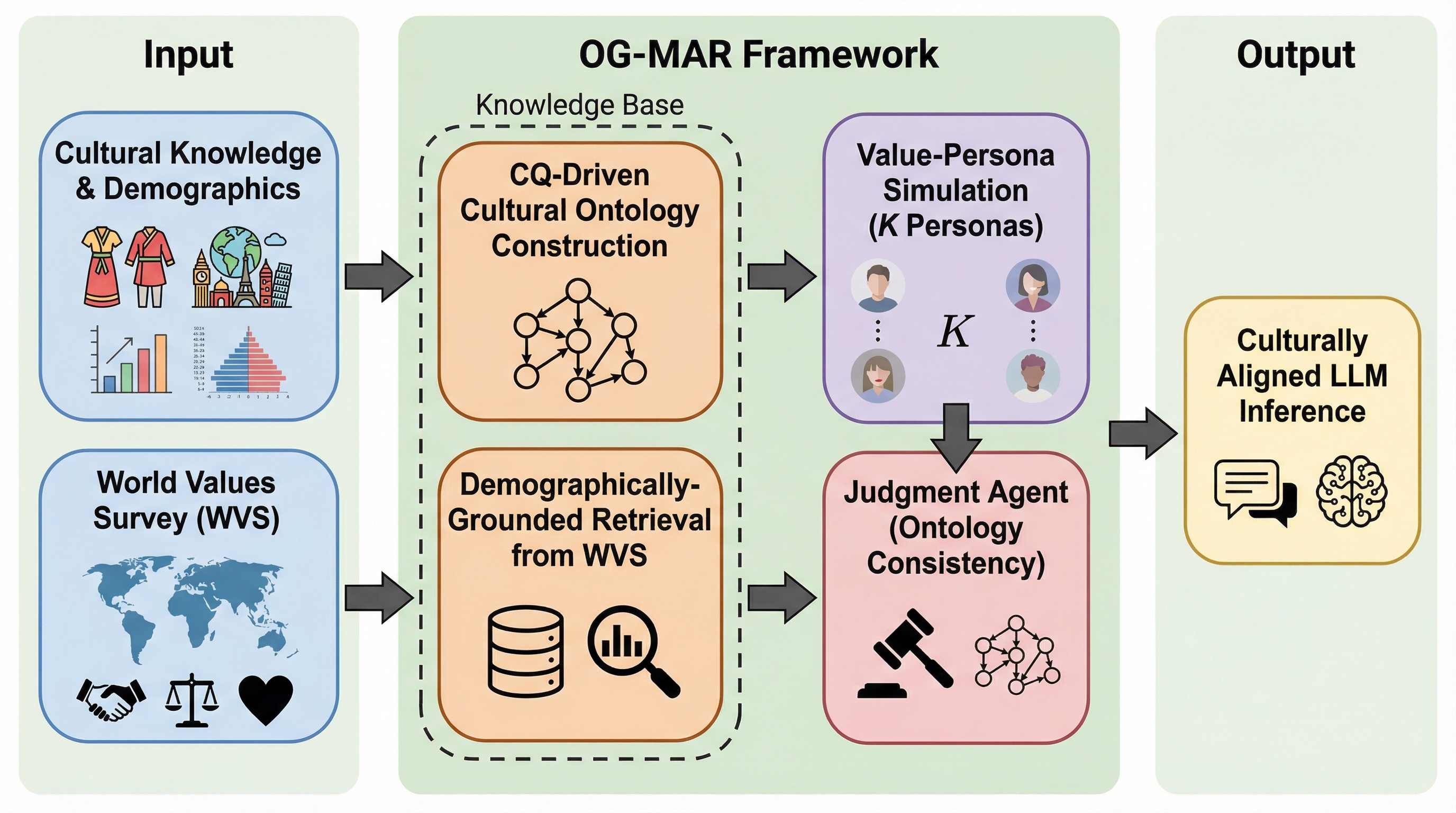
大規模言語モデル(LLM)が欧米中心のデータに偏り、多様な文化圏の価値観を正確に反映できない問題を解決するため、世界価値観調査(WVS)のデータと構造化された知識表現であるオントロジーを組み合わせた新しい推論フレームワーク「OG-MAR」が提案されました。
現在の大規模言語モデルが抱える「一語ずつ順番に生成する」という非効率な逐次処理を打破するため、人間の熟練した読解プロセス(予習・情報の塊化・飛ばし読み)をモデル内部に直接組み込んだ新しいアーキテクチャ「Fovea-Block-Skip Transformer(FBS)」が提案されました。
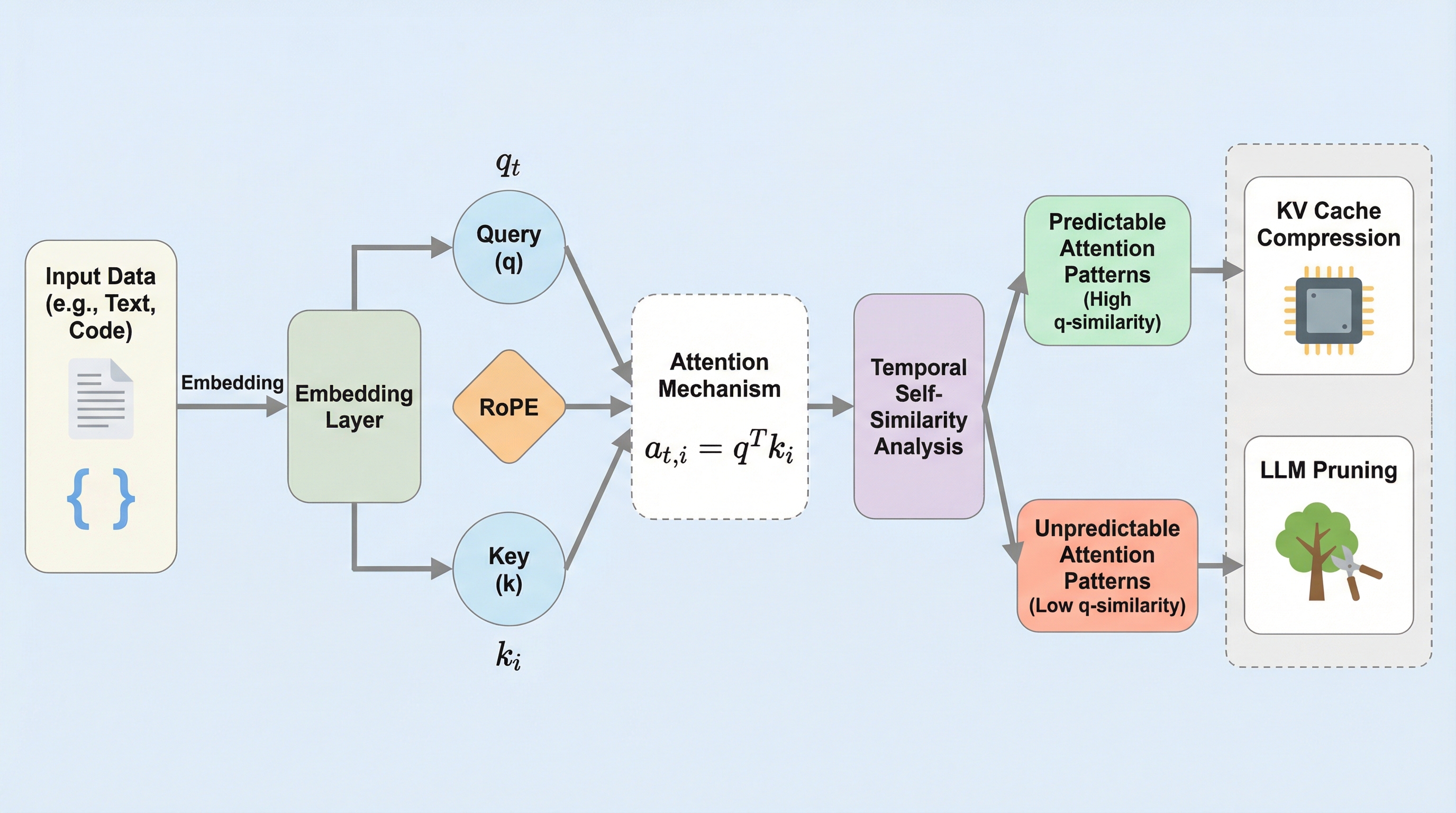
大規模言語モデル(LLM)のアテンションパターンを統一的に説明する理論的枠組み「TAPPA」を提案し、アテンションが予測可能(Predictable)なものと予測不能(Unpredictable)なものに分類されることを数学的に示した。
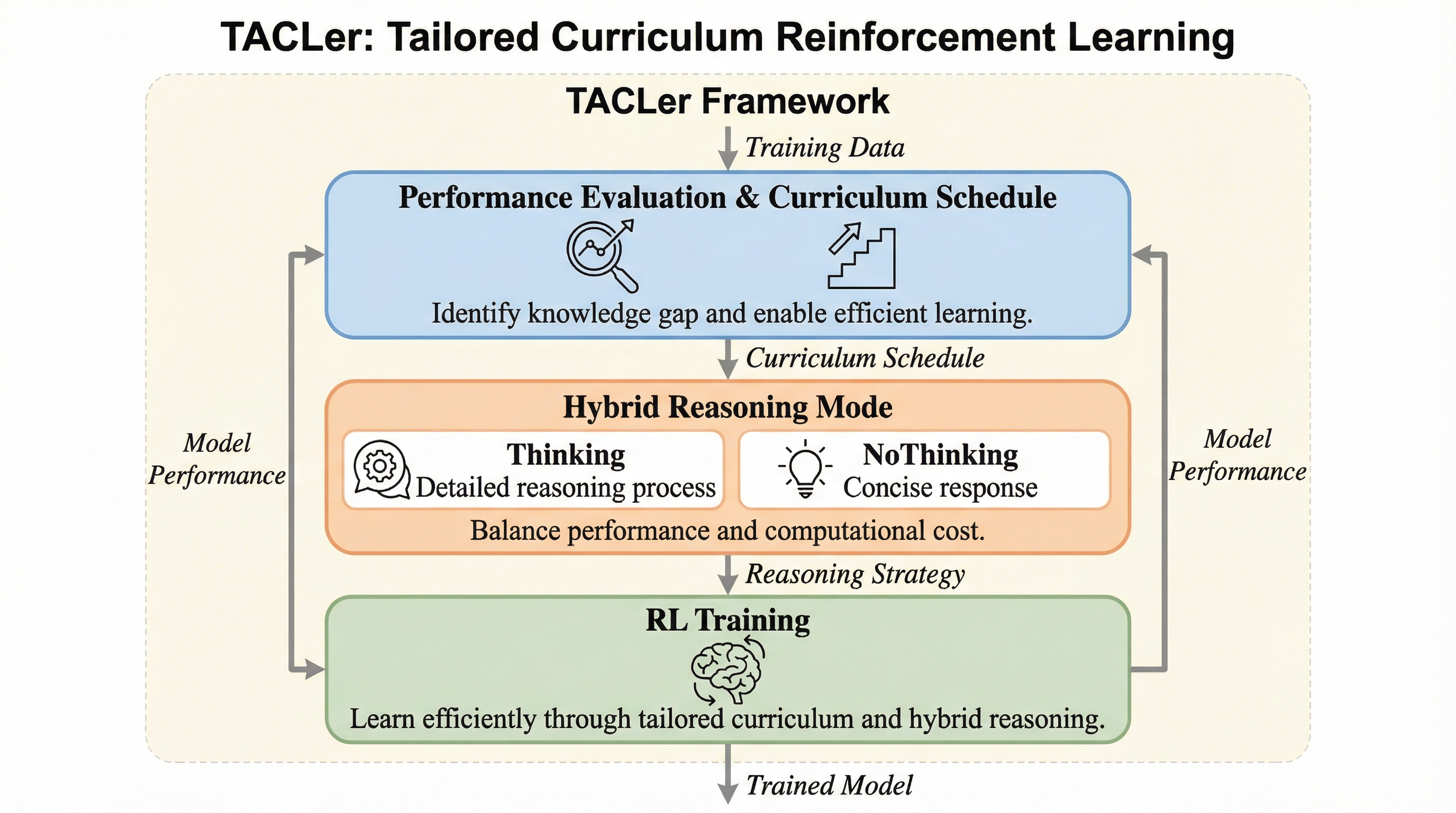
TACLerは、モデルの習熟度に合わせて学習データの難易度を段階的に引き上げる「個別最適化カリキュラム学習」と、詳細な思考と簡潔な回答を使い分ける「ハイブリッド推論モード」を統合した強化学習フレームワークである。
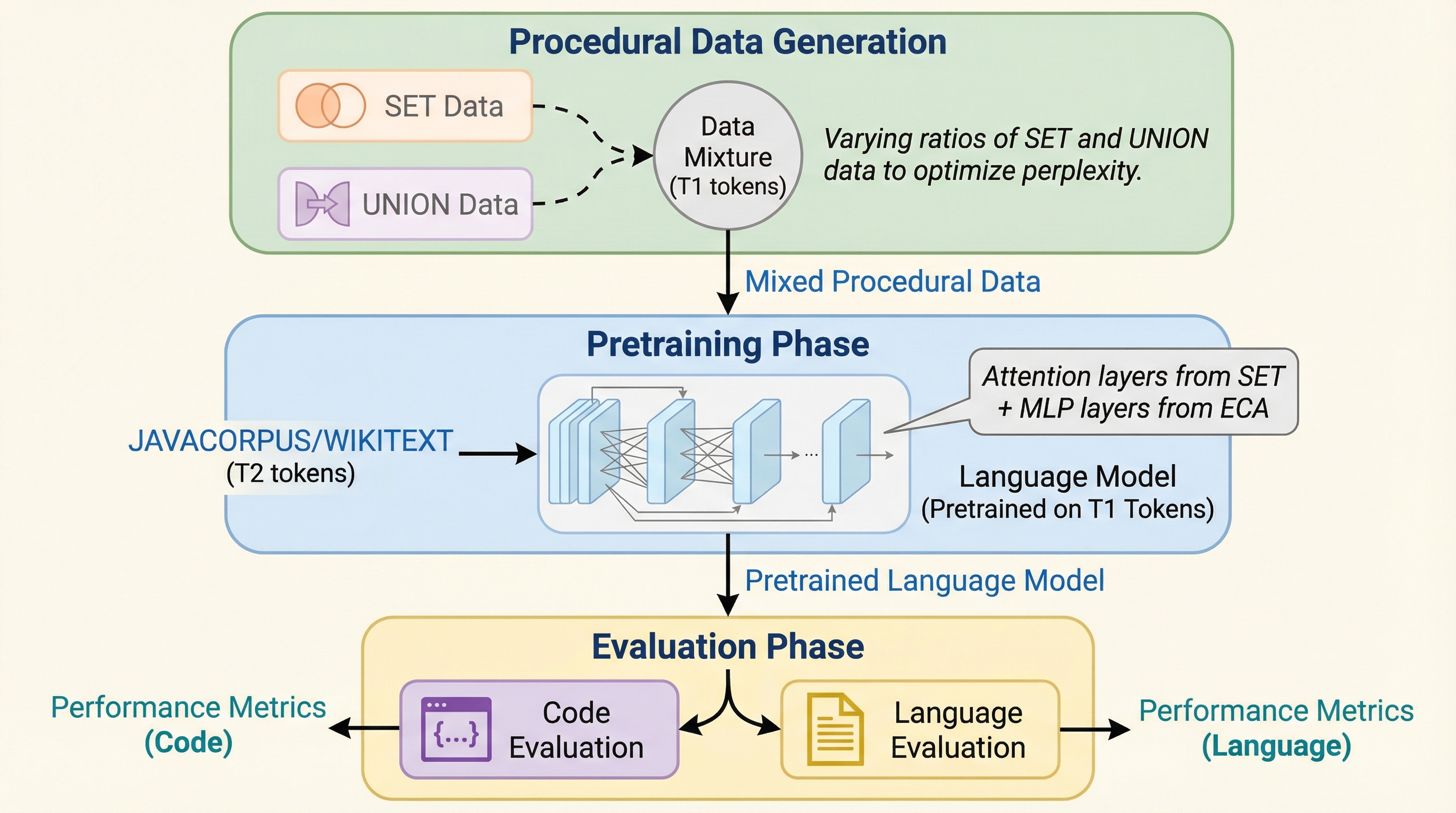
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。