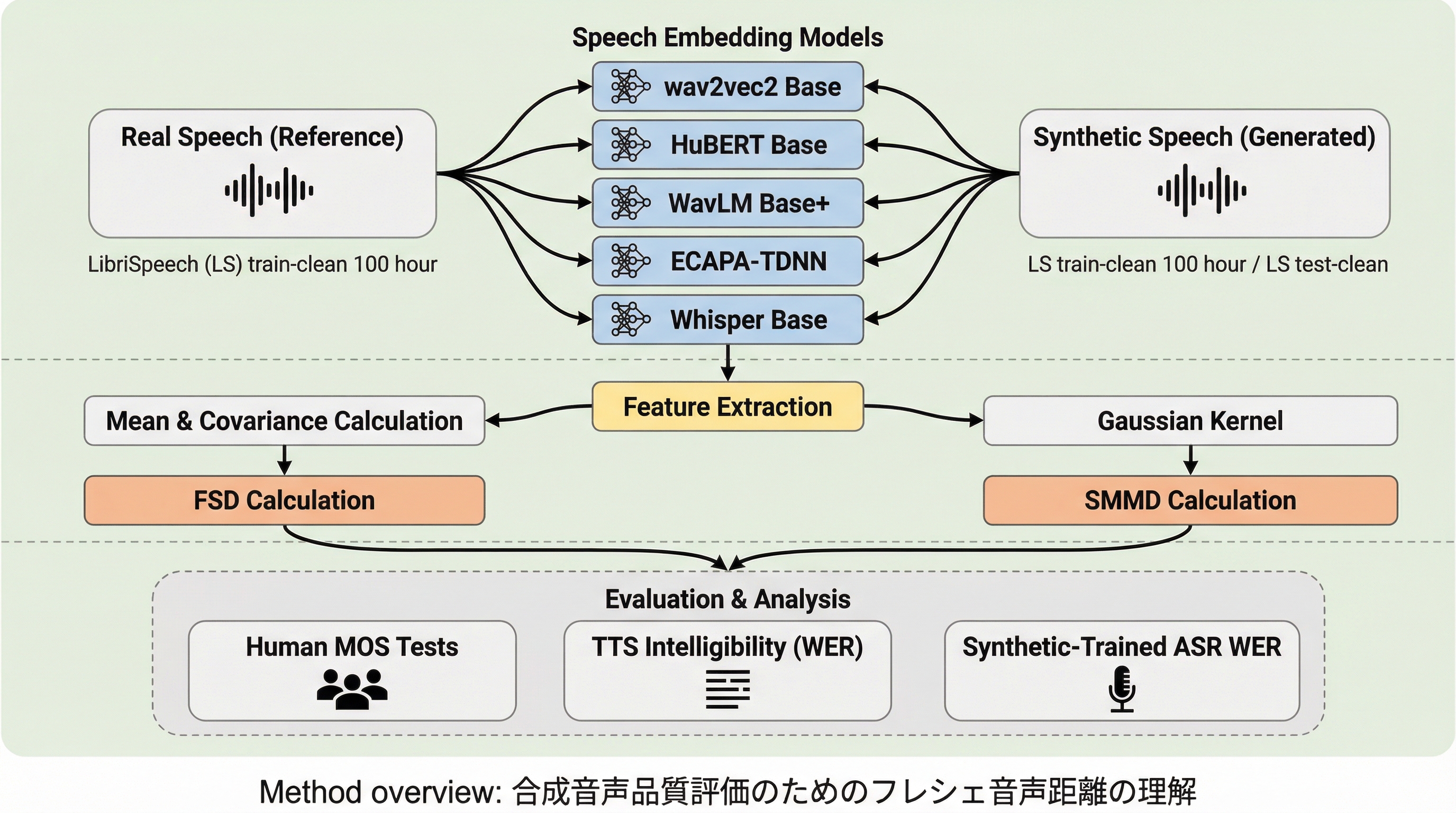
合成音声品質評価のためのフレシェ音声距離の理解
合成音声の品質を客観的に評価するため、画像分野のFIDを応用したフレシェ音声距離(FSD)と、正規分布の仮定を必要としない新指標である音声最大平均不一致(SMMD)の有効性を、WavLMやWhisperを含む5種類の音声埋め込みモデルを用いて体系的に検証しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
合成音声の品質を客観的に評価するため、画像分野のFIDを応用したフレシェ音声距離(FSD)と、正規分布の仮定を必要としない新指標である音声最大平均不一致(SMMD)の有効性を、WavLMやWhisperを含む5種類の音声埋め込みモデルを用いて体系的に検証しました。
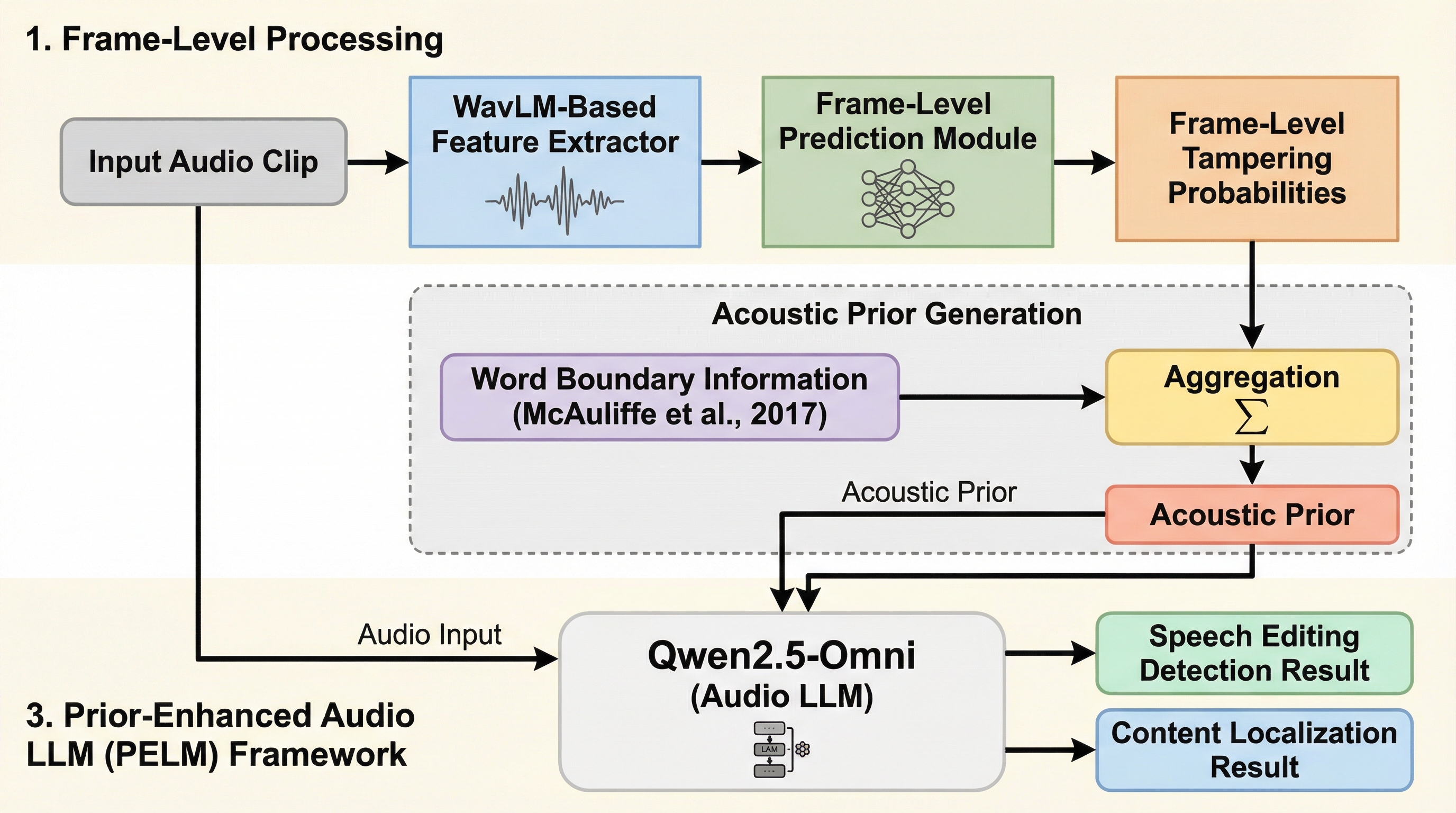
音声の一部を削除・挿入・置換する巧妙な編集を検出するため、大規模言語モデル(LLM)を活用して論理的な改ざんを施した高品質な二言語データセット「AiEdit」を構築しました。 このデータセットを基に、音声編集の検出と改ざん箇所の特定を「音声応答タスク」として統合し、単語レベルの音響的先験情報と一貫性を捉える損失関数を導入した新フレームワーク「PELM」を開発しました。 検証の結果、PELMは従来のオーディオLLMが陥りやすい誤検知や意味内容への偏重を克服し、既存手法を大幅に上回る精度で、継ぎ目のない高度な音声改ざんを識別・特定することに成功しました。
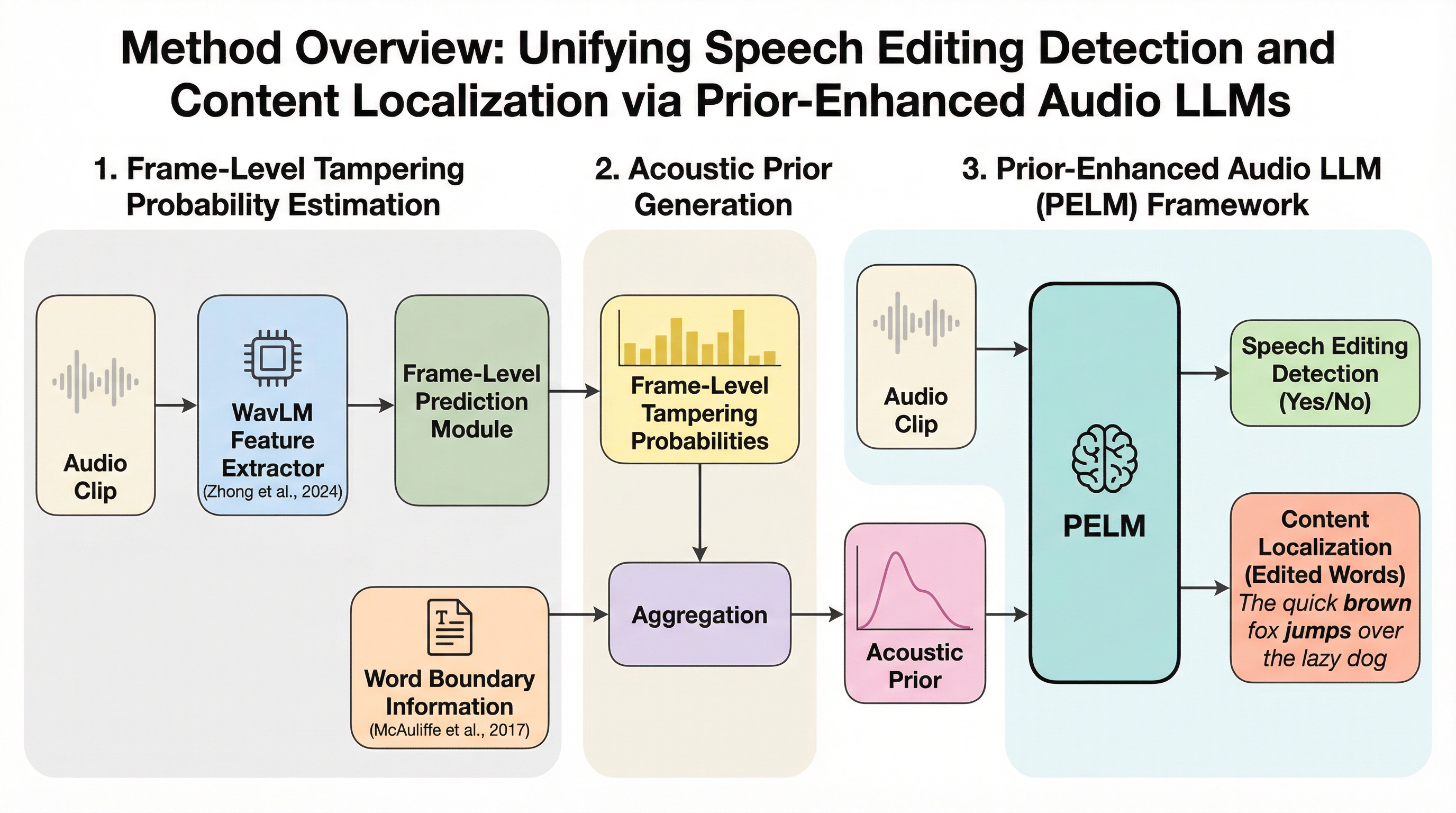
従来の音声編集検出は手動編集による継ぎ目の痕跡に依存していたが、最新のニューラル音声編集技術が生成する自然な音響遷移の検出は困難であったため、大規模言語モデルを活用して精密な意味改ざん論理を駆動し、複数の高度な生成手法を統合した高品質な二言語データセット「AiEdit」を構築した。
CAT(Convolutional Audio Transformer)は、音声信号の多様な時間・周波数構造を捉える「多解像度ブロック」と、外部モデルの知見を借りて学習を高速化する「表現正則化」を導入した新しい自己教師あり学習フレームワークである。
音声信号の理解における「単一の粒度によるモデル化の限界」と「ゼロからの学習に伴う膨大な計算コスト」という二つの主要な課題を解決するため、多解像度ブロックと表現正則化を導入した新しい自己教師あり学習フレームワーク「CAT」を提案した。
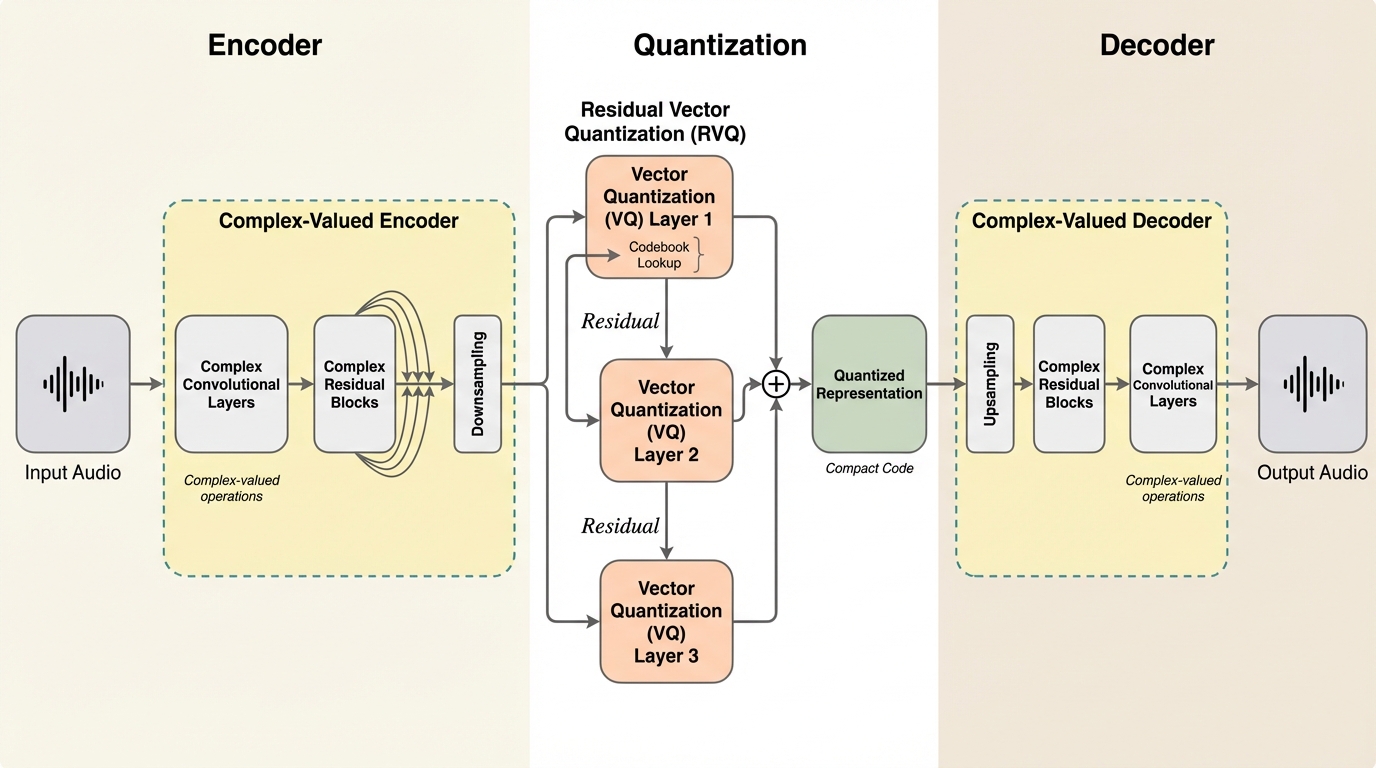
EuleroDecは、音声の振幅と位相の結合を保持するために、分析から量子化、合成までの全工程を複素数値で処理する初のエンドツーエンド音声コーデックである。 敵対的学習(GAN)や拡散モデルによる後処理を一切使用せず、従来のモデルと比較して学習時間を約95%削減しながら、未知のデータに対しても高い堅牢性と再現性を実現している。 24kHzの音声を6kbpsおよび12kbpsで符号化し、特に位相の正確さを測る指標や波形の忠実度において、従来の主要なニューラルコーデックを上回る最先端(SOTA)の性能を達成した。
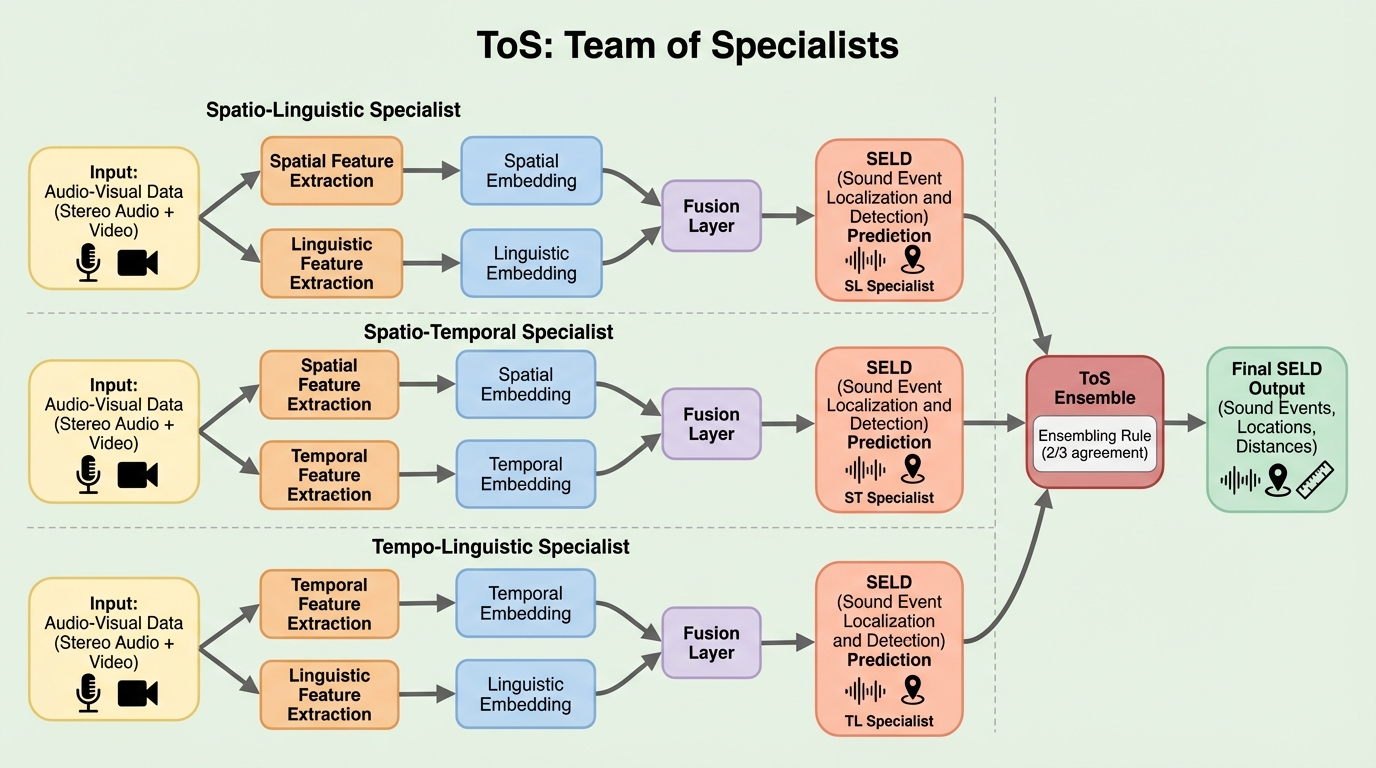
音響イベントの検出、定位、距離推定を同時に行う3D SELDは、意味(何が)、空間(どこで)、時間(いつ)という3つの次元を統合的に推論する必要があり、単一のモデルではこれら全ての要素を最適化することが困難という課題がありました。
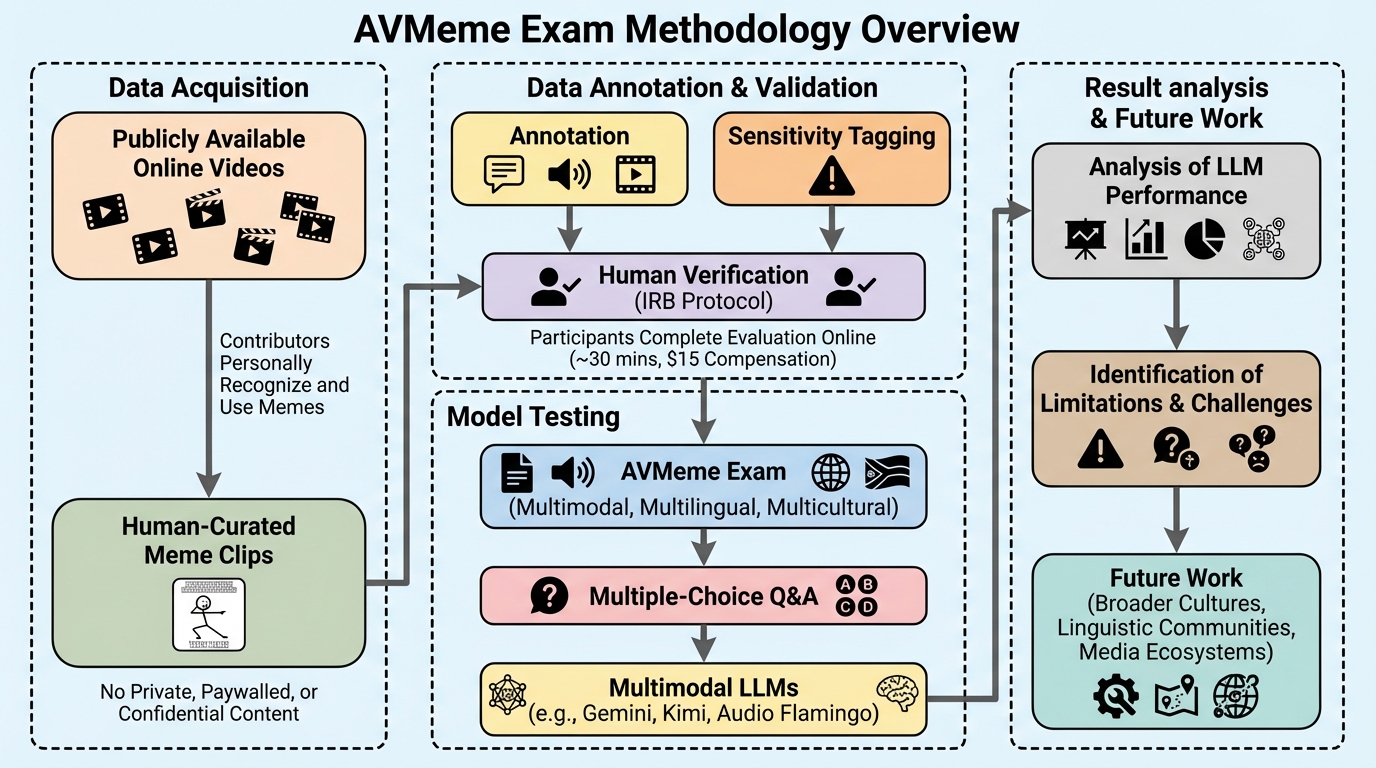
本研究では、インターネット上の音声・映像ミーム1,032件を厳選し、AIモデルが人間の文化的・文脈的な意味をどの程度理解できるかを測定する新しいベンチマーク「AVMeme Exam」を開発しました。
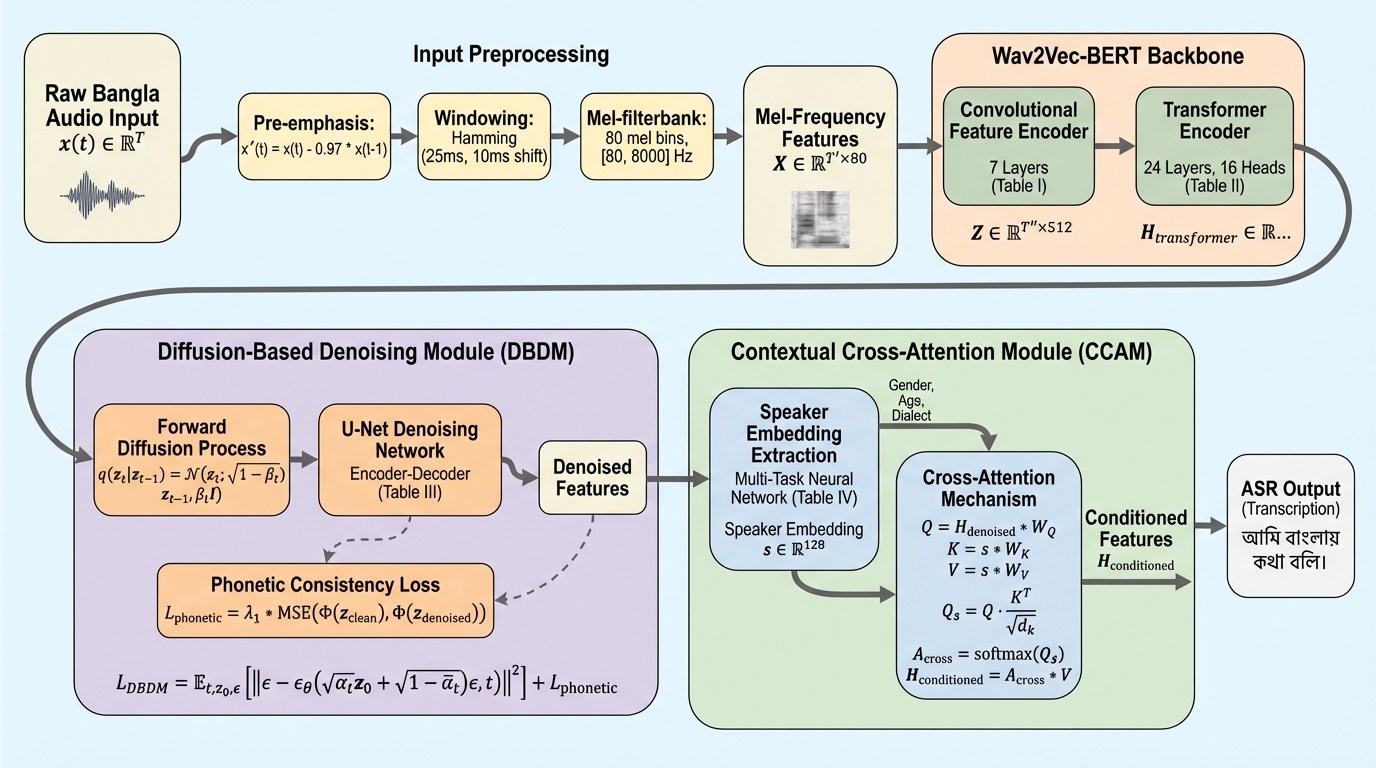
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
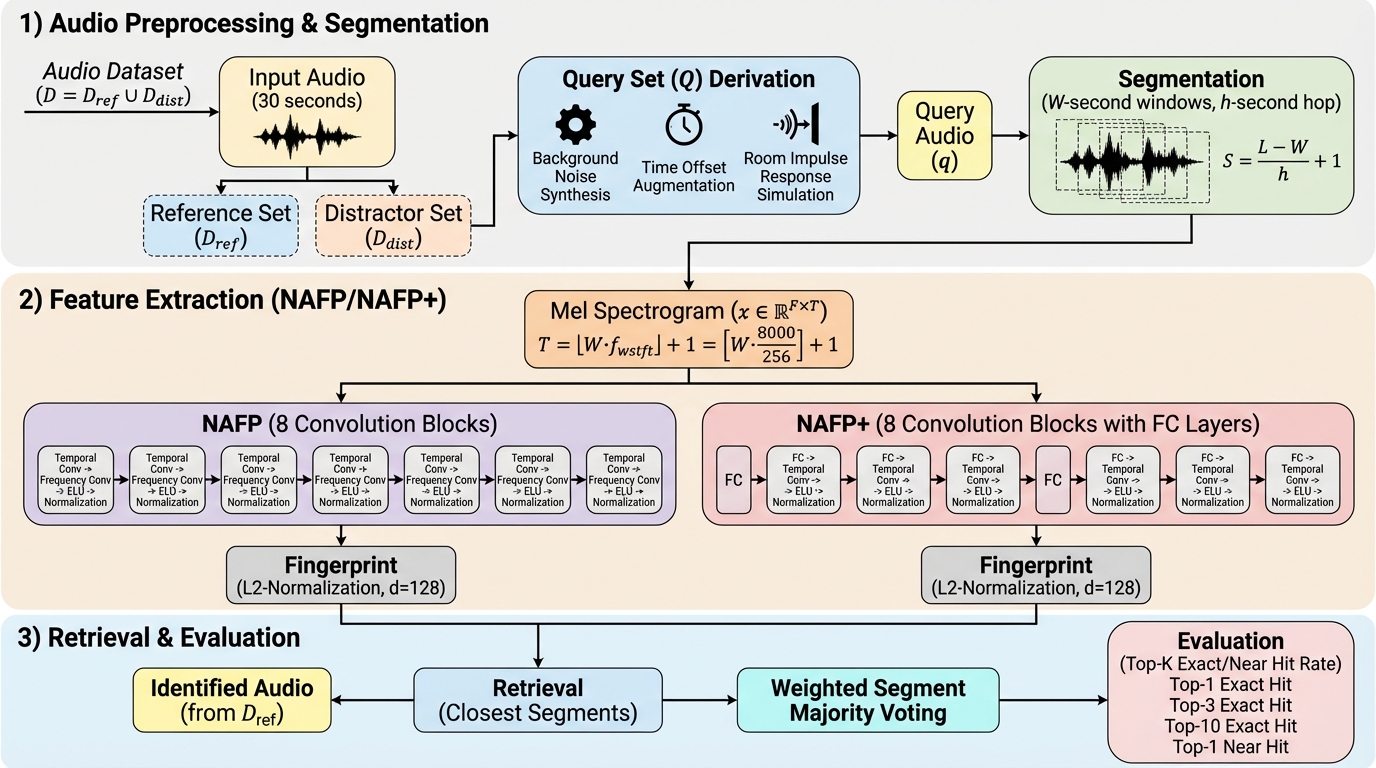
本研究は、音声指紋照合システムにおいて音声を切り出す際の「セグメント長」が照合精度に与える影響を、既存モデルを拡張したNAFP+を用いて詳細に調査したものです。 実験の結果、0.5秒という短いセグメント長が、特に3秒未満の短いクエリにおいて最も高い照合精度を達成し、クエリ長が4秒を超えると精度の向上が飽和する傾向が明らかになりました。 また、最適なセグメント長を提案する能力を大規模言語モデルで比較したところ、GPT-5-miniが実際の実験結果と最も合致する1秒前後の設定を一貫して推奨し、システム設計における高い信頼性を示しました。