EuleroDec:効率的かつ堅牢な音声符号化のための複素数値RVQ-VAE
EuleroDecは、音声の振幅と位相の結合を保持するために、分析から量子化、合成までの全工程を複素数値で処理する初のエンドツーエンド音声コーデックである。 敵対的学習(GAN)や拡散モデルによる後処理を一切使用せず、従来のモデルと比較して学習時間を約95%削減しながら、未知のデータに対しても高い堅牢性と再現性を実現している。 24kHzの音声を6kbpsおよび12kbpsで符号化し、特に位相の正確さを測る指標や波形の忠実度において、従来の主要なニューラルコーデックを上回る最先端(SOTA)の性能を達成した。
TL;DR(結論)
EuleroDecは、音声の振幅と位相の結合を保持するために、分析から量子化、合成までの全工程を複素数値で処理する初のエンドツーエンド音声コーデックである。 敵対的学習(GAN)や拡散モデルによる後処理を一切使用せず、従来のモデルと比較して学習時間を約95%削減しながら、未知のデータに対しても高い堅牢性と再現性を実現している。 24kHzの音声を6kbpsおよび12kbpsで符号化し、特に位相の正確さを測る指標や波形の忠実度において、従来の主要なニューラルコーデックを上回る最先端(SOTA)の性能を達成した。
なぜこの問題か
デジタル音楽の生成モデルやストリーミング、没入型メディアにおいて、音声コーデックはPCM音声を帯域幅に適したビットレートに圧縮する重要な役割を担っている。近年の研究では、短時間フーリエ変換(STFT)を用いたスペクトル領域での処理が主流となっているが、スペクトル領域では位相のモデリングが非常に困難であるという課題がある。位相情報は本質的に複素数値としての性質を持っているが、多くの既存のニューラルコーデックは位相情報を無視するか、あるいは実数と虚数の2つの独立したチャネルとして符号化している。このような手法では、振幅と位相の間に存在する固有の結合関係が無視されてしまい、結果として空間的な忠実度が制限されることになる。 この表現能力の不足を補うために、多くのモデルでは敵対的識別器(GAN)や拡散モデルを用いた後処理フィルタを導入している。しかし、これらの手法は学習の収束速度を低下させ、トレーニングの安定性を損なうという代償を伴う。また、特定のデータセットに過学習しやすく、未知の録音環境やノイズが含まれるデータ(アウトオブドメイン)に対して性能が著しく低下するという問題も指摘されている。…
核心:何を提案したのか
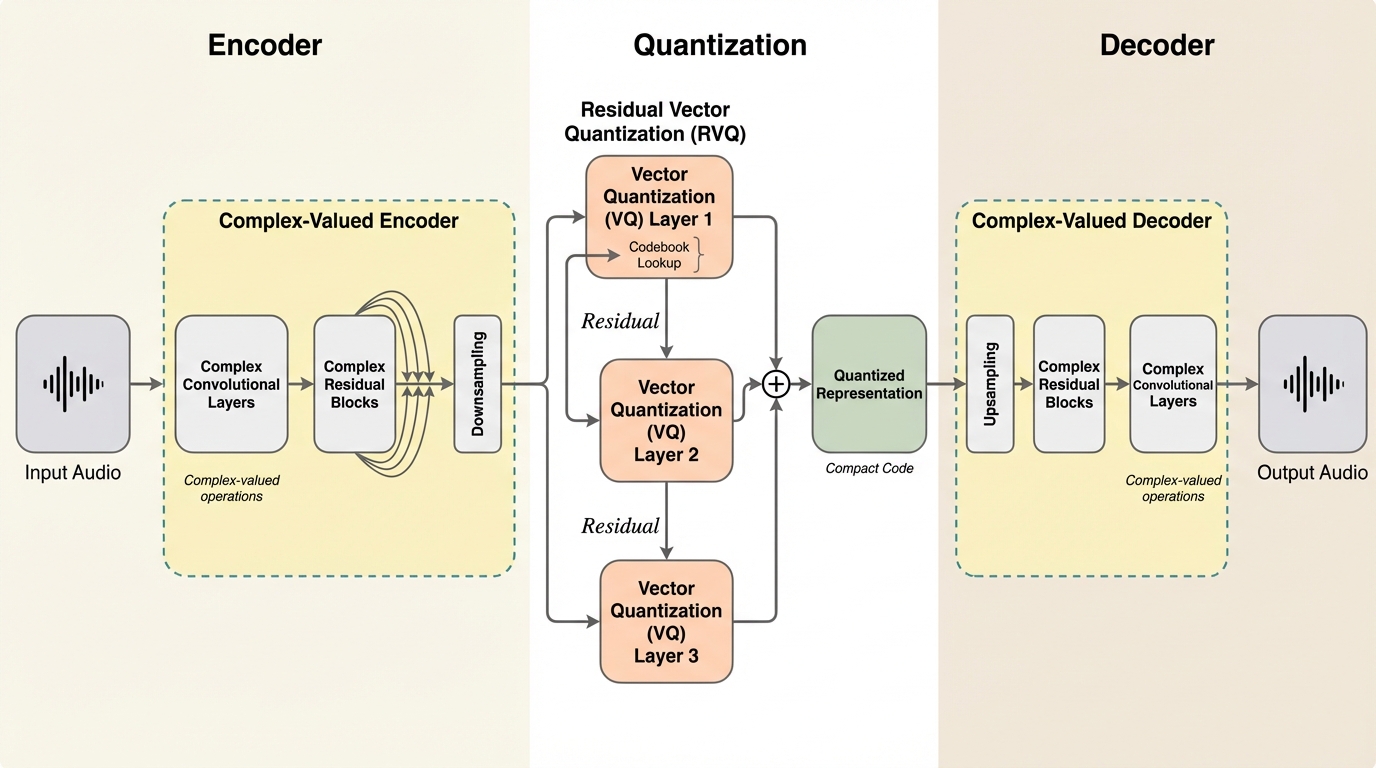
本研究では、EuleroDecと呼ばれる、完全にエンドツーエンドで複素数値を扱うRVQ-VAE(残留ベクトル量子化変分オートエンコーダ)音声コーデックを提案した。このモデルの最大の特徴は、波形の入力から再構成に至るまでの全パイプラインにおいて、複素数平面上の代数的構造を維持している点にある。具体的には、複素畳み込み、複素アテンション、そして2×2のホワイトニングを伴う複素正規化を統合し、STFTの幾何学的構造を直接処理できるように設計されている。これにより、従来のモデルで必要とされていた敵対的識別器や拡散ベースのポストフィルタを完全に排除することに成功した。 GANを使用しない設計により、学習の安定性が飛躍的に向上し、従来のベースラインモデルが数十万ステップの学習を必要とするのに対し、その10分の1以下の予算で同等以上の品質を達成している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related