音声編集の検出と改ざん箇所の特定を統合する事前知識強化型オーディオLLM
音声の一部を削除・挿入・置換する巧妙な編集を検出するため、大規模言語モデル(LLM)を活用して論理的な改ざんを施した高品質な二言語データセット「AiEdit」を構築しました。 このデータセットを基に、音声編集の検出と改ざん箇所の特定を「音声応答タスク」として統合し、単語レベルの音響的先験情報と一貫性を捉える損失関数を導入した新フレームワーク「PELM」を開発しました。 検証の結果、PELMは従来のオーディオLLMが陥りやすい誤検知や意味内容への偏重を克服し、既存手法を大幅に上回る精度で、継ぎ目のない高度な音声改ざんを識別・特定することに成功しました。
TL;DR(結論)
音声の一部を削除・挿入・置換する巧妙な編集を検出するため、大規模言語モデル(LLM)を活用して論理的な改ざんを施した高品質な二言語データセット「AiEdit」を構築しました。 このデータセットを基に、音声編集の検出と改ざん箇所の特定を「音声応答タスク」として統合し、単語レベルの音響的先験情報と一貫性を捉える損失関数を導入した新フレームワーク「PELM」を開発しました。 検証の結果、PELMは従来のオーディオLLMが陥りやすい誤検知や意味内容への偏重を克服し、既存手法を大幅に上回る精度で、継ぎ目のない高度な音声改ざんを識別・特定することに成功しました。
なぜこの問題か
近年の深層学習技術の飛躍的な進展により、極めて高精度な音声生成が可能になりましたが、これは個人のプライバシー侵害や社会的な安全保障に対する深刻な脅威となっています。音声の偽造技術は、音声全体をゼロから合成する「完全合成」と、既存の音声の特定部分のみを操作する「音声編集」の二種類に大別されます。前者は発話全体を生成するため信号の全体的な分布が大きく変化しますが、後者は特定の単語や短いフレーズのみを削除、追加、または修正することで、話者の声の特徴や背景情報を維持したまま意味を反転させます。このような局所的な操作は非常に隠蔽性が高く、フェイクニュースの拡散や世論操作、金融詐欺などの場面で極めて破壊的な影響を及ぼす可能性があります。 従来の音声編集技術は、音声区間検出に基づくセグメント化と手動の繋ぎ合わせに頼るルールベースの手法が主流でした。このプロセスでは、偽造された領域と元の背景との間に音響的な境界の痕跡が残りやすく、従来の検出モデルはこうした低レベルの信号の乱れを捉えることに依存していました。しかし、最新の「エンドツーエンド神経音声編集」技術は、意味的な指示に基づいて周囲の韻律や文脈と高度に一致する音声を生成します。…
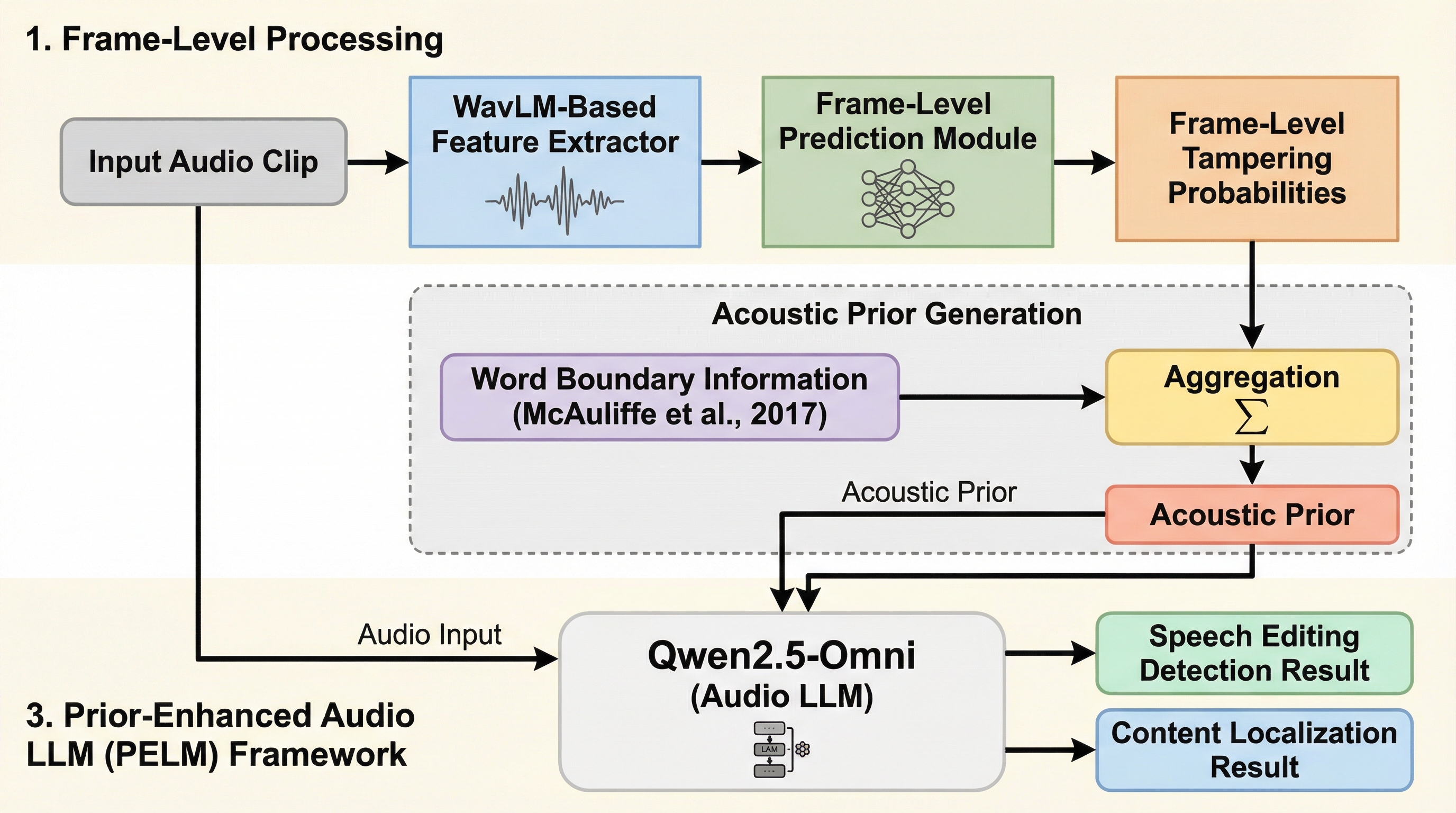
核心:何を提案したのか
本研究では、上述の課題に対処するために二つの大きな貢献を行いました。第一に、高品質な音声編集データセットである「AiEdit」を構築しました。このデータセットは、大規模言語モデル(LLM)を意味エンジンとして活用し、文脈に即した正確なテキスト編集(挿入、削除、修正)を駆動します。さらに、SSR、VoiceCraft、FluentSpeech、Ming-UniAudioといった複数の最先端の神経音声編集技術を統合してデータを合成することで、従来のデータセットに欠けていた「高品質かつ論理的な改ざん音声」のギャップを埋めています。これにより、単なるノイズの検出ではなく、意味的な整合性と音響的な自然さを兼ね備えた高度な偽造に対する評価が可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related