合成音声品質評価のためのフレシェ音声距離の理解
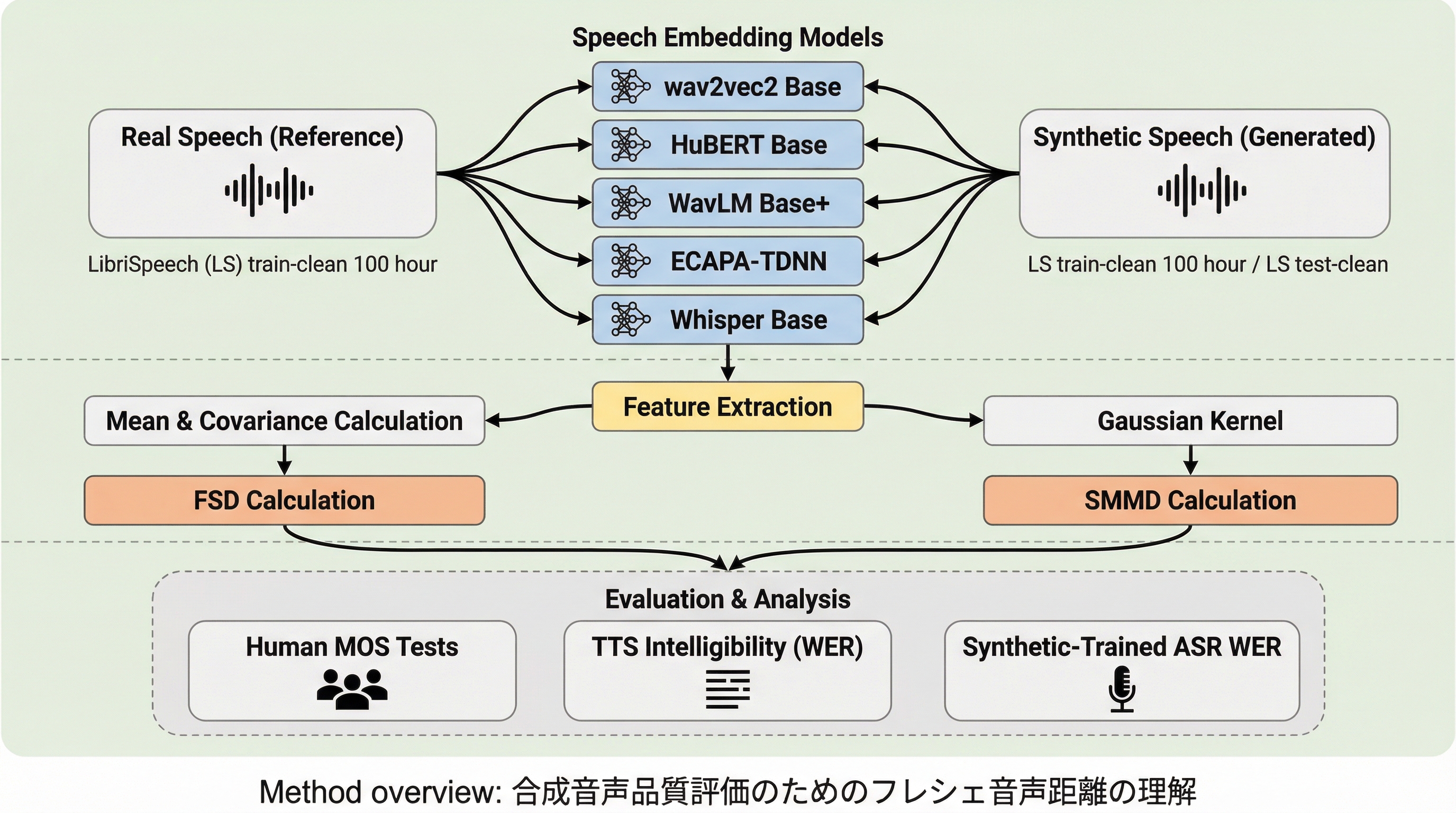
合成音声の品質を客観的に評価するため、画像分野のFIDを応用したフレシェ音声距離(FSD)と、正規分布の仮定を必要としない新指標である音声最大平均不一致(SMMD)の有効性を、WavLMやWhisperを含む5種類の音声埋め込みモデルを用いて体系的に検証しました。
TL;DR(結論)
合成音声の品質を客観的に評価するため、画像分野のFIDを応用したフレシェ音声距離(FSD)と、正規分布の仮定を必要としない新指標である音声最大平均不一致(SMMD)の有効性を、WavLMやWhisperを含む5種類の音声埋め込みモデルを用いて体系的に検証しました。 実験の結果、94,000時間の学習データを持つWavLM Base+の特徴量を用いた評価が、ノイズ耐性やサンプル効率の面で最も安定しており、人間の主観評価(MOS)や合成音声で学習したASRモデルの性能(synthetic-WER)とも良好な相関を示すことが明らかになりました。 FSDやSMMDは人間による評価を完全に代替するものではありませんが、大規模なデータ評価や直接的な聴取が困難な開発初期段階において、わずか3時間程度の音声データで収束するコスト効率の高い補完的指標として、TTSモデルの品質追跡に極めて有用であると結論付けられました。
なぜこの問題か
テキスト読み上げ(TTS)技術の急速な進歩により、極めて高品質な合成音声の生成が可能になりましたが、その品質を客観的かつ正確に評価する手法の確立は依然として重要な課題となっています。従来、音声の明瞭性を測る指標として単語誤り率(WER)が広く用いられてきましたが、これは音声の自然さや全体的な品質を必ずしも反映するものではありません。特に、未知の話者やノイズを含むプロンプトから生成された場合、自動音声認識(ASR)モデルが多様なスタイルに苦戦してWERが上昇することがありますが、これは必ずしも合成音声自体の品質が低いことを意味するわけではありません。人間による平均意見評点(MOS)は評価の黄金律とされていますが、主観的で個人の偏見に左右されやすく、多大なコストと時間を要するため、大規模な比較や研究間での再現性を確保することが困難です。また、MOSや既存の明瞭性指標では、合成音声と実音声の分布の類似性を定量的に測定することができません。このような背景から、参照データセットとの距離を測定するフレシェ距離(FD)が注目され、画像(FID)や音楽(FAD)の分野で活用されてきました。…
核心:何を提案したのか
本研究では、合成音声の品質評価指標としてのフレシェ音声距離(FSD)を体系的に理解し、その信頼性を高めるための包括的な評価を行いました。具体的には、wav2vec2 Base(960時間学習)、HuBERT Base(960時間学習)、WavLM Base+(94,000時間学習)、Whisper Base(680,000時間学習)、ECAPA-TDNN(2,500時間学習)という、学習データ量や目的が異なる5種類の最新音声埋め込みモデルを比較対象として選定しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related