表現正則化を用いた畳み込みオーディオトランスフォーマーによる音声理解の向上
CAT(Convolutional Audio Transformer)は、音声信号の多様な時間・周波数構造を捉える「多解像度ブロック」と、外部モデルの知見を借りて学習を高速化する「表現正則化」を導入した新しい自己教師あり学習フレームワークである。
TL;DR(結論)
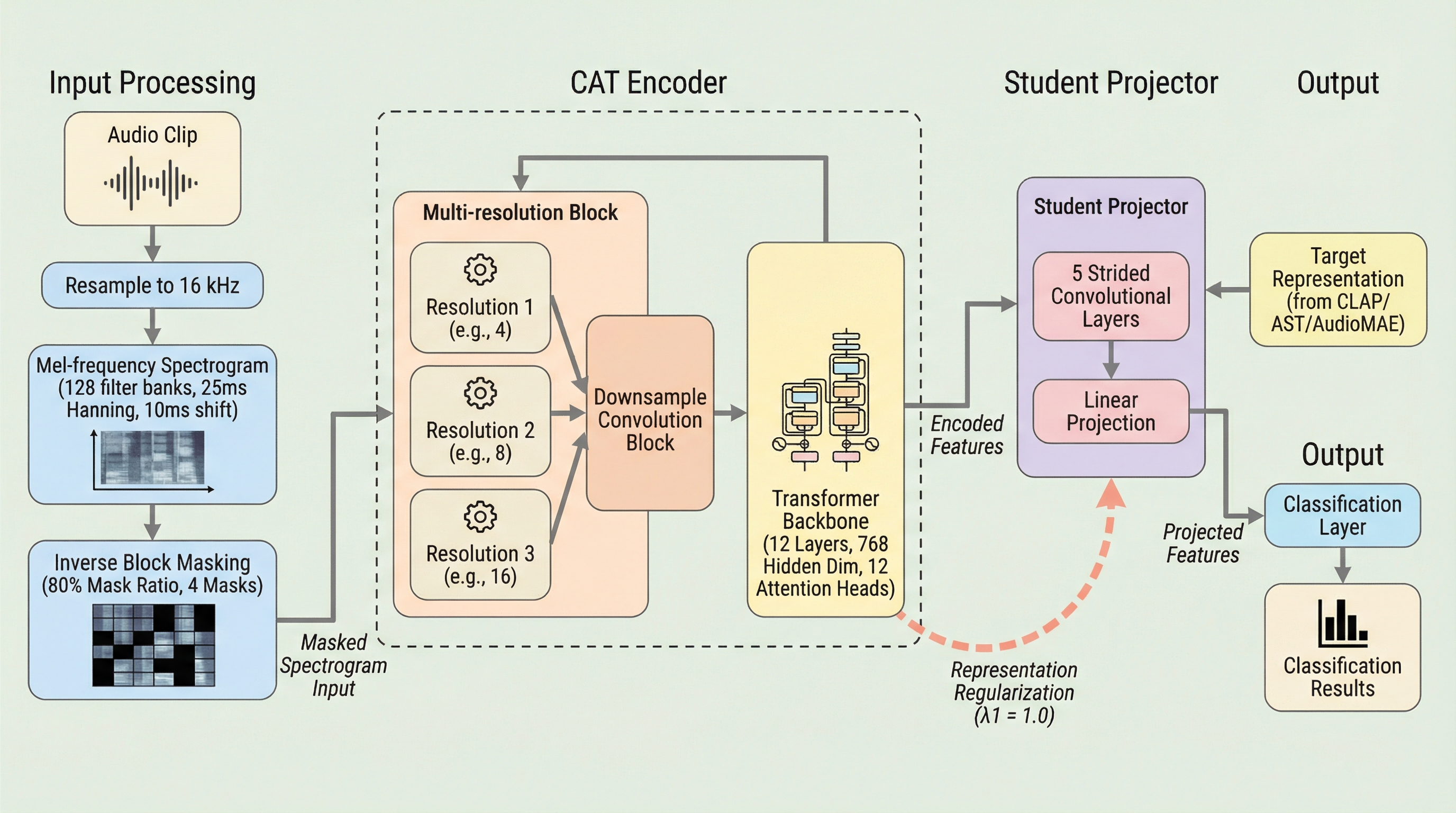
CAT(Convolutional Audio Transformer)は、音声信号の多様な時間・周波数構造を捉える「多解像度ブロック」と、外部モデルの知見を借りて学習を高速化する「表現正則化」を導入した新しい自己教師あり学習フレームワークである。 従来のブートストラップ方式が抱えていた「単一の解像度しか扱えない」という限界と「ゼロからの学習による膨大な計算コスト」という2つの課題を、階層的な特徴抽出と事前学習済みエンコーダによる意味的なガイドによって解決した。 実験の結果、AudioSet等の主要なベンチマークで世界最高水準(SOTA)の精度を達成し、既存手法と比較して最大5倍の速さで学習が収束することを実証しており、効率的かつ高精度な音声理解モデルとしての有効性が示された。
なぜこの問題か
音声信号は、非常に複雑かつ多層的な構造を持っている。例えば、一瞬で消えるような微細な音の質感(テクスチャ)から、数秒間にわたって展開される意味的な文脈(コンテキスト)まで、時間的にも周波数的にも多様なスケールで情報が構成されている。しかし、これまでの音声分野における自己教師あり学習(SSL)手法の多くは、音声を固定された単一の粒度(解像度)で処理する傾向があった。これにより、音声が本来持っている多層的な構造を十分に捉えきれず、情報の損失が生じるという問題があった。また、現在の主流であるブートストラップ方式の学習、すなわち教師モデルの出力を生徒モデルが予測する手法には、効率性の面で大きな課題がある。この方式では、ランダムに初期化された状態からモデル内部の整合性のみを頼りに表現を構築していくため、高品質な表現を獲得するまでに膨大な計算リソースと長いトレーニング時間を必要とする。既存のSOTAモデルであるdata2vecやEAT、ATSTなども、この「ゼロからのブートストラップ」に伴う収束の遅さに直面していた。…
核心:何を提案したのか
本研究では、上述の課題を解決するために「Convolutional Audio Transformer(CAT)」という統合フレームワークを提案した。このフレームワークの核心は、大きく分けて2つの革新的なコンポーネントにある。第一に、音声の粒度の問題を解決するために「Multi-resolution Block(多解像度ブロック)」を導入した。これは、従来の標準的なパッチ埋め込み(Patch Embedding)を置き換えるものである。このブロックは、階層的な畳み込みレイヤーを利用して、異なる時間・周波数スケールで特徴を抽出し、それらを統合する。これにより、モデルは音声信号に含まれる微細な音のディテールから、広域的な意味情報までを同時に扱うことが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related