オーディオ理解のための表現正則化された畳み込みオーディオトランスフォーマー
音声信号の理解における「単一の粒度によるモデル化の限界」と「ゼロからの学習に伴う膨大な計算コスト」という二つの主要な課題を解決するため、多解像度ブロックと表現正則化を導入した新しい自己教師あり学習フレームワーク「CAT」を提案した。
TL;DR(結論)
音声信号の理解における「単一の粒度によるモデル化の限界」と「ゼロからの学習に伴う膨大な計算コスト」という二つの主要な課題を解決するため、多解像度ブロックと表現正則化を導入した新しい自己教師あり学習フレームワーク「CAT」を提案した。 多解像度ブロックによって音声の階層的な時間・周波数構造を効果的に捉え、さらに外部の事前学習済みエンコーダ(CLAP等)の知見を学習のガイドとして活用する表現正則化を導入することで、表現の質を向上させつつ学習の収束速度を劇的に高めることに成功した。 実験の結果、AudioSetを含む主要なベンチマークで従来の最高性能(SOTA)を更新し、特にAudioSet 20kデータセットにおいては、既存手法と比較して5倍の学習速度を実現しながら極めて高い精度を達成しており、効率的かつ高性能な音声AIの新たな基準を提示している。
なぜこの問題か
音声信号の理解において、ラベルのない膨大なデータから有用な特徴を抽出する自己教師あり学習(SSL)は大きな成果を上げているが、既存のブートストラップ型手法には解決すべき二つの大きな障壁が存在している。第一の課題は、音声信号が本来持っている「階層的な性質」が従来のモデルでは十分に考慮されていない点である。音声イベントは、一瞬の音響的なテクスチャから、数秒間にわたる長期的な意味的コンテキストまで、極めて多様な時間的およびスペクトル的なスケールにまたがって存在している。しかし、従来の多くの手法は固定された単一の粒度、すなわち一定のパッチサイズで音声を処理するため、これらの多スケールな構造を柔軟かつ詳細に捉えることが難しく、結果としてモデルの表現能力に限界が生じていた。 第二の課題は、モデルを完全にゼロの状態からトレーニングすることの非効率性である。教師ネットワークと生徒ネットワークの間の内部的な一貫性のみを頼りに学習を進めるブートストラップ方式では、ランダムな初期状態から意味のある高品質な表現を構築するために、膨大な計算リソースと長期間のトレーニングが必要となる。…
核心:何を提案したのか
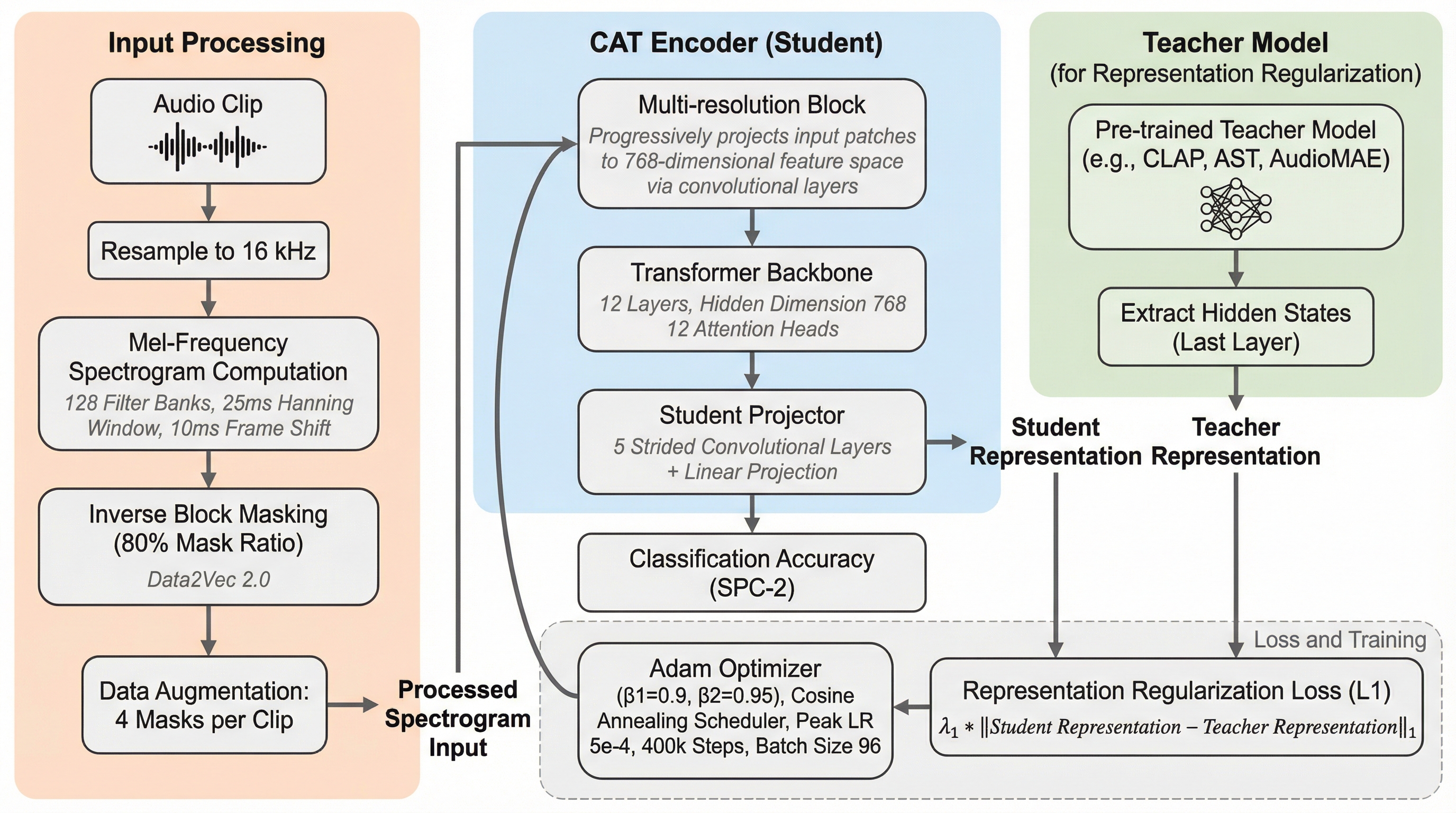
本研究では、音声表現学習の粒度と効率を同時に改善する統一フレームワークとして「Convolutional Audio Transformer(CAT)」を提案した。この提案の核心は、構造的な工夫と学習目的関数の革新という二つの柱にある。まず、構造面では、標準的な単一層のパッチ埋め込みに代わり、階層的な畳み込み層を利用した「多解像度ブロック(Multi-resolution Block)」を導入した。これにより、異なる時間および周波数スケールで特徴を抽出し、それらを統合することで、音声信号の多スケールな特性に適合した特徴抽出が可能になる。これは、微細な音の細部から全体的な音の文脈までを一つのモデルでシームレスに扱うための工夫である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related