事前知識で強化された音声LLMによる音声編集検出と内容特定の統合
従来の音声編集検出は手動編集による継ぎ目の痕跡に依存していたが、最新のニューラル音声編集技術が生成する自然な音響遷移の検出は困難であったため、大規模言語モデルを活用して精密な意味改ざん論理を駆動し、複数の高度な生成手法を統合した高品質な二言語データセット「AiEdit」を構築した。
TL;DR(結論)
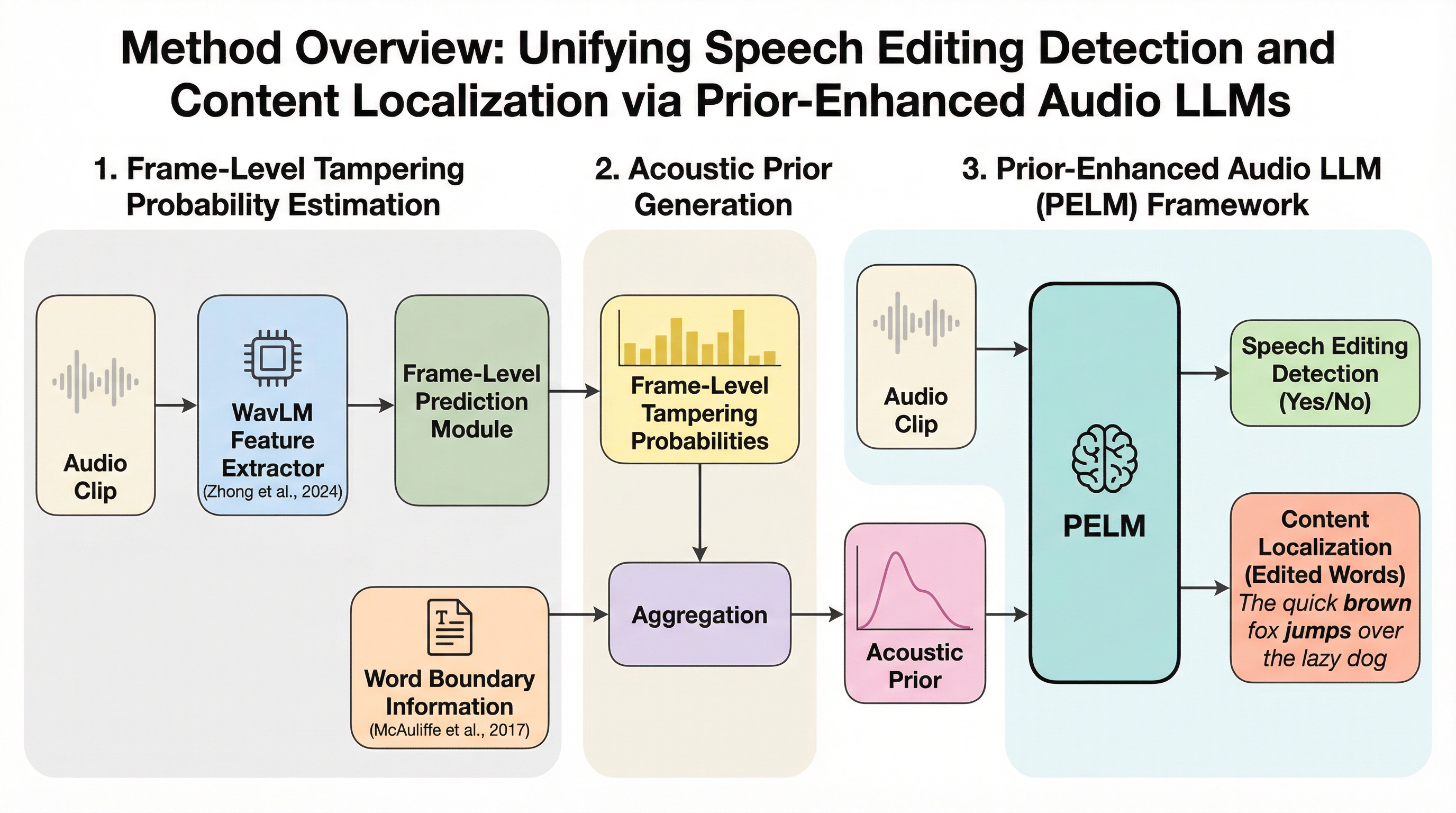
従来の音声編集検出は手動編集による継ぎ目の痕跡に依存していたが、最新のニューラル音声編集技術が生成する自然な音響遷移の検出は困難であったため、大規模言語モデルを活用して精密な意味改ざん論理を駆動し、複数の高度な生成手法を統合した高品質な二言語データセット「AiEdit」を構築した。 この課題に対し、音声編集の検出と改ざん箇所の特定をオーディオ質問回答タスクとして定式化し、これらを統一的に処理する初の大型モデルフレームワーク「PELM」を提案し、単語レベルの確率的事前知識の導入と音響的一貫性知覚損失の設計によって、既存モデルの課題であった偽造バイアスと意味優先バイアスを抑制した。 広範な検証の結果、提案手法であるPELMは既存の最高水準の手法を大幅に上回る性能を示し、HumanEditデータセットで0.57%、AiEditデータセットの特定タスクで9.28%という極めて低い等価エラー率(EER)を達成し、局所的な音響異常を正確に捉える能力を証明した。
なぜこの問題か
近年の大規模データと深層学習技術の進展により、高忠実度な音声生成が普及しているが、これは個人のプライバシーや社会の安全に対する深刻な脅威となっている。音声のディープフェイクの脅威は、大きく分けて「完全合成」と「セグメントレベルの音声編集」の二つに分類される。完全合成は、テキスト読み上げ(TTS)や声質変換(VC)を用いて発話全体を生成し、信号の全体的な分布を変化させるものである。これに対し、音声編集は特定のセグメントのみに対して追加、削除、修正を行い、極めて短い情報の操作によって意味を反転させる手法である。この手法は、元の話者の声の特徴や背景の文脈の大部分を保持するため、局所的な操作が非常に隠蔽されており、偽ニュースの拡散や世論操作、金融詐欺などのシナリオにおいて大きな破壊力を持つ。 既存の音声編集技術には二つのパラダイムが存在する。第一のパラダイムは、音声活動検出(VAD)に基づくセグメンテーション、セグメント合成、および手動の継ぎ合わせで構成される伝統的なルールベースの音響編集である。このプロセスは累積的なエラーが発生しやすく、偽造領域と元の背景の間に顕著な音響的境界の痕跡を残す傾向がある。…
核心:何を提案したのか
本研究では、上述の課題を解決するために、まず高品質な大規模二言語データセットである「AiEdit」を構築した。このデータセットは、大規模言語モデル(LLM)を意味エンジンとして活用し、精密なテキスト編集(挿入、削除、修正)を駆動する。そして、複数の最先端のニューラル音声編集技術を統合してサンプルを生成することで、従来のデータセットに見られた音響的な不自然さや意味的な一貫性の欠如という欠点を克服している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related