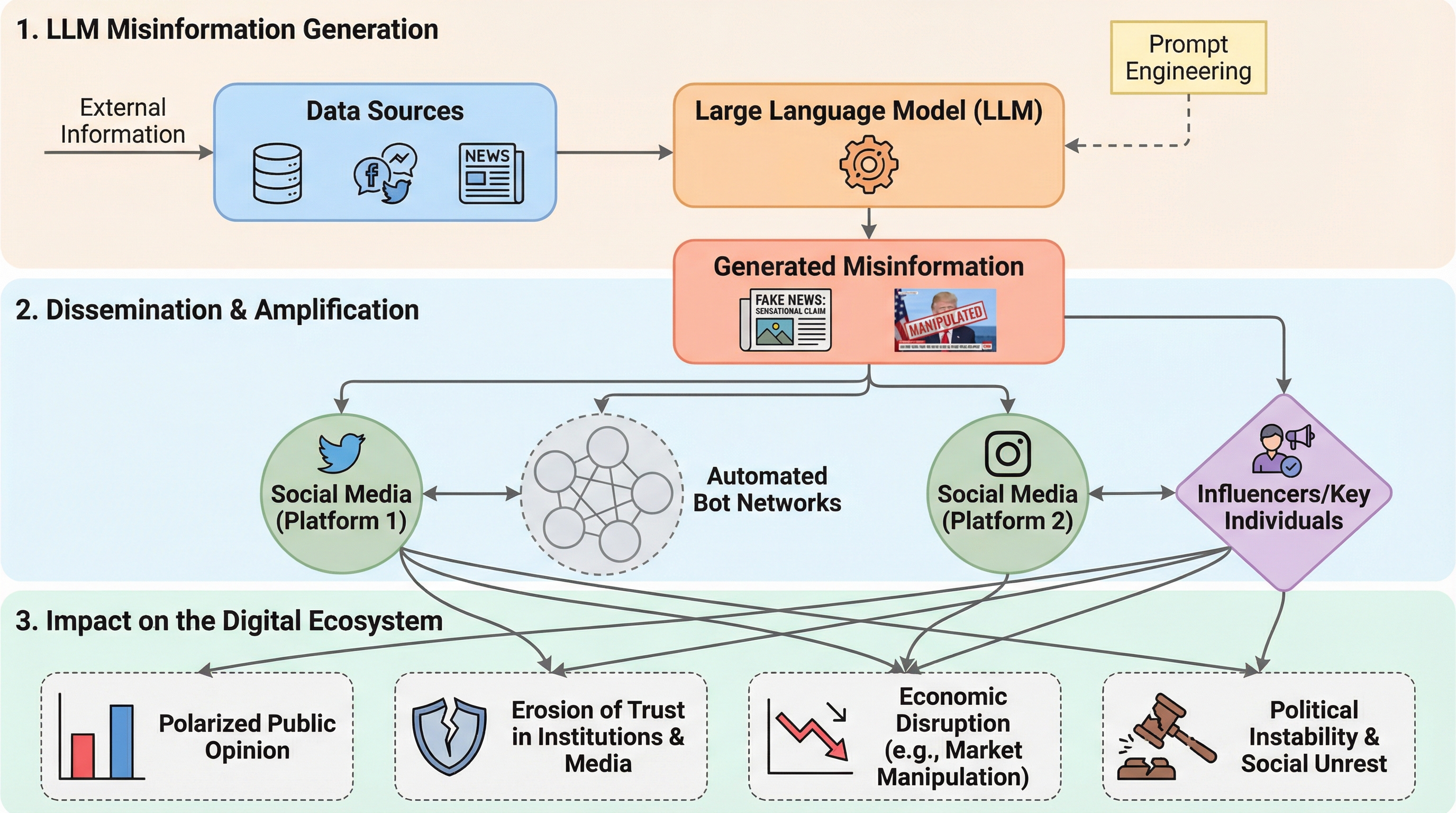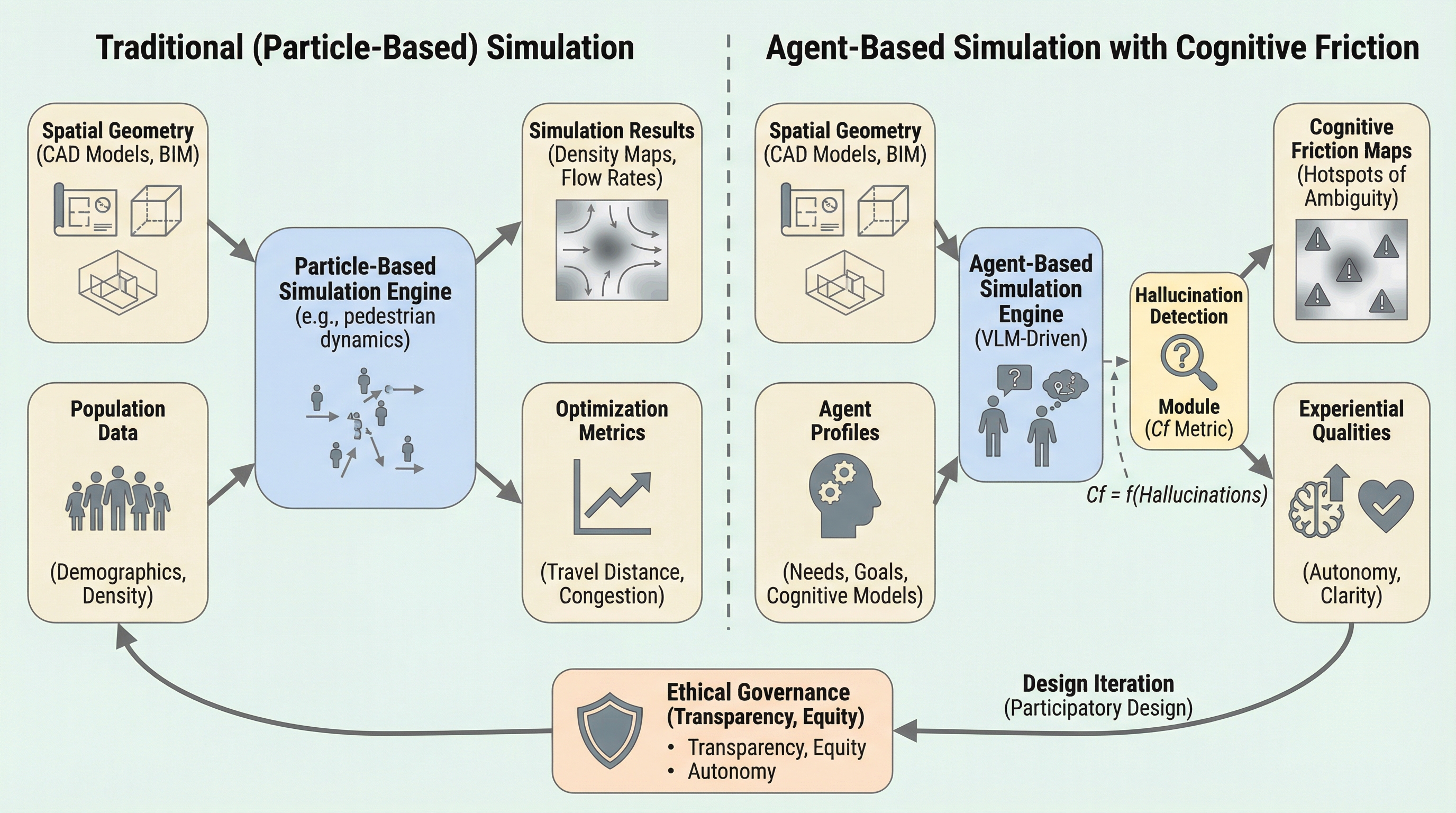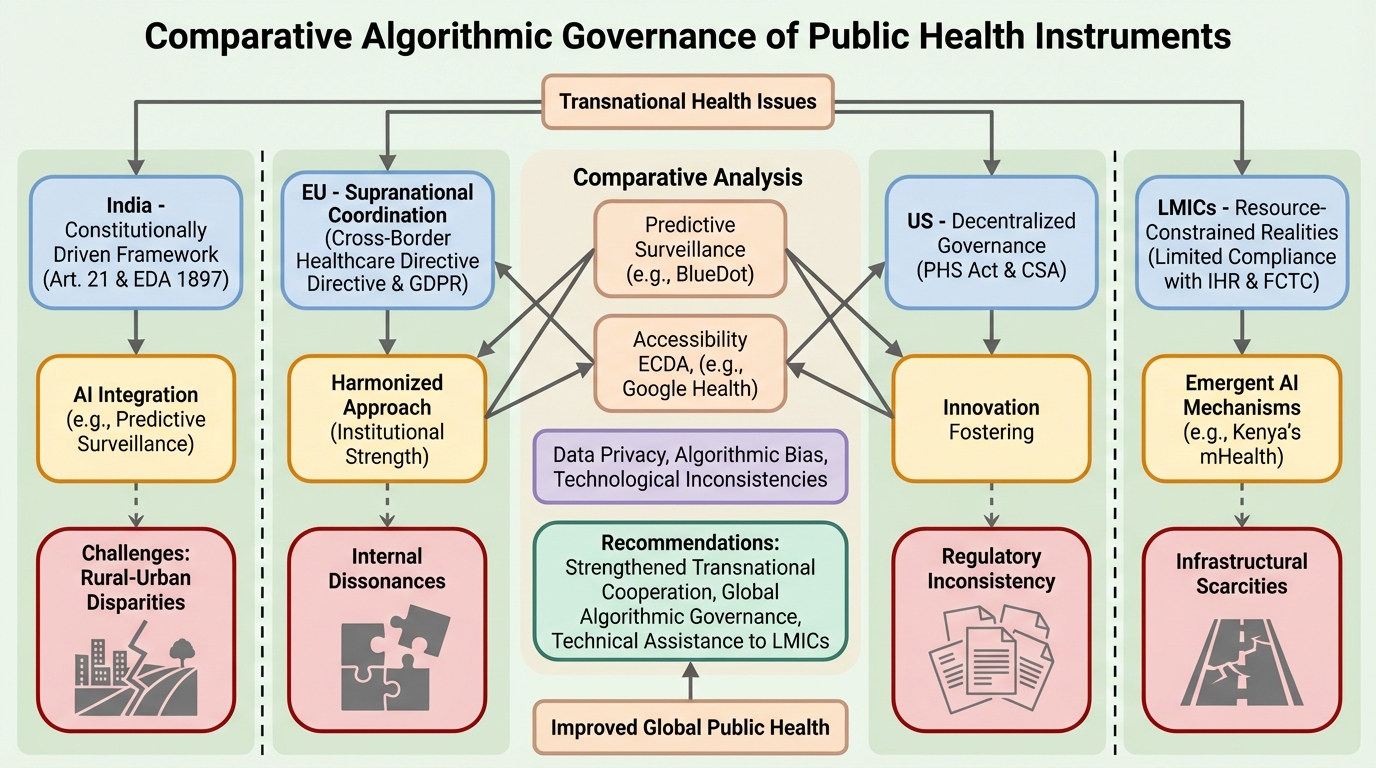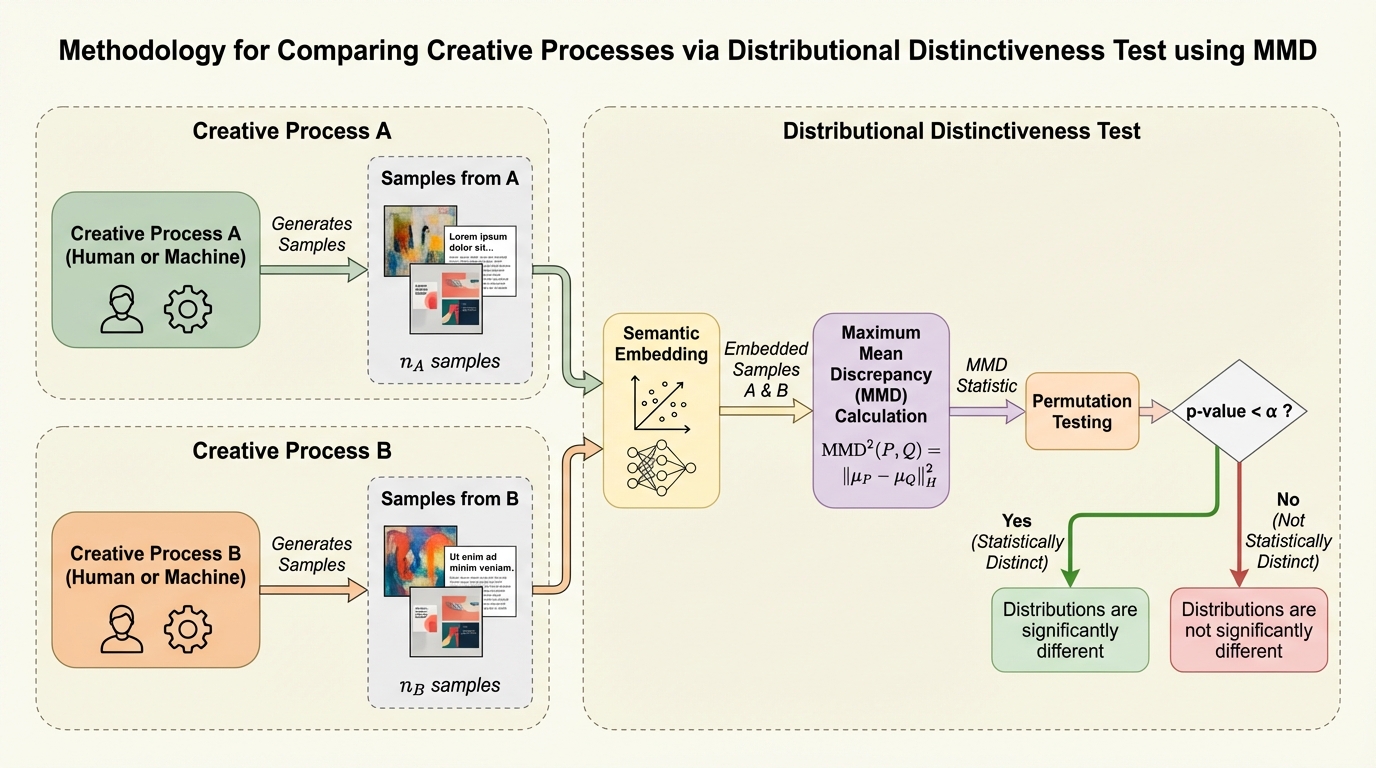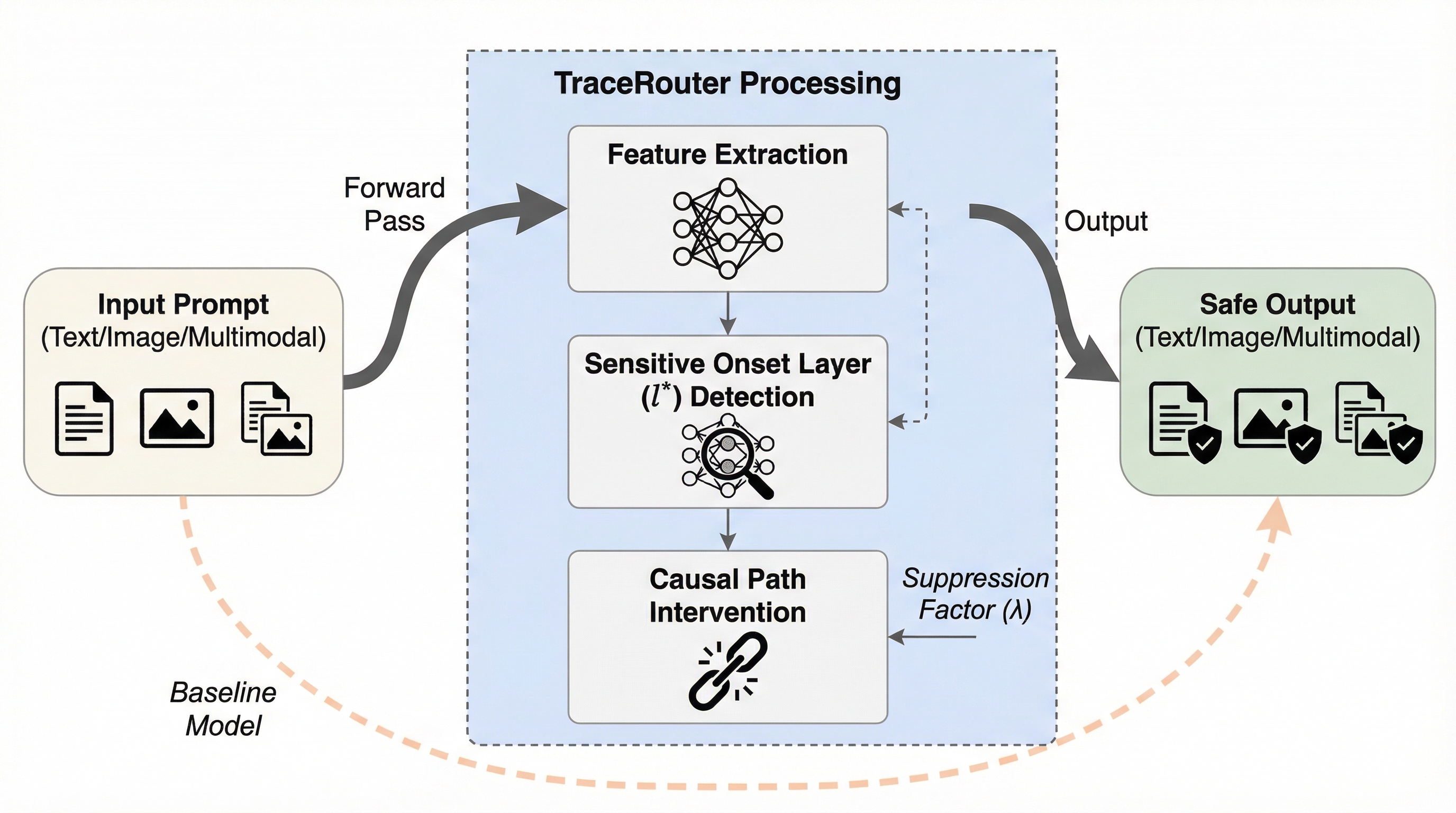
TraceRouter: 大規模基盤モデルのための経路レベル介入による堅牢な安全性
TraceRouterは、大規模基盤モデルにおける有害情報の伝播を、個別のニューロン単位ではなく複数の層にまたがる「経路(パス)」のレベルで特定し遮断する新しい安全フレームワークである。 従来の防御手法が依存していた局所性仮説の限界を打破し、注意力の分散分析とスパース自己符号化器(SAE)を用いて有害なセマンティクスの回路を精密に特定し、特徴影響スコア(FIS)に基づき因果的な伝播を物理的に断ち切る。 画像生成、言語生成、マルチモーダルの各分野で検証され、モデル本来の生成品質や汎用的な推論能力を維持したまま、敵対的な脱獄攻撃に対しても極めて高い防御成功率と堅牢性を実現することに成功した。