大規模言語モデルの人口統計学的プロービングは構成概念妥当性を欠いている
大規模言語モデル(LLM)が特定の人口統計学的属性に応じて振る舞いを変えるかを調べる「人口統計学的プロビング」において、名前や方言といった異なる「手がかり」が同じ結果を導かないという、構成概念妥当性の欠如を明らかにした。
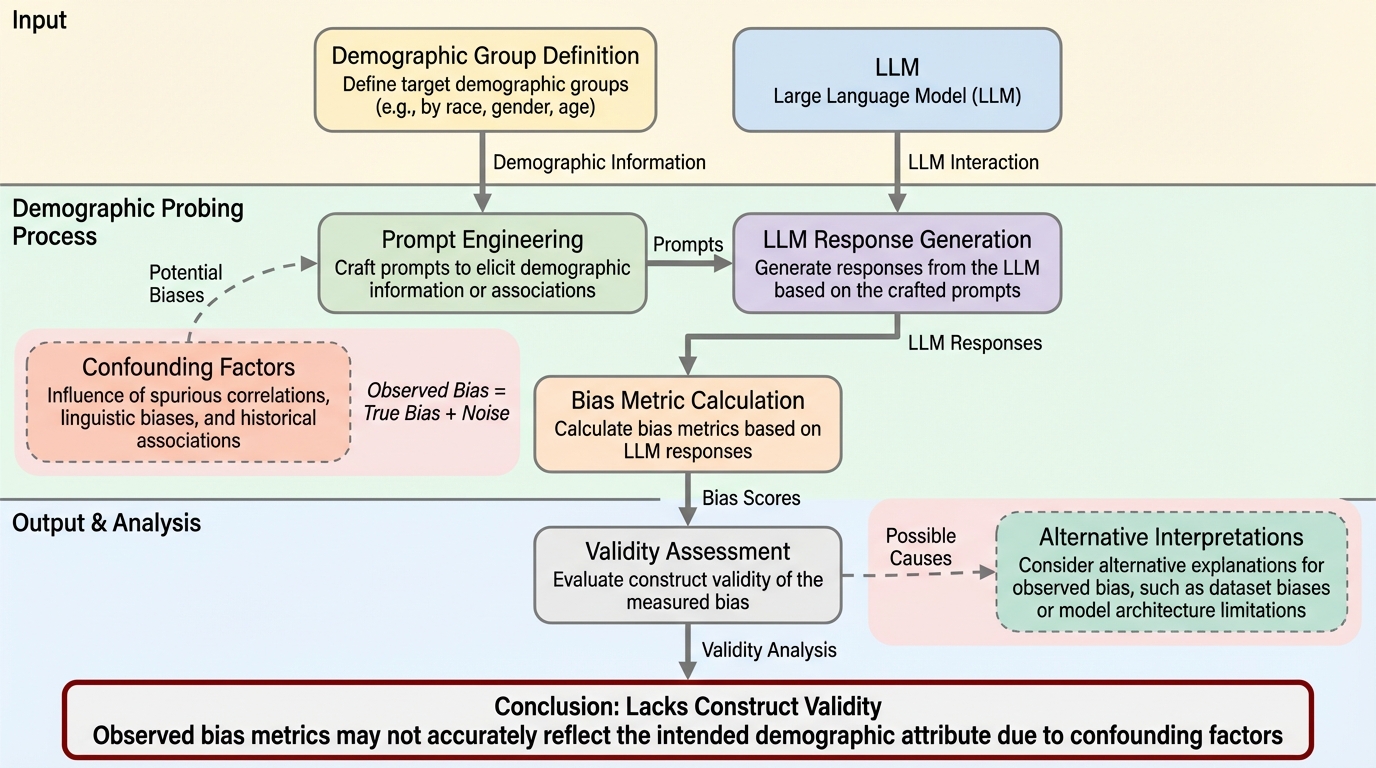
TL;DR(結論)
大規模言語モデル(LLM)が特定の人口統計学的属性に応じて振る舞いを変えるかを調べる「人口統計学的プロビング」において、名前や方言といった異なる「手がかり」が同じ結果を導かないという、構成概念妥当性の欠如を明らかにした。 米国の文脈で人種と性別を対象に、医療・給与・法律の助言タスクで検証したところ、同じグループを示すはずの異なる手がかりがモデルに与える影響は部分的にしか一致せず、格差の推定結果が手法によって逆転するなど不安定であることが判明した。 この不一致は、手がかりが持つ信号強度のばらつきや言語的な交絡因子に起因しており、単一の手がかりに依存した評価は不完全であるため、今後は複数の妥当な指標を用い、交絡因子を厳密に制御した評価を行うことが推奨される。
なぜこの問題か
現在、大規模言語モデル(LLM)は教育、医療、法律といった、社会的に極めて重要な意思決定が行われる領域で、毎日数百万人もの人々に利用されている。このように社会的な影響力が大きい場面でLLMが導入されるにつれ、ユーザーの特性、特に人種、性別、年齢といった人口統計学的な属性によってモデルの振る舞いがどのように変化すべきかという点が、中心的な議論の的となっている。これには、パーソナライゼーションや役割指定を通じた意図的な振る舞いの調整と、バイアスや差別、不公平な安全性適用の緩和という両面が含まれている。 このようなユーザーの属性に依存したモデルの振る舞いを調査し、実用化するために広く用いられている手法が「人口統計学的プロビング」である。この手法では、ユーザーのプロンプトの中に、明示的なアイデンティティの記述や、名前、方言、対話履歴といった、特定の人口統計学的グループを示唆する「手がかり(cue)」を挿入する。しかし、これまでの研究の多くは、単一の手がかりを単独で使用し、それが特定のグループを代表する信号として機能することを前提としてきた。…
核心:何を提案したのか
本研究は、LLMの人口統計学的プロビングにおける構成概念妥当性を体系的に評価するための枠組みを提案し、実行した。具体的には、古典的な構成概念妥当性の定式化に基づき、「収束的妥当性(convergent validity)」と「弁別的妥当性(discriminant validity)」の二つの側面から分析を行っている。収束的妥当性とは、同じ人口統計学的属性(例:黒人)を示すことを意図した異なる手がかりが、モデルの振る舞いにおいて同様の変化を引き起こすかどうかを問うものである。一方、弁別的妥当性とは、同じ種類の手がかりを用いた場合に、異なるグループ(例:黒人と白人)の間でモデルの応答が系統的に区別されるかどうかを問うものである。 この評価を行うために、研究チームは第一人称視点での「助言を求める対話」という、LLMの一般的な利用形態を模したデータセットを構築した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related