イグボ語の発音記号復元に対するコーパスベースのアプローチ
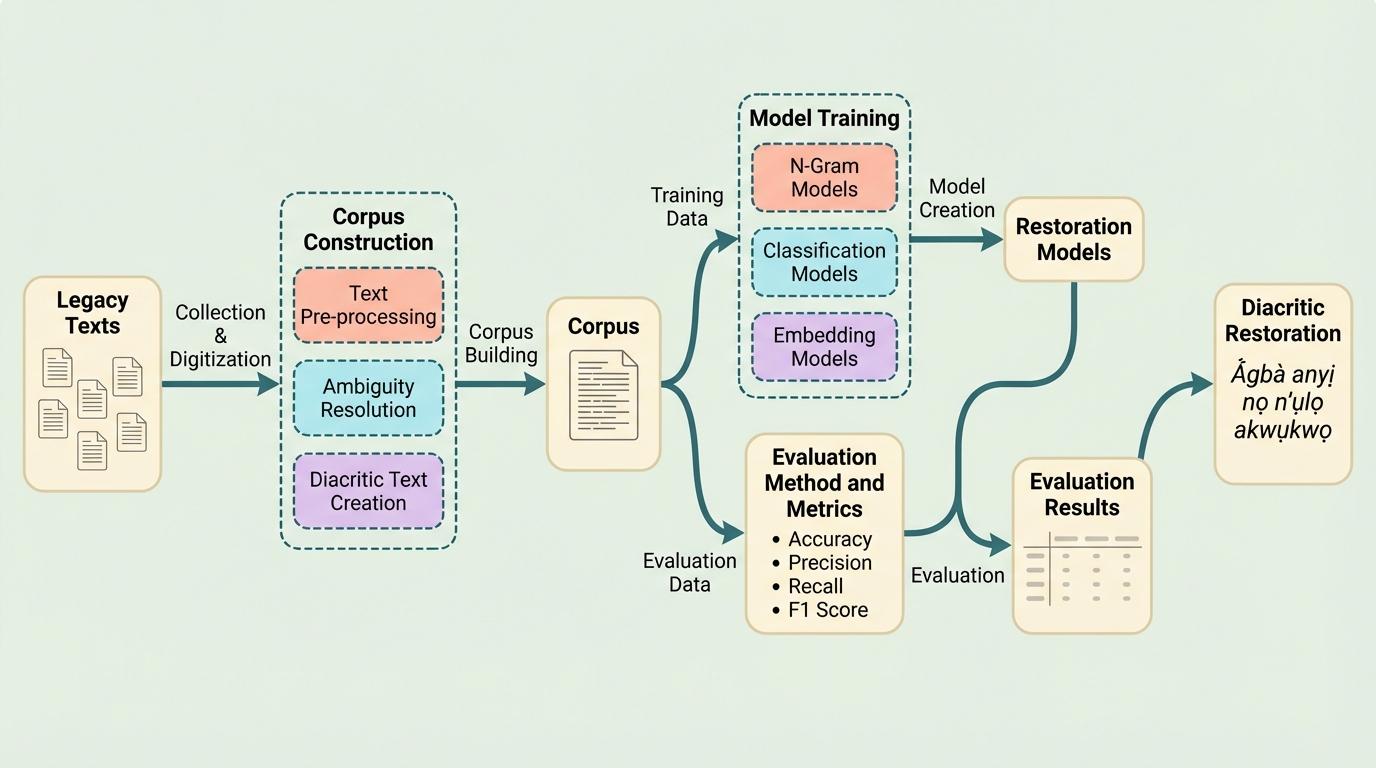
イグボ語は自然言語処理のリソースが極めて乏しい言語であり、デジタルテキストにおいて意味や声を区別する発音記号が省略されることで生じる深刻な曖昧性が、言語理解の大きな障壁となっている。本研究では、この問題を解決するために、n-gramモデル、機械学習による分類モデル、および他言語からの投影を利用した単語埋め込みモデルという3つの主要な技術的アプローチを提案し、データセット生成のための柔軟なフレームワークを構築した。検証の結果、提案されたすべての手法が単語の出現頻度のみに基づく基準値を大幅に上回る精度を記録し、特に文脈情報を活用する手法が、検索エンジンや機械翻訳などの言語インフラを改善する上で極めて有効であることを実証した。
TL;DR(結論)
イグボ語は自然言語処理のリソースが極めて乏しい言語であり、デジタルテキストにおいて意味や声を区別する発音記号が省略されることで生じる深刻な曖昧性が、言語理解の大きな障壁となっている。本研究では、この問題を解決するために、n-gramモデル、機械学習による分類モデル、および他言語からの投影を利用した単語埋め込みモデルという3つの主要な技術的アプローチを提案し、データセット生成のための柔軟なフレームワークを構築した。検証の結果、提案されたすべての手法が単語の出現頻度のみに基づく基準値を大幅に上回る精度を記録し、特に文脈情報を活用する手法が、検索エンジンや機械翻訳などの言語インフラを改善する上で極めて有効であることを実証した。
なぜこの問題か
世界に存在する約7000の言語のうち、95%以上は自然言語処理(NLP)のためのデータやツールが不足している「低リソース言語」に分類される。ナイジェリアを中心に話されるイグボ語もその一つであり、英語や日本語のような潤沢なリソースを持つ言語に比べて、計算機による言語理解の技術が著しく遅れている。イグボ語の書記体系において、発音記号(ダイアクリティカル・マーク)は単なる補助記号ではなく、語彙の意味、文法的な役割、そして声調を区別するために不可欠な要素である。しかし、デジタル環境での入力の難しさや歴史的な背景から、これらの記号はしばしば省略されて記述される。記号が欠落すると、一つの綴りが複数の異なる意味を持つ「曖昧性」が生じ、人間にとっても計算機にとっても正確な解釈が困難になる。 この問題は、情報の検索精度の低下、機械翻訳の誤り、電子出版の阻害、さらには言語学習ツールの開発を妨げる要因となっている。例えば、同じ綴りの単語であっても、発音記号の有無や種類によって「卵」「布」「泣く」といった全く異なる意味に分かれる場合がある。このような曖昧性は、文脈を考慮しない単純な処理では解決できない。…
核心:何を提案したのか
本研究の核心は、イグボ語の発音記号復元(IDR)を効率的に行うための包括的なフレームワークと、3つの異なる技術的アプローチを提案したことにある。まず、研究の基盤として、発音記号が欠落したテキストから学習・評価用のデータセットを柔軟に生成するための汎用的なフレームワークを開発した。その上で、第一のアプローチとして「標準的なn-gramモデル」を提案した。これは、ターゲットとなる単語の直前に出現する単語の連鎖を予測の手がかりとし、最も確率の高い記号のバリエーションを選択する手法である。これにより、単語の並びという統計的な性質を利用した復元が可能になる。 第二のアプローチは「分類モデル」である。ここでは、ターゲット単語の前後数単語を含むコンテキスト・ウィンドウを特徴量として抽出し、多様な機械学習アルゴリズムを用いて正しい記号を予測するクラス分類問題として定義した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related