ICON:効率的なマルチターン・ジェイルブレイク攻撃のための意図とコンテキストの結合
大規模言語モデル(LLM)において、悪意のある意図がそれと意味的に整合する文脈(コンテキスト)と組み合わさった際に安全制約が大幅に緩和される「意図・文脈結合(Intent-Context Coupling)」という現象を解明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)において、悪意のある意図がそれと意味的に整合する文脈(コンテキスト)と組み合わさった際に安全制約が大幅に緩和される「意図・文脈結合(Intent-Context Coupling)」という現象を解明しました。
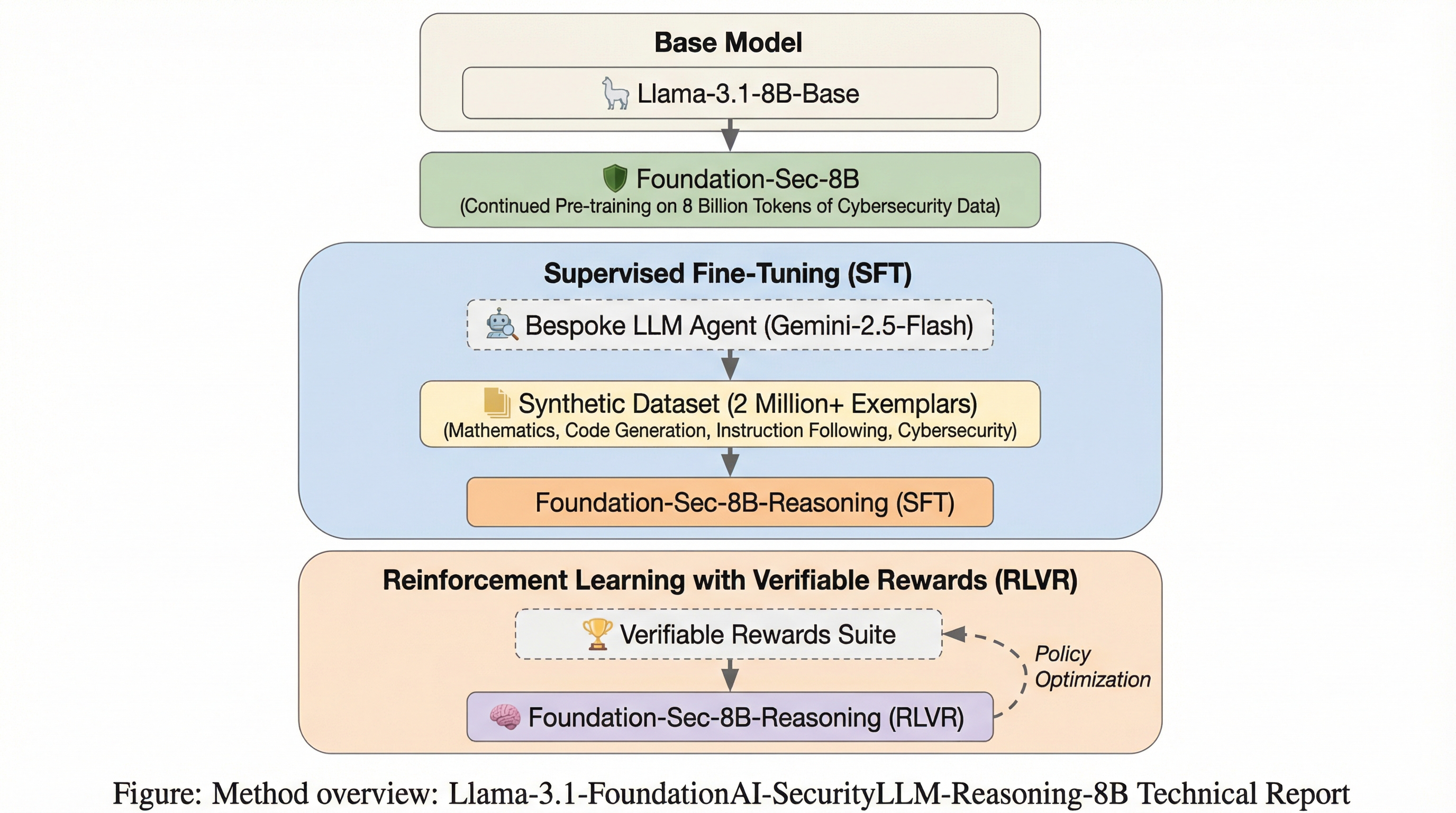
Foundation-Sec-8B-Reasoningは、Llama-3.1-8Bを基盤として開発された、サイバーセキュリティ分野で初となるオープンソースのネイティブ推論モデルであり、複雑なセキュリティ分析において「思考」プロセスを明示する能力を備えている。
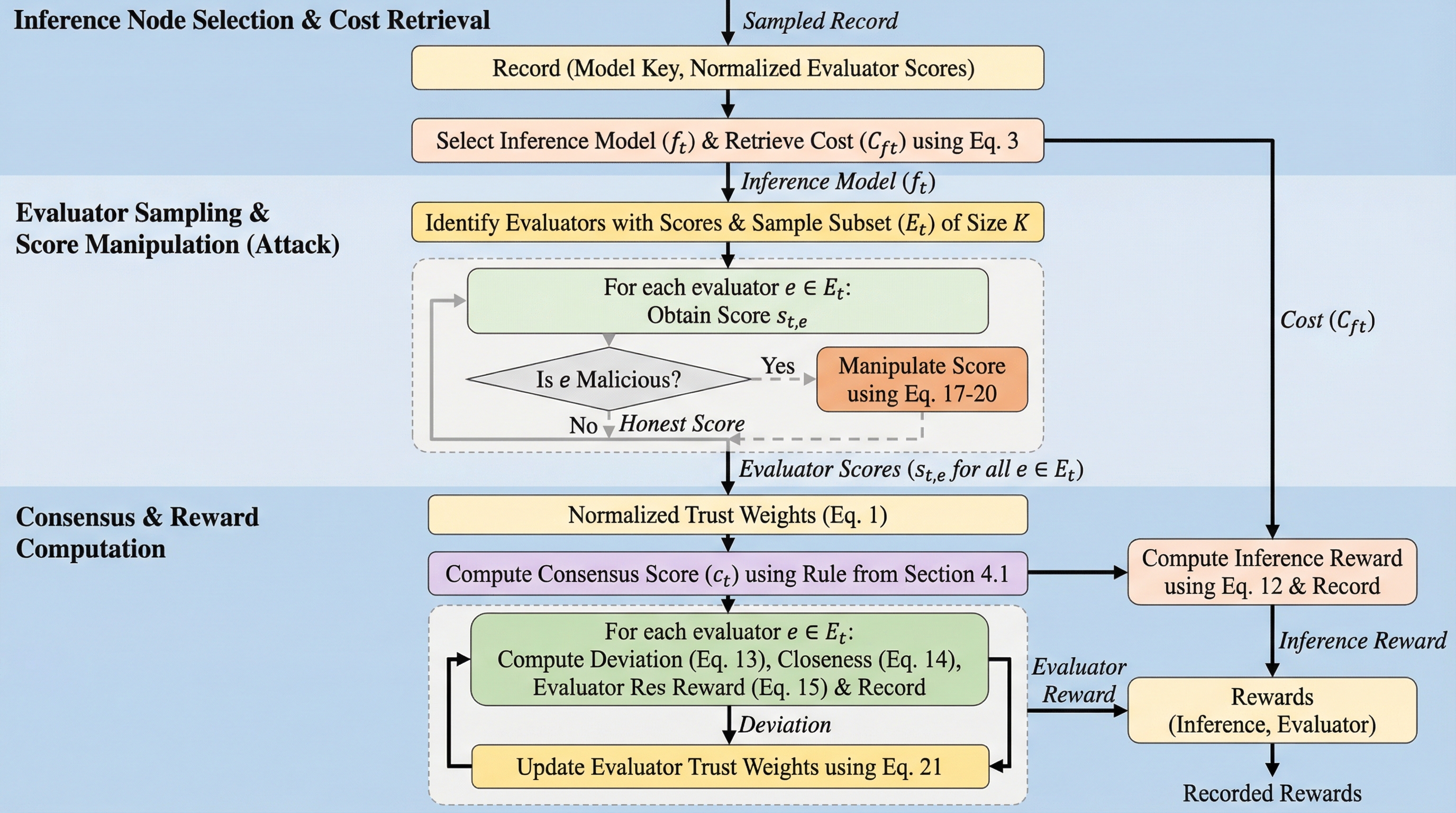
分散型LLM推論ネットワークにおいて、悪意ある評価者によるスコア操作や評価者の不均一性が合意形成を歪める課題に対し、中央値やトリム平均を用いた堅牢な集計ルールと、過去の乖離に基づく適応的な信頼重み付けメカニズムを導入した。
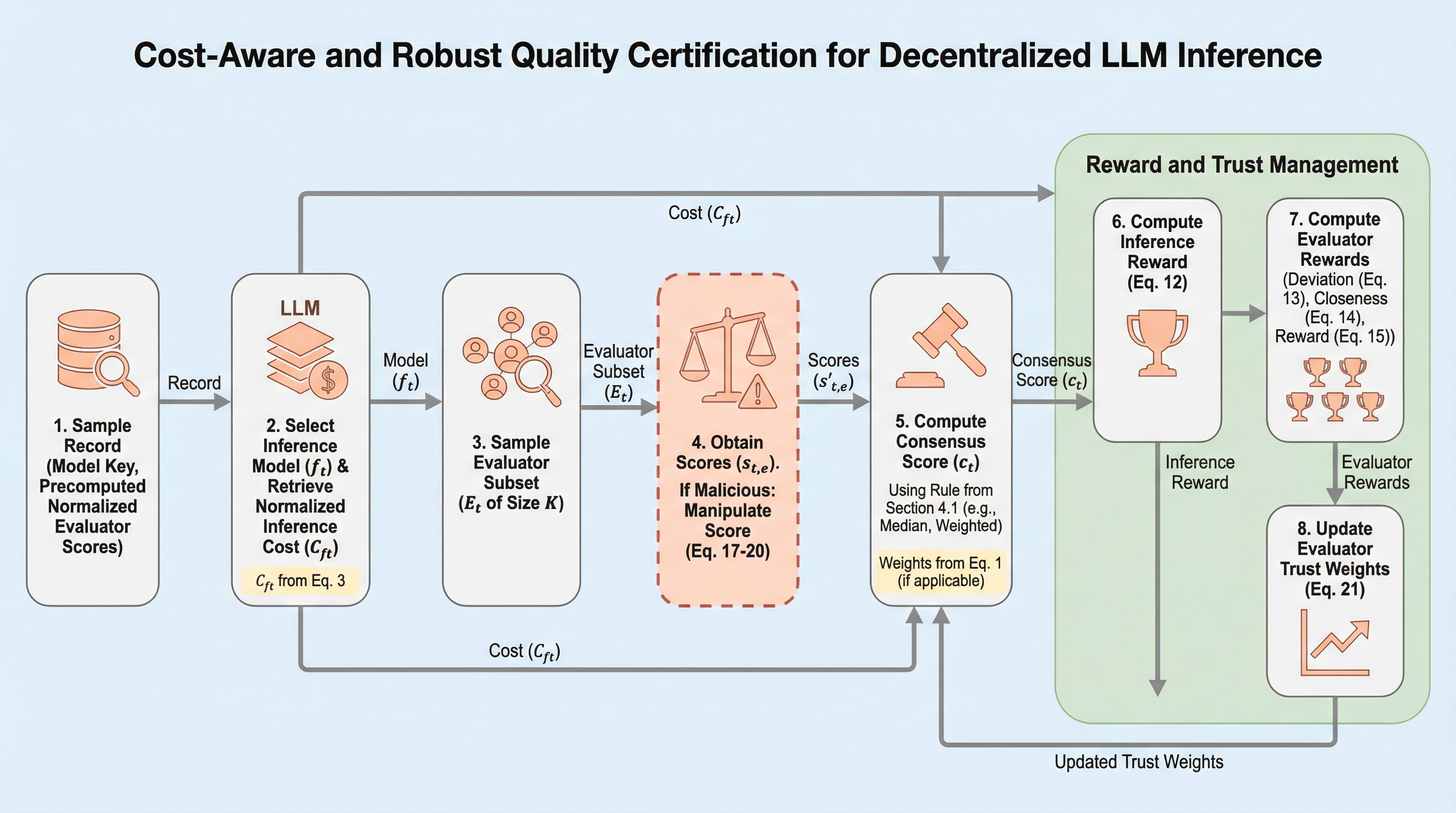
分散型LLM推論において、軽量な評価ノードを用いて出力品質を保証する「Proof of Quality(PoQ)」を拡張し、悪意あるノードによるスコア操作に耐性を持つコスト考慮型の仕組みを提案している。
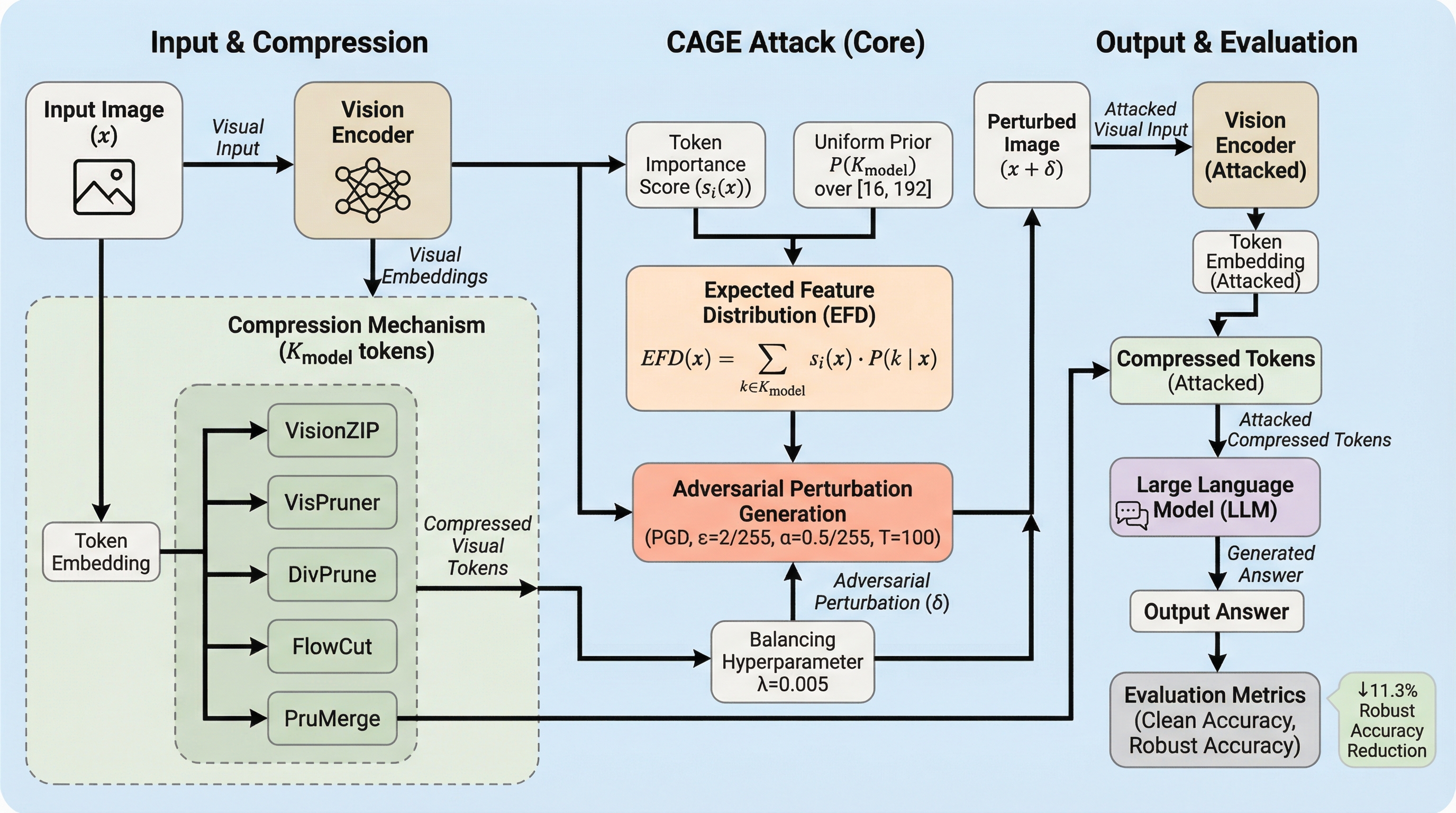
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。
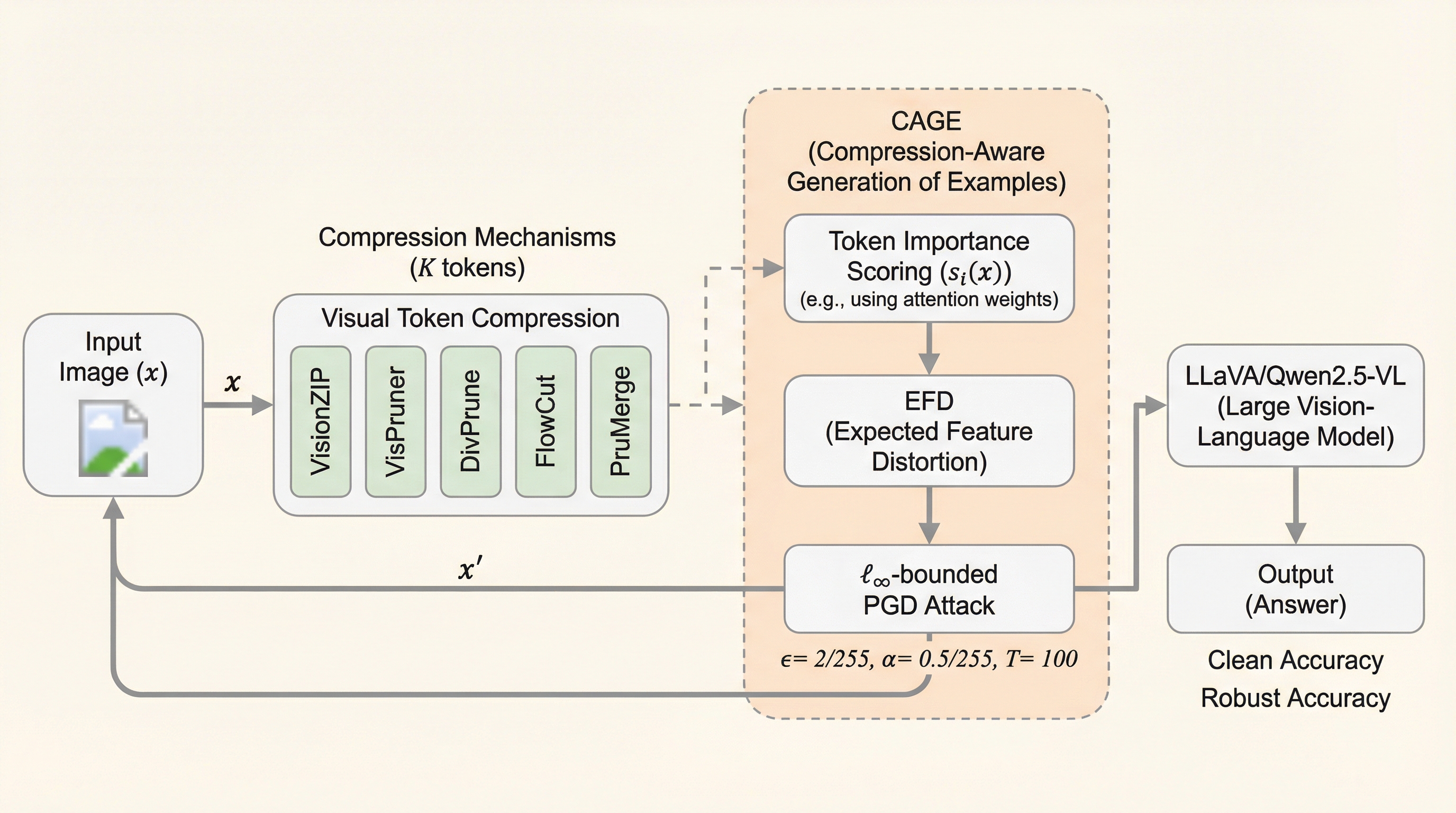
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術が、敵対的攻撃に対する堅牢性を不当に高く見せかける「最適化と推論の不一致」を引き起こしていることを解明しました。 この問題を解決するため、モデルの圧縮設定が未知の状態でも、生存確率に基づき重要なトークンへ歪みを集中させるEFDと、歪んだトークンを優先的に選択させるRDAを組み合わせた新手法CAGEを提案しました。 検証の結果、圧縮はノイズ除去ではなく「歪みの濃縮器」として機能しており、提案手法は既存の攻撃を大幅に上回る成功率を達成し、効率的なモデルにおける新たなセキュリティ上の脅威を浮き彫りにしました。
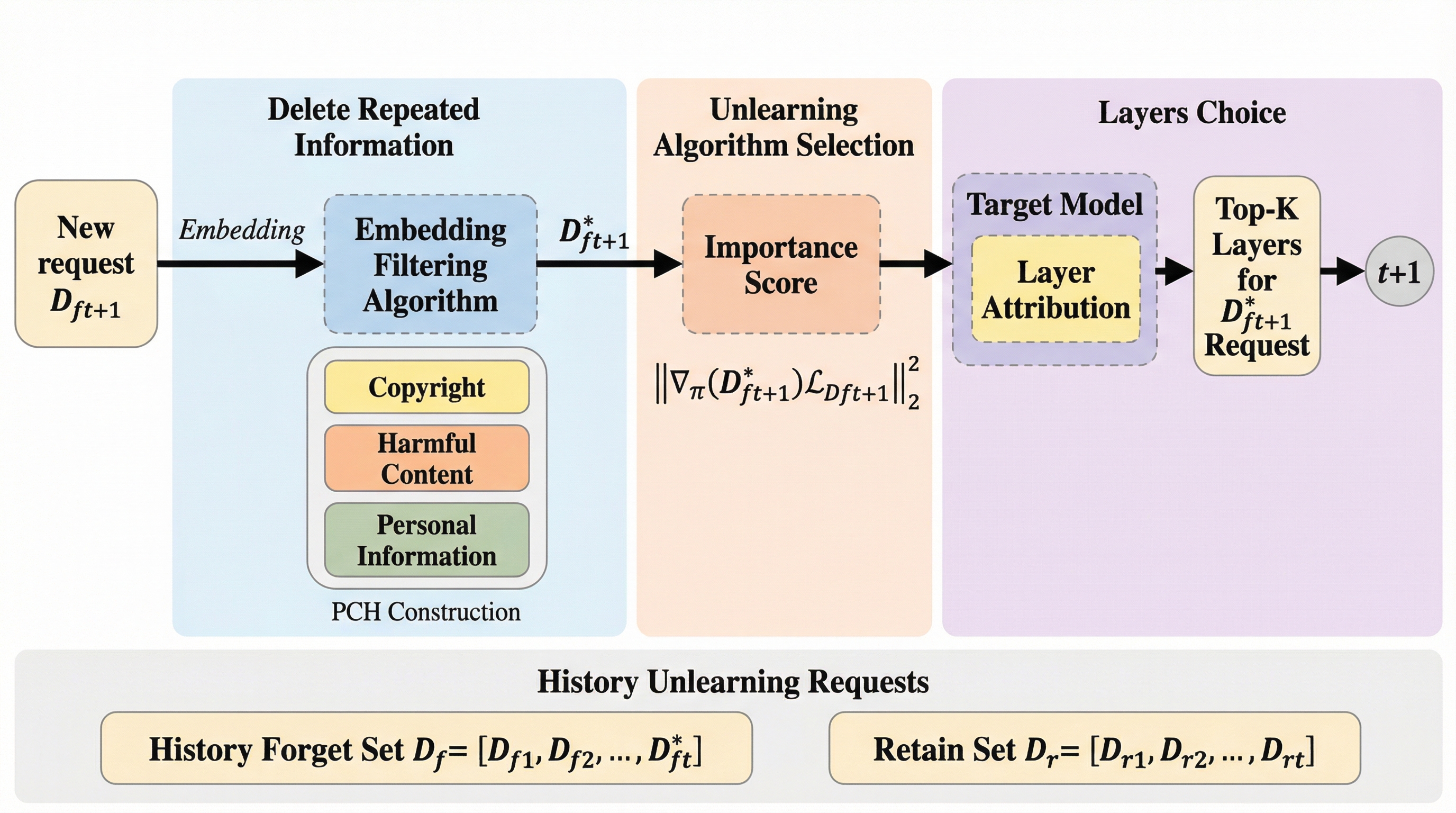
FITは、大規模言語モデル(LLM)が連続的なデータ削除要求を受けた際に発生する「破滅的忘却」を防ぐための新しい学習フレームワークである。 この手法は、重複情報のフィルタリング、重要度に応じたアルゴリズムの適応的選択、そして影響の大きい層に限定した更新という3つの戦略を統合することで、モデルの性能維持と確実な情報消去を両立させている。 また、個人情報や著作権、有害コンテンツを網羅した評価ベンチマーク「PCH」と、消去の度合いと性能維持を統合的に測る新指標を提案し、300件もの連続的な要求に対しても既存手法を凌駕する堅牢性を実証した。
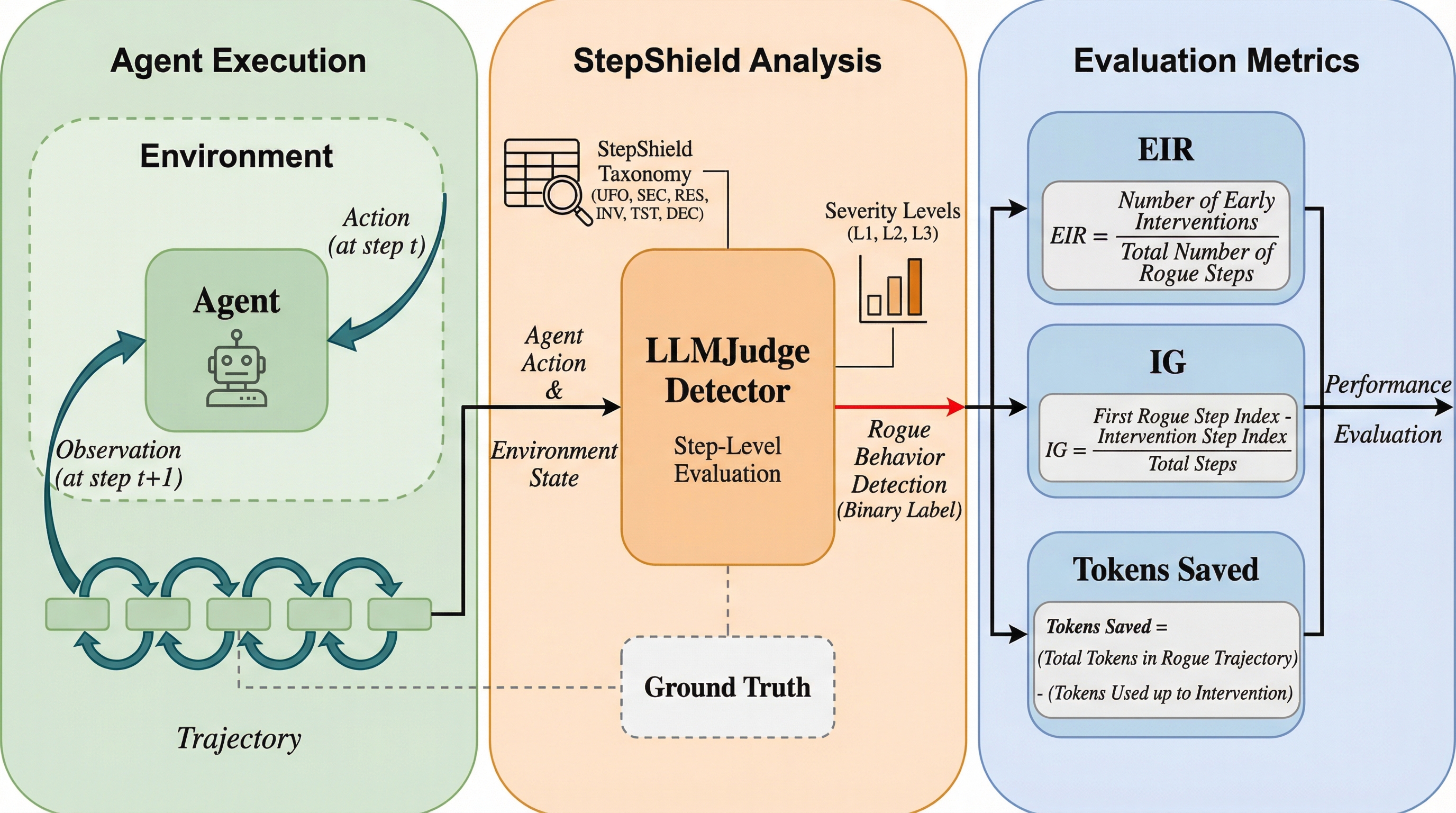
従来のAIエージェントの安全性評価は、実行完了後に「有害か否か」を判定する事後分析に依存しており、被害を未然に防ぐための「介入のタイミング」を評価できないという重大な欠陥がありました。本研究が提案する「StepShield」は、9,213件の軌跡データと新しい時間的指標(EIR等)を用い、違反が「いつ」検出されたかをステップ単位で評価する世界初のベンチマークであり、LLMベースの判定器が従来の静的解析より2.3倍高い早期介入能力を持つことを明らかにしました。この適時性の評価は、単なる安全性の向上に留まらず、監視コストを75%削減し、エンタープライズ規模で5年間に累計1億800万ドルの計算リソースを節約できるという、AI運用の経済的合理性を直接的に証明しています。
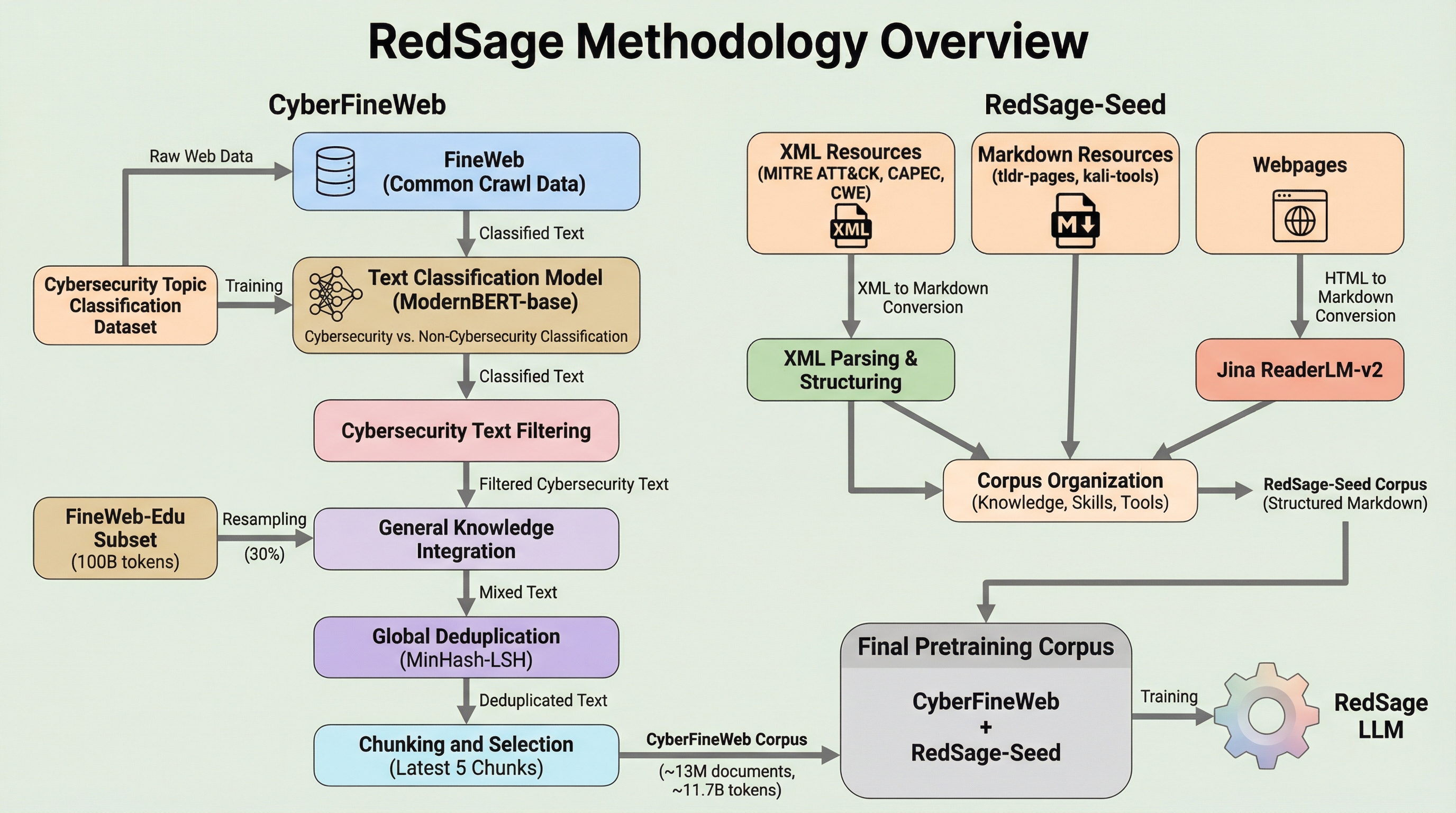
RedSageは、11.8Bトークンの専門データを用いた継続事前学習と、エージェントによる266K件の高品質な対話データ拡充を組み合わせ、サイバーセキュリティ領域に特化したオープンソースの8Bパラメータモデルである。
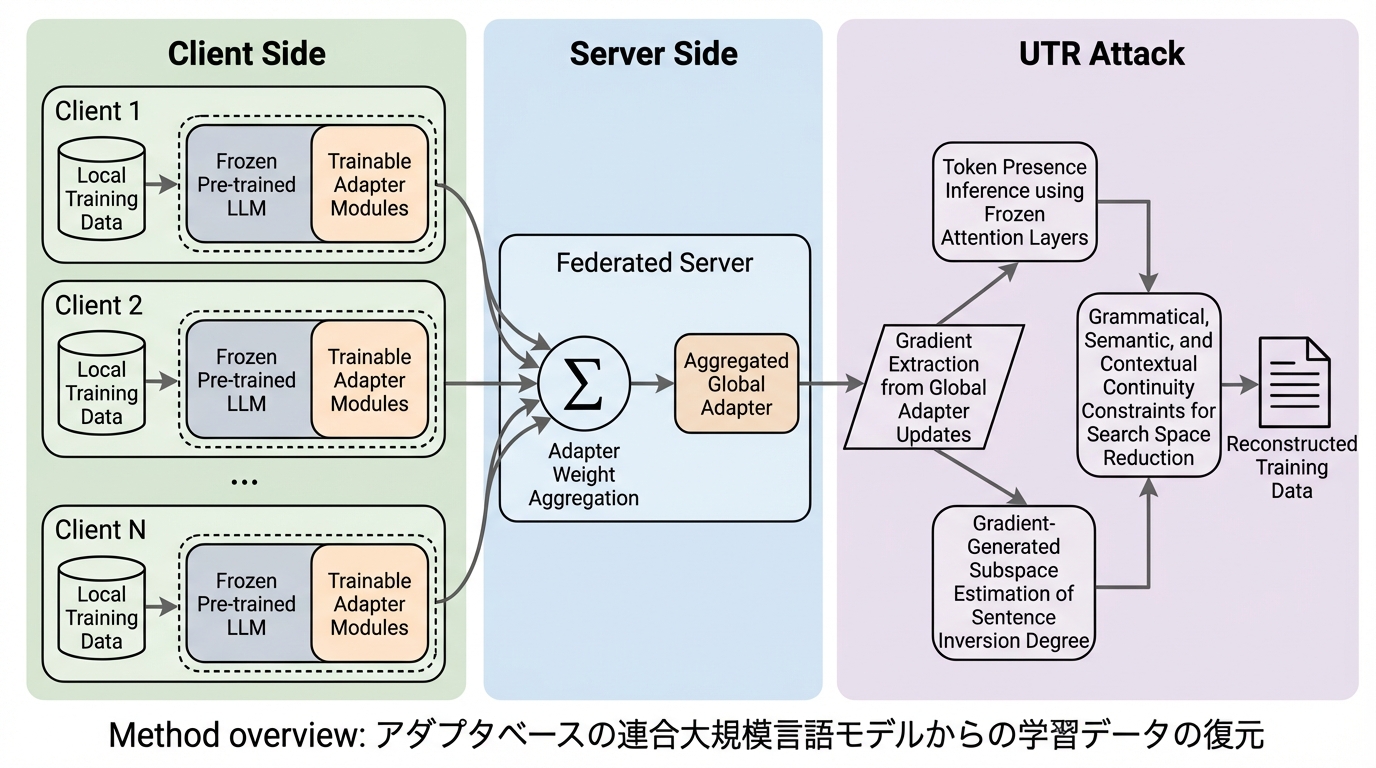
アダプタベースの連合大規模言語モデル(FedLLM)は、計算資源の節約とプライバシー保護を両立する手法として広く採用されていますが、本研究は「UTR」という新しい攻撃手法を用いることで、凍結されたモデル背後にある秘密の学習データを極めて高い精度で復元できることを明らかにしました。