パーソナライズされた生成におけるユーザープライバシーの向上:サーバー側で生成された推測に対するクライアント側検索拡張型の修正
大規模言語モデル(LLM)のパーソナライズにおいて、ユーザーの機密情報をクラウドサーバーに一切開示することなく、高品質な回答を生成するための新しい対話型フレームワーク「P3」が提案されました。 この手法は、サーバー側の強力なモデルが回答候補を生成し、ユーザー手元の小規模モデルが個人のプロフィールに基づき内容を検証・修正する「推測、検証、修正」のプロセスを繰り返すことで、プライバシーと性能を両立させます。 実験では、個人情報を完全に公開した場合の9割以上の性能を維持しつつ、情報漏洩を最小限に抑え、従来のローカルモデル単体や非パーソナライズモデルを平均で7.4%から9%上回る精度を達成することに成功しました。
TL;DR(結論)
大規模言語モデル(LLM)のパーソナライズにおいて、ユーザーの機密情報をクラウドサーバーに一切開示することなく、高品質な回答を生成するための新しい対話型フレームワーク「P3」が提案されました。 この手法は、サーバー側の強力なモデルが回答候補を生成し、ユーザー手元の小規模モデルが個人のプロフィールに基づき内容を検証・修正する「推測、検証、修正」のプロセスを繰り返すことで、プライバシーと性能を両立させます。 実験では、個人情報を完全に公開した場合の9割以上の性能を維持しつつ、情報漏洩を最小限に抑え、従来のローカルモデル単体や非パーソナライズモデルを平均で7.4%から9%上回る精度を達成することに成功しました。
なぜこの問題か
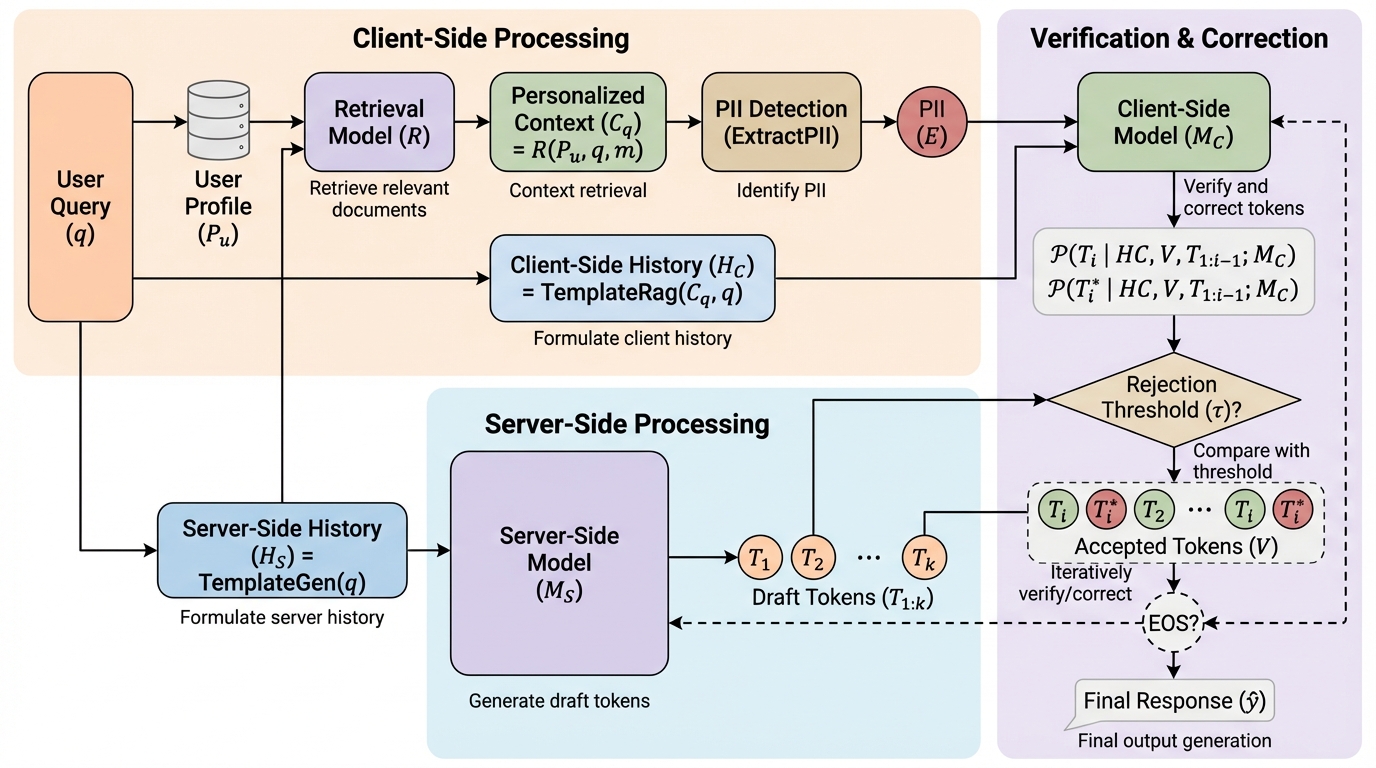
現代の情報アクセスシステムにおいて、パーソナライズは検索エンジン、推薦システム、質問回答システムの性能を向上させるために不可欠な要素となっています。ユーザー個別の好みや過去の対話履歴、背景知識に合わせて回答を調整することで、曖昧な質問の意図を明確にし、適切な事実を選択し、詳細度や口調を制御することが可能になります。現在、大規模言語モデルをパーソナライズするための最も効果的な手法は検索拡張生成(RAG)ですが、これには重大なプライバシー上の課題が伴います。RAGを利用するためには、ユーザーのプロフィールから抽出された関連情報をモデルに提供する必要がありますが、これをクラウド上のサーバーで行う場合、機密性の高い個人データがサービス提供者に公開されてしまいます。 一方で、プライバシーを完全に保護するためにユーザーのデバイス上で動作するローカルモデルのみを使用すると、計算資源やメモリの制約からモデルの規模を小さくせざるを得ず、サーバー側の高性能なモデルと比較して回答の質が著しく低下するという問題が生じます。…
核心:何を提案したのか
本論文では、ユーザーの個人情報をサーバー側に一切開示することなく、高品質なパーソナライズ生成を実現する対話型フレームワーク「P3(Privacy-Preserving Personalization)」を提案しています。P3の最大の特徴は、生成プロセスをサーバー側の「大規模モデル」とクライアント側の「小規模モデル」による共同作業へと分解した点にあります。サーバー側のモデルは、ユーザーの質問のみを受け取り、個人のプロフィールには一切触れることなく、回答の候補となるトークンの列を生成します。これに対し、ユーザーのデバイス上で動作するクライアント側のモデルは、手元にあるプライベートなプロフィールにアクセスし、サーバーから送られてきた候補がユーザーの好みや背景知識に合致しているかを検証します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related