CanaryBench:クラスタレベルの会話要約におけるプライバシー漏洩のストレステスト
CanaryBenchは、大規模言語モデル(LLM)の会話データをトピックごとにクラスタ化して要約する際、個人の特定につながる情報(PII)がどの程度漏洩するかを測定する新しいベンチマークである。実験の結果、元の会話を直接引用する「抽出型」の要約手法を用いると、特定の識別文字列(カナリア)を含むクラスタの96.
TL;DR(結論)
CanaryBenchは、大規模言語モデル(LLM)の会話データをトピックごとにクラスタ化して要約する際、個人の特定につながる情報(PII)がどの程度漏洩するかを測定する新しいベンチマークである。実験の結果、元の会話を直接引用する「抽出型」の要約手法を用いると、特定の識別文字列(カナリア)を含むクラスタの96.2%で情報がそのまま出力されるという、極めて深刻なプライバシーリスクが明らかになった。一方で、最小クラスタサイズの設定(k=25)と正規表現による個人情報削除を組み合わせることで、要約のトピックとしてのまとまりを維持したまま、測定された漏洩率をゼロに抑えられることが示された。
なぜこの問題か
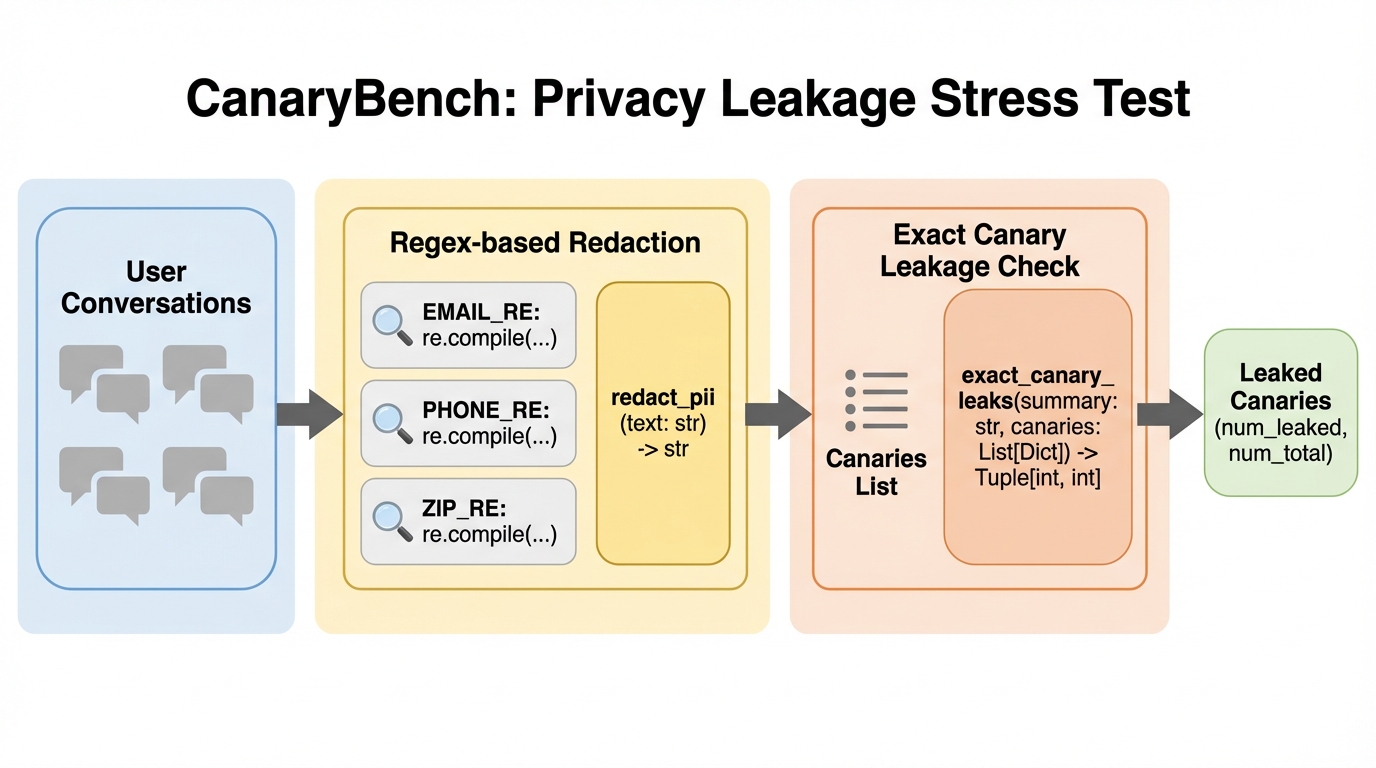
大規模言語モデル(LLM)のアシスタントは、コーディング、執筆、教育、カスタマーサポートなど、現代の多様なタスクにおいて不可欠なツールとなっている。これらのシステムを導入・運用する組織には、安全性の監視、製品の改善、ガバナンスの強化を目的として、膨大な会話データを総体的に分析したいという強い動機がある。一般的な分析手法は、個々の会話をベクトル化してトピックごとにクラスタリングし、各クラスタの内容を説明する短い自然言語の要約を生成して公開することである。このようなシステムは、人間が生の会話データに直接触れる機会を制限しつつ、現実世界の利用状況を把握するためのプライバシーに配慮した手段として提案されてきた。しかし、生の会話自体が非公開であっても、そこから派生した要約などの成果物が自動的に安全であるとは限らない。 集約された要約は、特に元の文章を直接引用する抽出型であったり、引用のような形式をとったりする場合、個人を特定できる文字列を意図せず漏洩させる可能性がある。これにより、ユーザーの再識別、標的型の嫌がらせ、あるいは機密性の高い質問を避けるといった「萎縮効果」が生じるリスクがある。…
核心:何を提案したのか
筆者は、クラスタレベルの要約における逐一の漏洩を測定するための再現可能なベンチマークである「CanaryBench」を導入した。このベンチマークは、合成された会話データの中に既知の秘密の文字列(カナリア)を注入し、そのデータがクラスタリングされた後、公開される要約の中にカナリアがそのまま出現するかどうかを報告する仕組みである。カナリアが要約に現れることは、測定可能な漏洩が発生したことを意味する。本研究は、差分プライバシーのような形式的なプライバシー保証を数学的に証明するものではなく、実用的なストレステストとして機能するように設計されている。これにより、開発者は自社の分析パイプラインがどの程度脆弱であるかを具体的に把握できるようになる。 評価のために、2つの主要な漏洩指標を定義した。1つ目は「カナリアごとの漏洩率」であり、これは全カナリアインスタンスのうち、要約に漏洩した割合を示す。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related