LLM推論失敗の全体像:何が壊れ、どこが脆く、どう直すべきかを整理する包括サーベイ
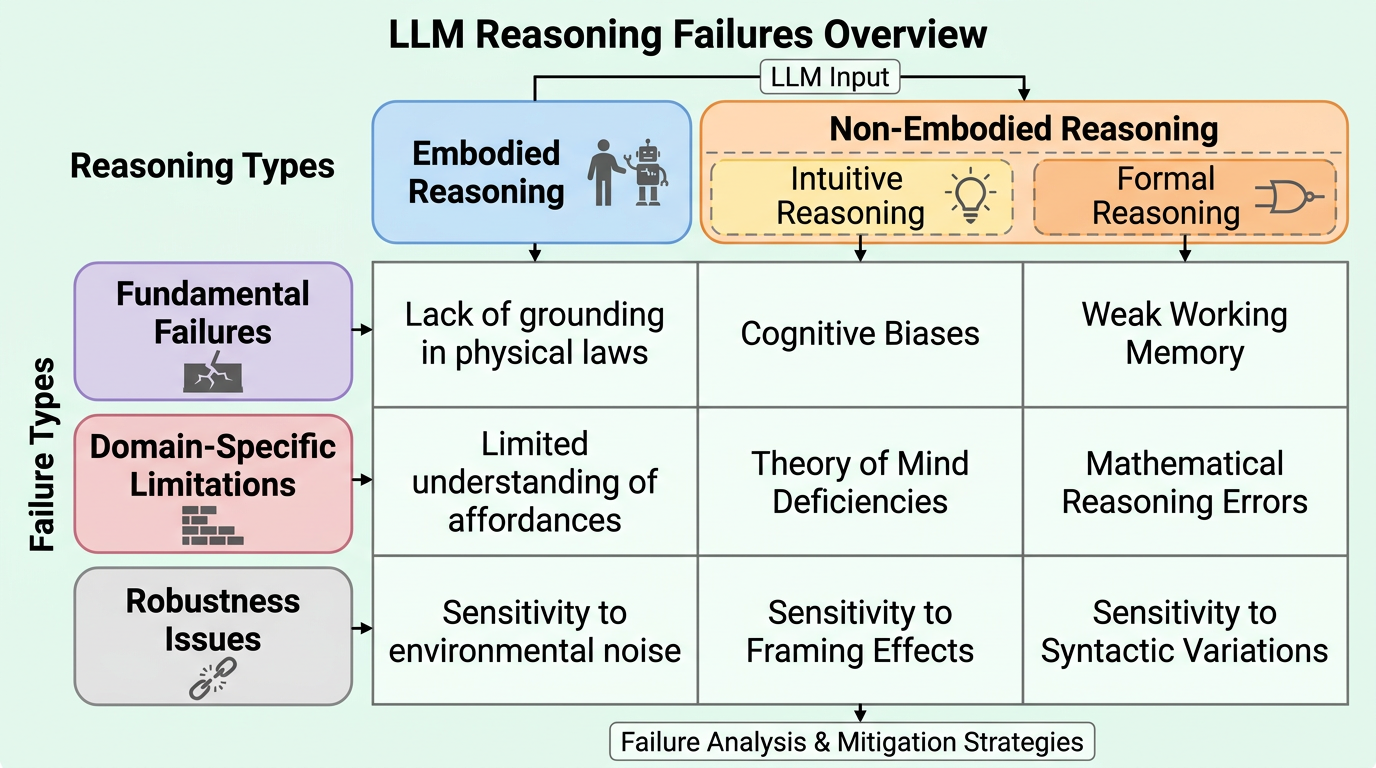
この論文は、LLM の推論失敗を「身体性を伴う推論 / 非身体的推論」と「根本的失敗 / 領域固有の限界 / 頑健性の問題」の二軸で整理する包括サーベイです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
この論文は、LLM の推論失敗を「身体性を伴う推論 / 非身体的推論」と「根本的失敗 / 領域固有の限界 / 頑健性の問題」の二軸で整理する包括サーベイです。
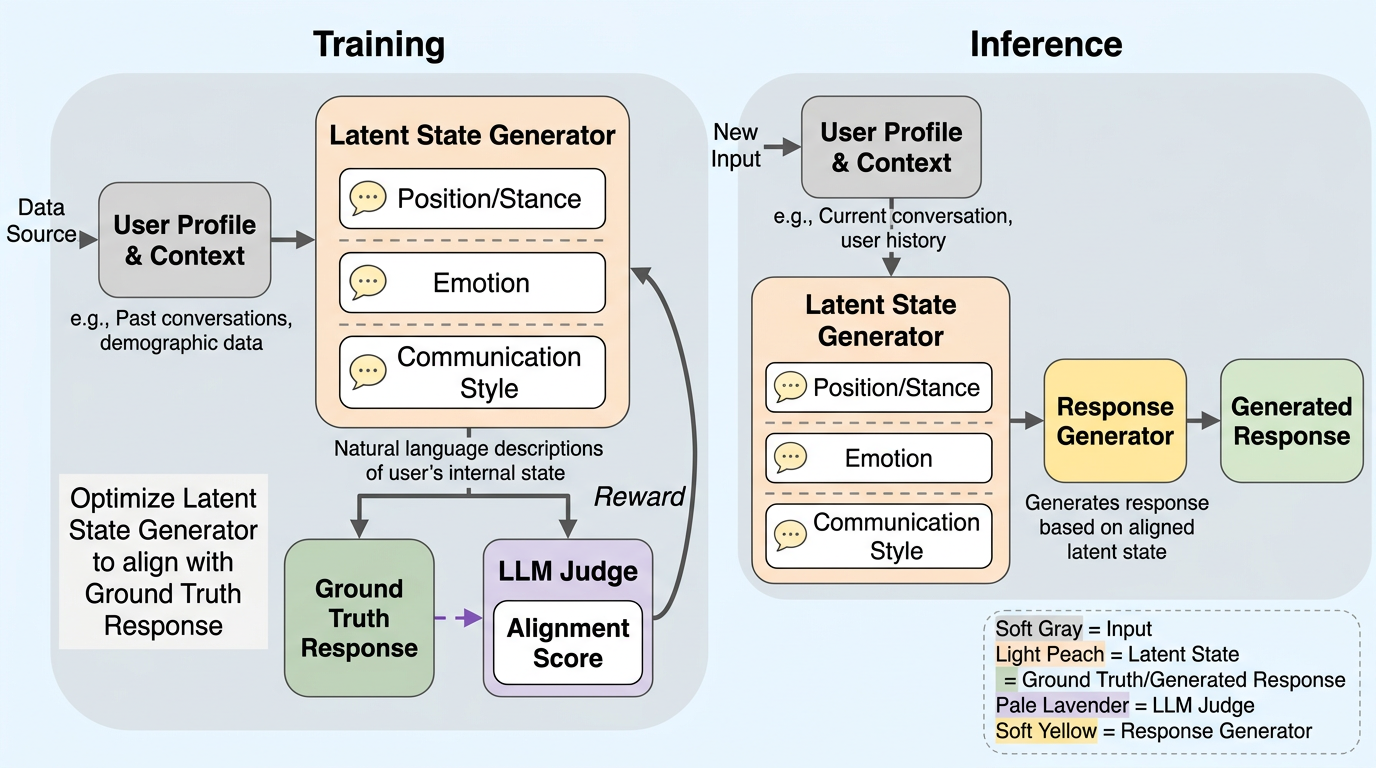
HumanLMは、応答の文体ではなく、信念・目標・価値観・立場・感情・伝え方という潜在状態を整合させることで、より本人らしいユーザーシミュレーションを目指す研究です。
本研究は、実際の機械翻訳ポストエディット案件から得られた 6,000 超の英語文と 9 個の翻訳候補を使い、翻訳品質予測の二つの系統、すなわち「原文側の難しさ予測」と「候補文側の品質推定」を同じ土台で見直したものです。 Kendall の順位相関で TER と COMET の両方を参照すると、原文側指標の当たり方は評価軸によって大きく変わり、候補文側の QE 指標も従来型 NMT には比較的合う一方、汎用 LLM の出力にはそのままでは合いにくいことが分かりました。 文書後半ほど訳質が落ちる document-level LLM の位置バイアスは統計的には確認されましたが、実務影響は小さく、むしろ重要なのは「どの品質概念を測りたいのか」を TER と COMET の違いまで含めて明示することだと示しています。
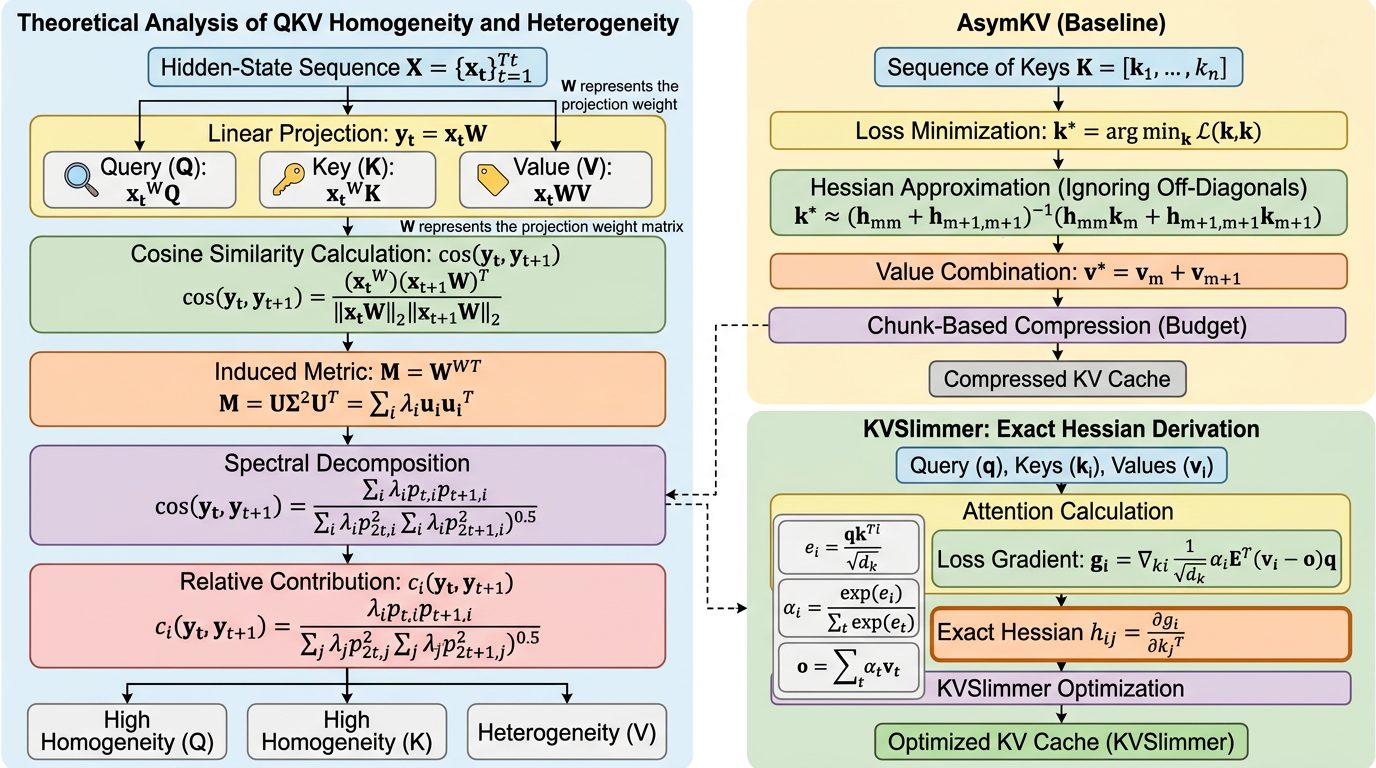
KVSlimmer は、KV キャッシュ圧縮で経験則として語られてきた「Key は似やすく、Value は似にくい」という非対称性を、投影重みのスペクトルエネルギー分布から理論的に説明し、その性質に沿って圧縮を行う手法です。 既存法のような勾配ベース近似ではなく、前向き計算だけから exact Hessian を扱える閉形式へ落とし込み、gradient-free でメモリ効率と速度の両方を改善します。 Llama3.1-8B-Instruct では LongBench 平均を 0.92 改善しつつ、メモリ 29%、レイテンシ 28% を削減しており、KV キャッシュ削減が「安くなる代わりに性能が落ちる」という固定観念をかなり崩しています。
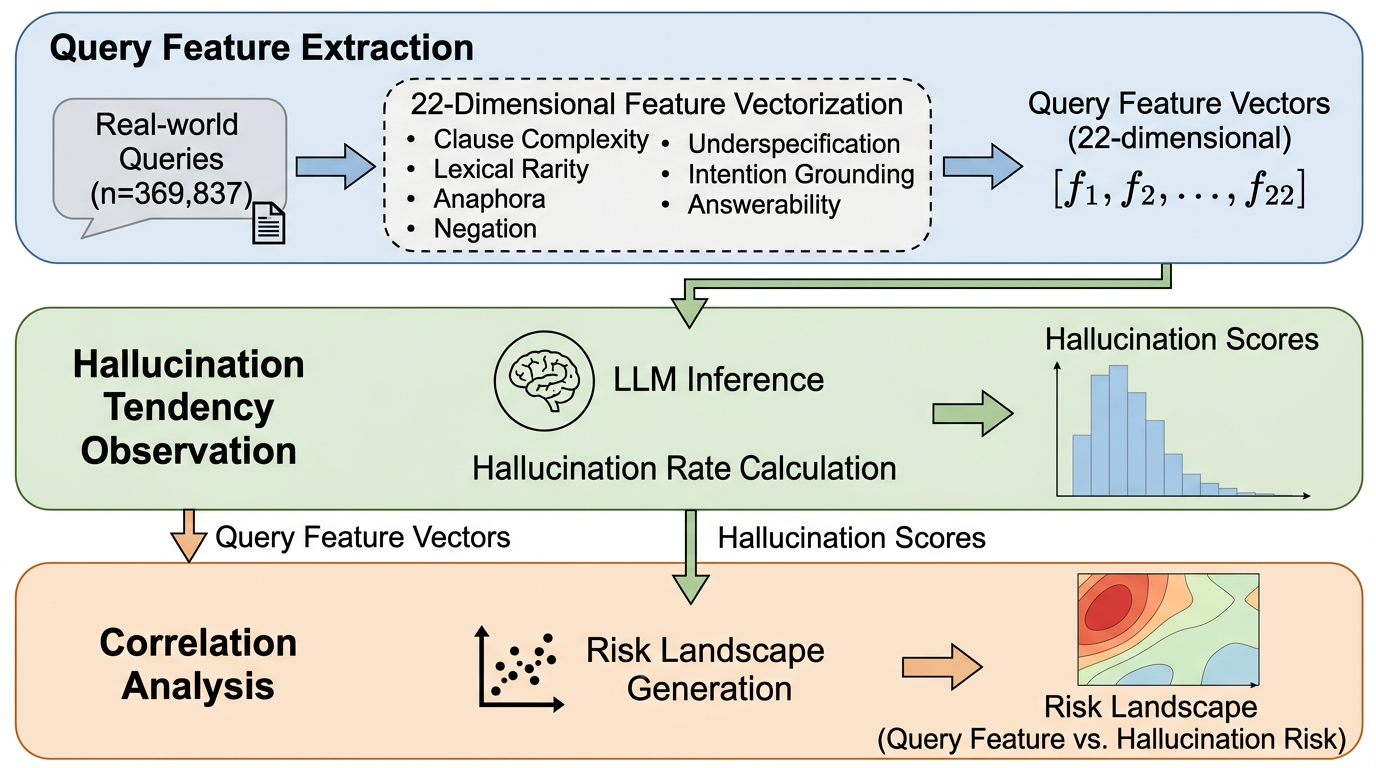
LLMの幻覚リスクをクエリの言語特徴(22次元)として測り、どの問い方が高リスクかを大規模実データで示した研究です。
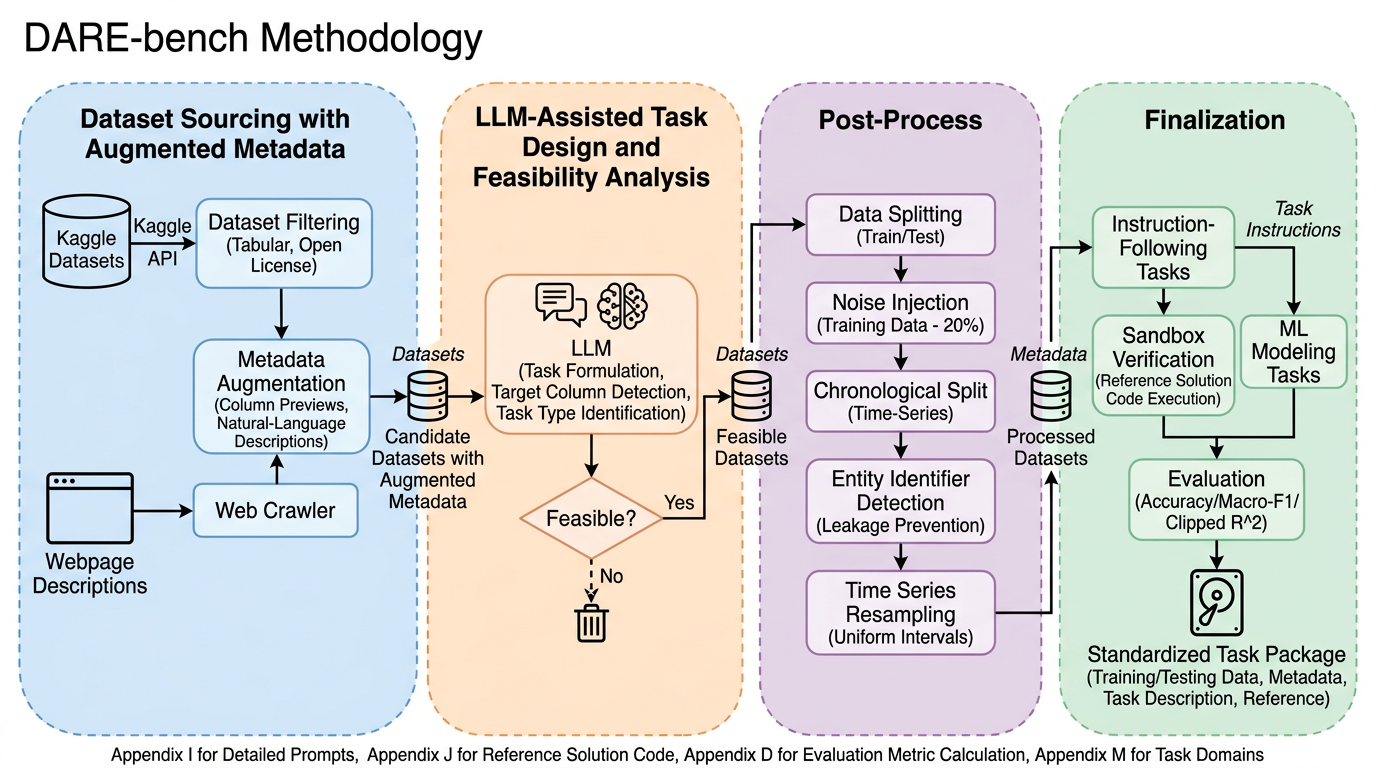
DARE-bench は、データサイエンスの複数ステップ作業に対して、最終スコアだけでなく process fidelity、つまり指示どおりの手順を守れたかまで検証できる 6,300 件規模のベンチマークです。 Kaggle 由来データを自動整形し、Instruction Following と ML Modeling の二系統を verifiable ground truth 付きで構成しているため、judge ベースでなく客観採点ができます。 強い汎用 LLM でも素のままでは大きく崩れ、Qwen3-4B の total score は 4.39 に留まりますが、DARE-bench 由来データで学習すると RL で 37.40 まで伸び、Qwen3-32B でも SFT により約 1.83 倍の改善が出ています。
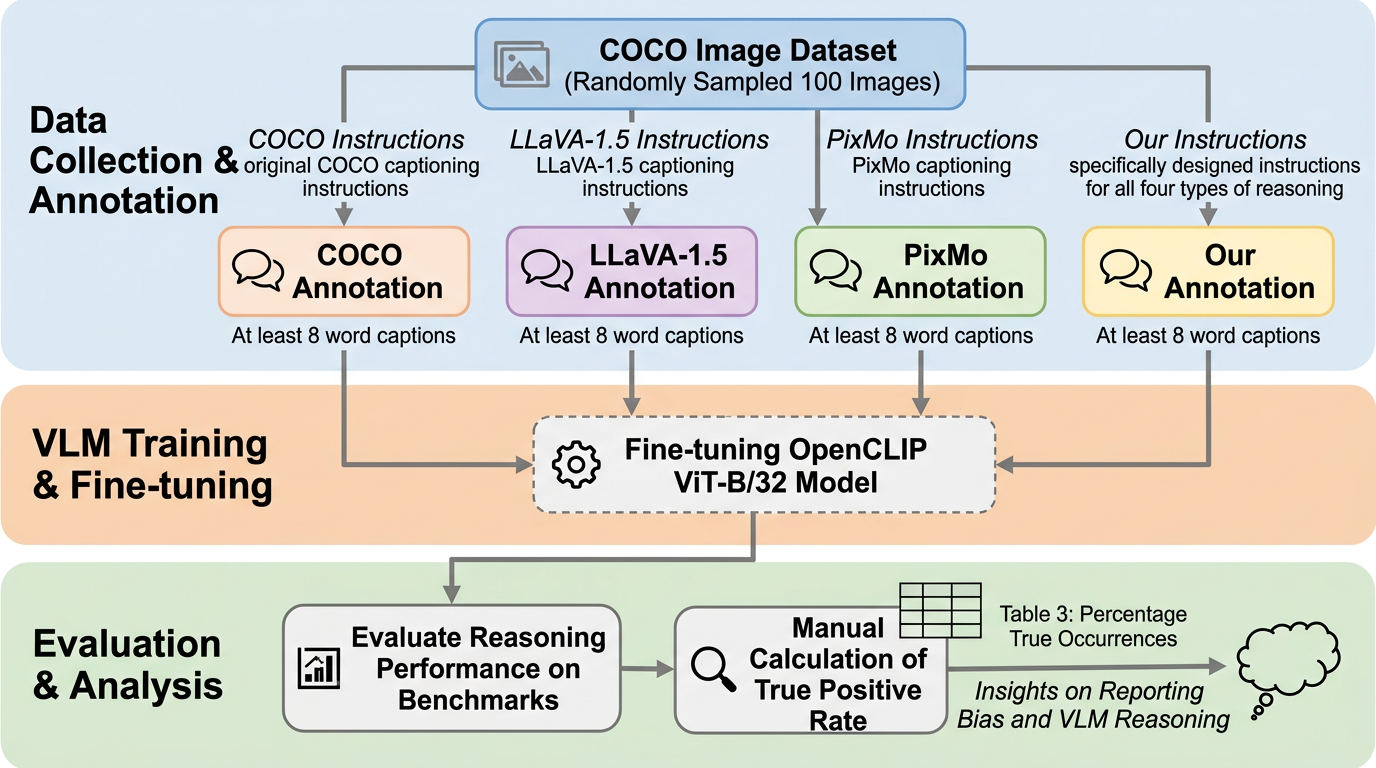
視覚言語モデルの推論不足は、モデルの大きさよりも、人間が画像説明で省略しがちな情報に強く左右されます。空間・時間・否定・カウントの4種類を軸に見ると、学習コーパスの報告バイアスがそのまま性能の穴になっており、スケール拡大や多言語化だけでは埋まりません。
SteuerEx は、実際のドイツ大学税法試験から構築された公開ベンチマークです。これに特化した 28B の SteuerLLM は、72B 級の汎用 instruction-tuned モデルや GPT-4o-mini を上回り、税法ではサイズより専門特化が効くことを示しました。
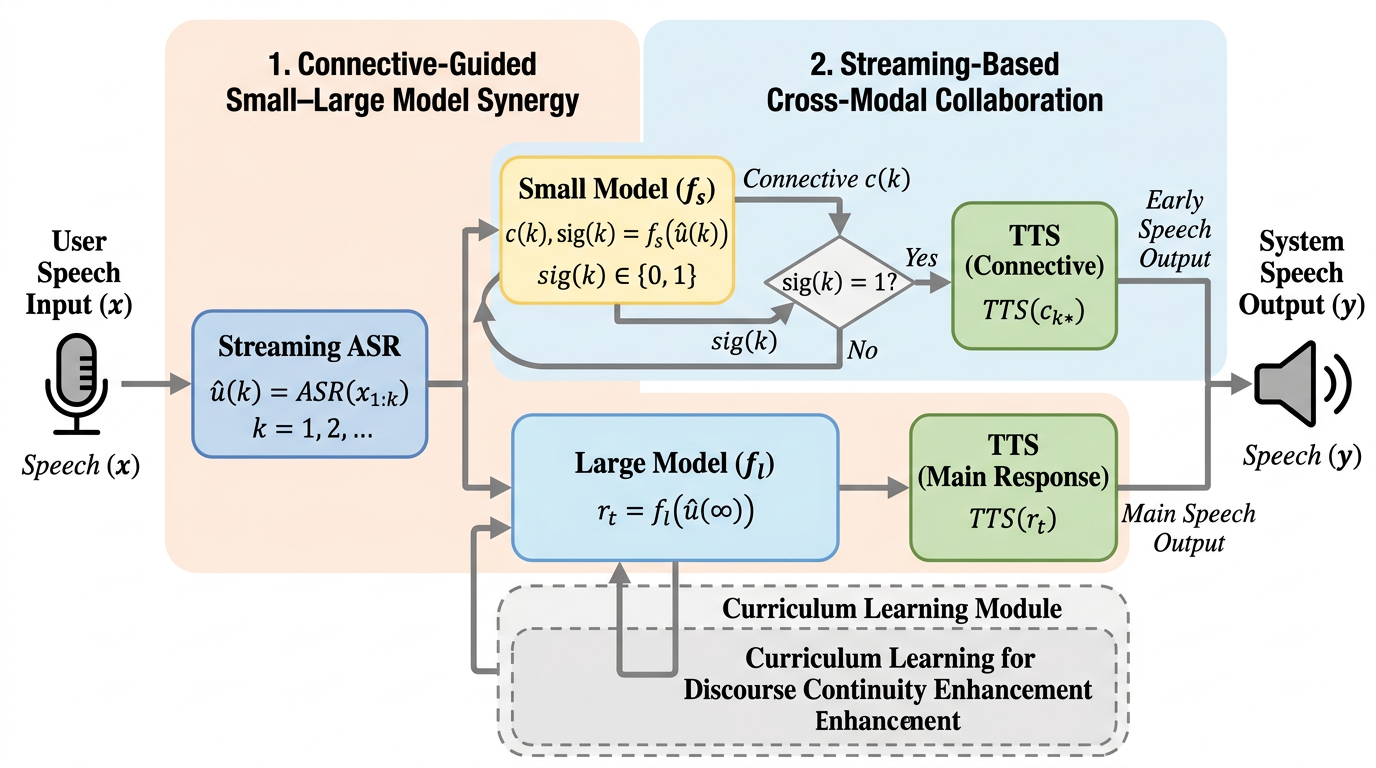
DDTSR は、音声対話で最も不快な「考えてから話し始める待ち時間」を、軽量モデルが安全なつなぎ表現を先に出し、大きなモデルが本体を並列生成する二段構えで短縮する手法です。 重要なのは単なる高速化ではなく、ユーザーが体感する待ち時間を分解し、知覚遅延と反応遅延の両方を別々に削っていることです。SD-Eval では待ち時間を 1003ms から 548ms、条件によっては 515ms まで下げています。 しかも一貫性・談話のまとまり・音声自然性は大きく崩しておらず、既存の ASR や TTS を総入れ替えせずに会話体験だけを改善できる点が、研究としても実装としても強いです。
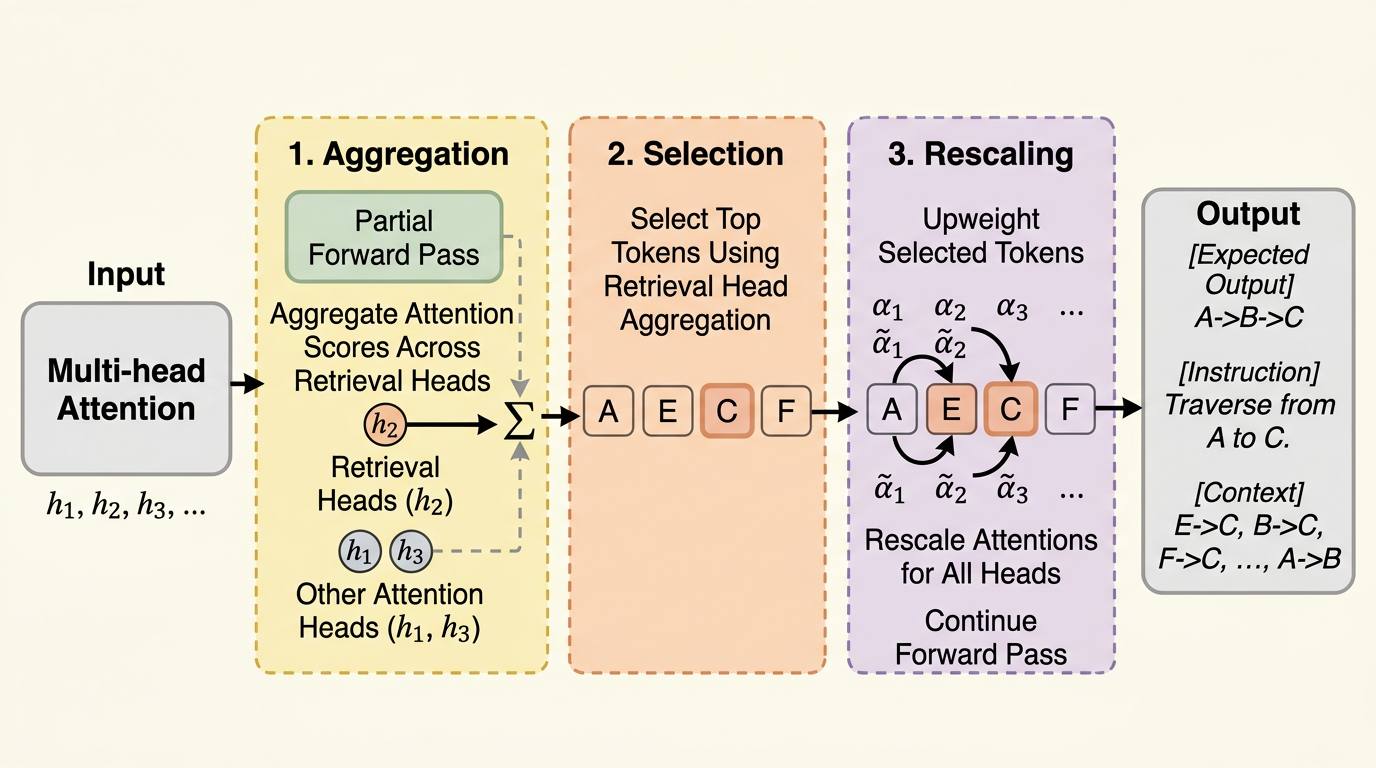
DySCO は、長文脈推論で精度が落ちる原因を「関連箇所への注意が生成途中で薄まること」と捉え、retrieval heads を使ってその時点で重要なトークンを見つけ、全ヘッドの注意を動的に増幅する推論時アルゴリズムです。 学習不要で既存モデルにそのまま適用でき、Qwen3-8B では 128K 文脈の MRCR と LongBenchV2 で YaRN 単独比最大 25% 相対改善、追加計算はおおむね 4% 程度に収まっています。 重要なのは、一律に attention を鋭くするのではなく、「今この生成ステップで必要な箇所だけ」を選んで強める点で、長文脈の精度改善を retrieval / compression とは別の軸で成立させたことです。