順序に縛られない思考:拡散言語モデルにおける出力順序と推論順序の乖離
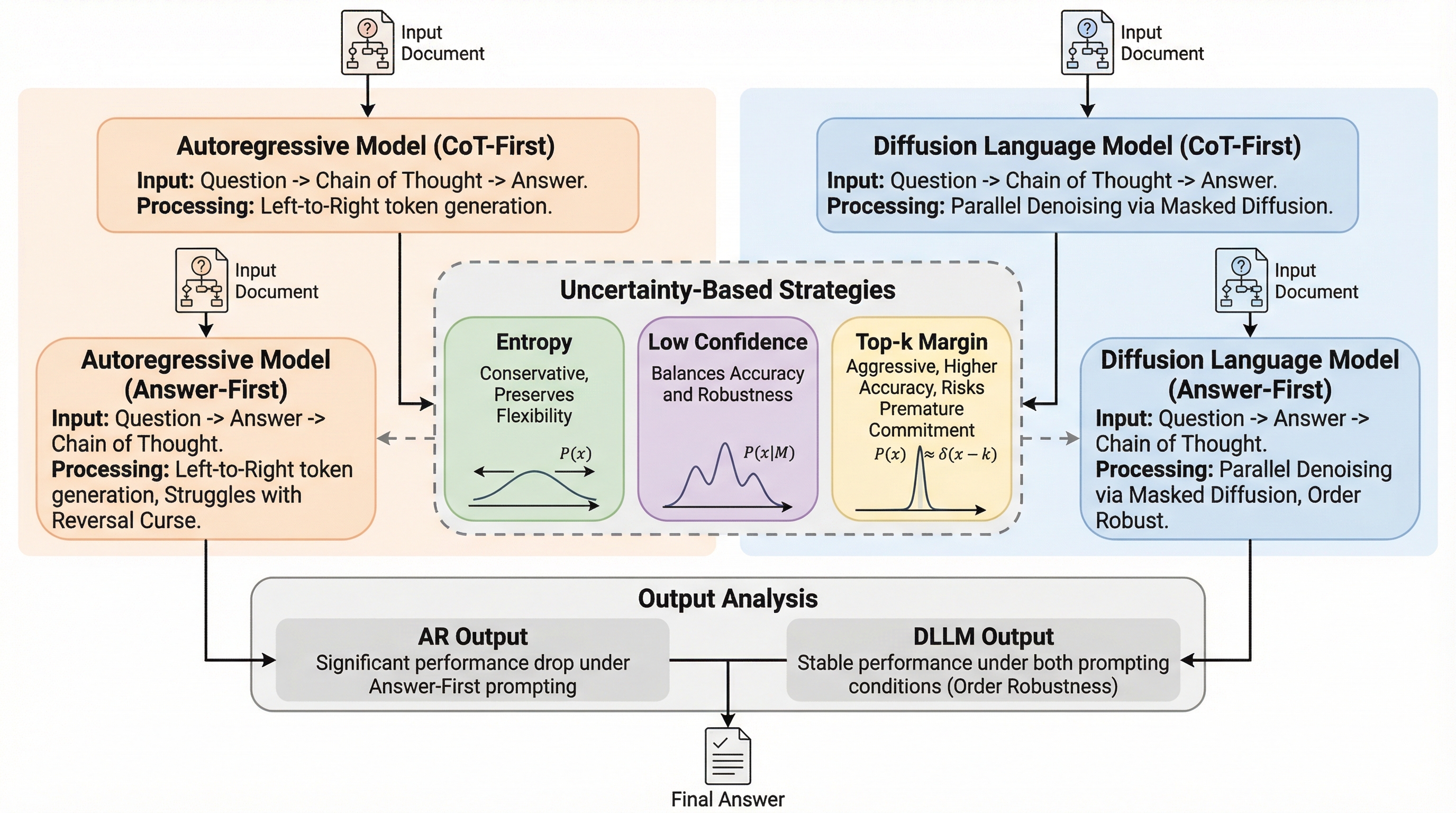
従来の自己回帰型モデルは、回答を推論より先に出力する形式において、十分な思考の前に回答を確定させてしまうため精度が最大67%低下するという構造的な課題がありました。本研究では、マスク拡散言語モデル(MDLM)が、出力の物理的な位置に関わらず確信度の高いトークンから処理することで、回答を先に出力する場合でも高い精度を維持する「順序に対する堅牢性」を持つことを明らかにしました。新ベンチマーク「ReasonOrderQA」を用いた検証により、拡散モデルは単純な推論ステップを複雑な回答よりも先に安定させることで、内部的な推論を先行させてから回答を確定させる仕組みを持っていることが示されました。
TL;DR(結論)
従来の自己回帰型モデルは、回答を推論より先に出力する形式において、十分な思考の前に回答を確定させてしまうため精度が最大67%低下するという構造的な課題がありました。本研究では、マスク拡散言語モデル(MDLM)が、出力の物理的な位置に関わらず確信度の高いトークンから処理することで、回答を先に出力する場合でも高い精度を維持する「順序に対する堅牢性」を持つことを明らかにしました。新ベンチマーク「ReasonOrderQA」を用いた検証により、拡散モデルは単純な推論ステップを複雑な回答よりも先に安定させることで、内部的な推論を先行させてから回答を確定させる仕組みを持っていることが示されました。
なぜこの問題か
現代の言語モデルにおいて、ユーザーが指定した形式や構造に従う能力は不可欠ですが、これまでの成功は「推論を先に行い、その後に回答を出す」という思考の連鎖(CoT)の順序に強く依存していました。しかし、実社会のアプリケーションでは、結論を先に述べるピラミッド原則や、特定のキー順序が厳格に定められたJSONスキーマのように、推論に必要なデータの前に最終的な結論や統計値を出力しなければならない制約が頻繁に発生します。自己回帰型(AR)モデルは、左から右へと順番にトークンを生成する性質上、確率の割り当て順序とテキストの出力順序が完全に結合しています。そのため、回答を先に出力するよう求められると、中間的な推論トークンが生成される前の段階で、回答トークンを確定させなければならないという根本的な限界に直面します。 この「早すぎる確定(Premature Commitment)」は、モデルが後から予測を修正したり、双方向的な計画を立てたりする能力を著しく制限します。…
核心:何を提案したのか
本研究では、出力順序が変更されても推論精度を維持できる能力を「順序に対する堅牢性(Order Robustness)」と定義し、マスク拡散言語モデル(MDLM)がこの特性を備えていることを提案しました。MDLMは、自己回帰型モデルのようにトークンを順番に生成するのではなく、双方向Transformerを用いて全トークンを並列かつ反復的に洗練していく生成パラダイムを採用しています。これにより、計算の順序を出力テキストの物理的な位置から切り離すことが可能になります。この能力を体系的に評価するために、研究チームは「ReasonOrderQA」という新しいベンチマークを導入しました。このベンチマークは、難易度を制御した算術問題で構成されており、モデルが情報を取得する段階と推論する段階を分離して評価できるように設計されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related