指示に従うこととタスク解決能力の間の逆説的な干渉について
大規模言語モデル(LLM)において、ユーザーの指示や制約を遵守しようとする能力(指示追従)が、モデルが本来持っているはずのタスク解決能力をかえって阻害してしまう「逆説的な干渉」という現象が本研究によって明らかになりました。
TL;DR(結論)
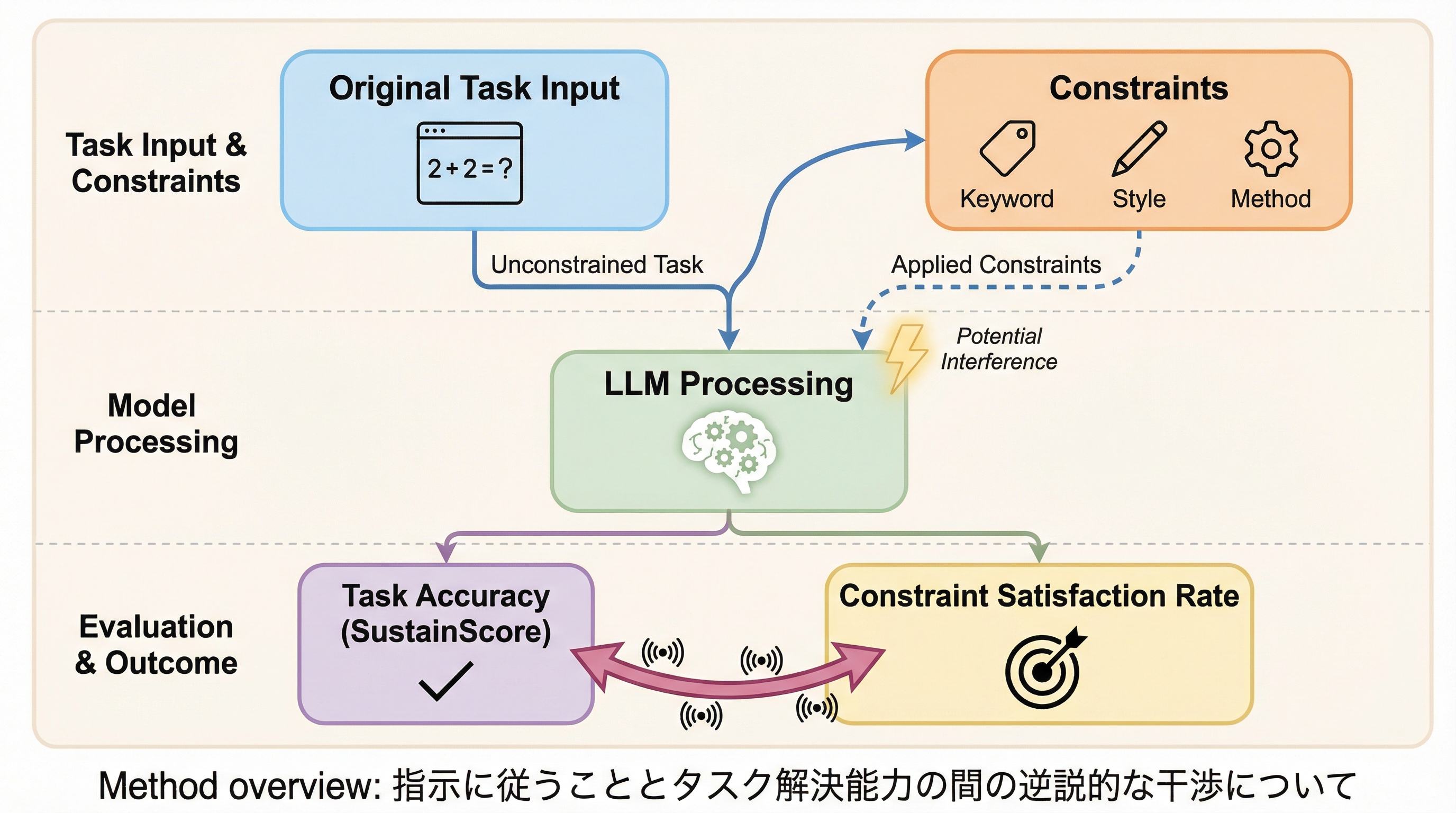
大規模言語モデル(LLM)において、ユーザーの指示や制約を遵守しようとする能力(指示追従)が、モデルが本来持っているはずのタスク解決能力をかえって阻害してしまう「逆説的な干渉」という現象が本研究によって明らかになりました。 研究チームは、モデルが制約なしの状態で自発的に満たしていた条件をあえて「明示的な制約」として指示に加えた際の性能維持率を測る新指標「SUSTAINSCORE」を提案し、数学、多段階QA、コード生成の各ドメインで検証を行いました。 検証の結果、Claude-Sonnet-4.5のような最先端モデルであっても制約の追加により正解率が低下し、特にコード生成では本来の能力の60%未満にまで落ち込むモデルが続出するなど、制約への過度な注意が推論の質を著しく下げている実態が判明しました。
なぜこの問題か
大規模言語モデル(LLM)の急速な発展に伴い、モデルが人間の意図を正確に汲み取り、指定された形式やルールを厳密に守る「指示追従(Instruction Following)」の能力は、実用性を高めるための最優先事項として扱われてきました。開発現場では、モデルがどれだけ複雑な制約を遵守できるかを競うようにベンチマークが作成され、それに基づいた強化学習や微調整が行われています。しかし、ここで一つの根本的な疑問が生じます。それは、「指示を完璧に守ろうと努力すること自体が、モデルの本来の知能や推論プロセスに悪影響を与えていないか」という点です。これまでの評価手法の多くは、モデルが制約を守れたかどうかという形式の正しさに焦点を当てており、その制約が課されたことによって「本来解けたはずの問題が解けなくなる」という副作用については十分に調査されてきませんでした。 もし、指示に従うという負荷がモデルの計算リソースや注意力を奪い、タスク解決の質を下げているのであれば、それは現在のAI開発における重大な盲点となります。…
核心:何を提案したのか
研究チームは、指示追従がタスク解決能力に与える干渉を定量化するための革新的な指標「SUSTAINSCORE(サステインスコア)」を提案しました。この指標の核心的なアイデアは、モデルが本来持っている能力を基準として、制約が加わった際にどれだけその性能を「維持」できるかを測定することにあります。具体的には、まずモデルが何の制約もない状態で正解できたタスクのみを抽出します。次に、その成功した出力結果から、モデルが自発的に満たしていた性質、例えば特定の解法、文章の長さ、使用したキーワードなどを「自明な制約(Self-Evident Constraint)」として抽出します。 この「自明な制約」は、モデルがそのタスクを解く過程で自然に達成しているものであるため、論理的にはその制約を改めて指示に加えても、モデルは引き続き正解できるはずです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related