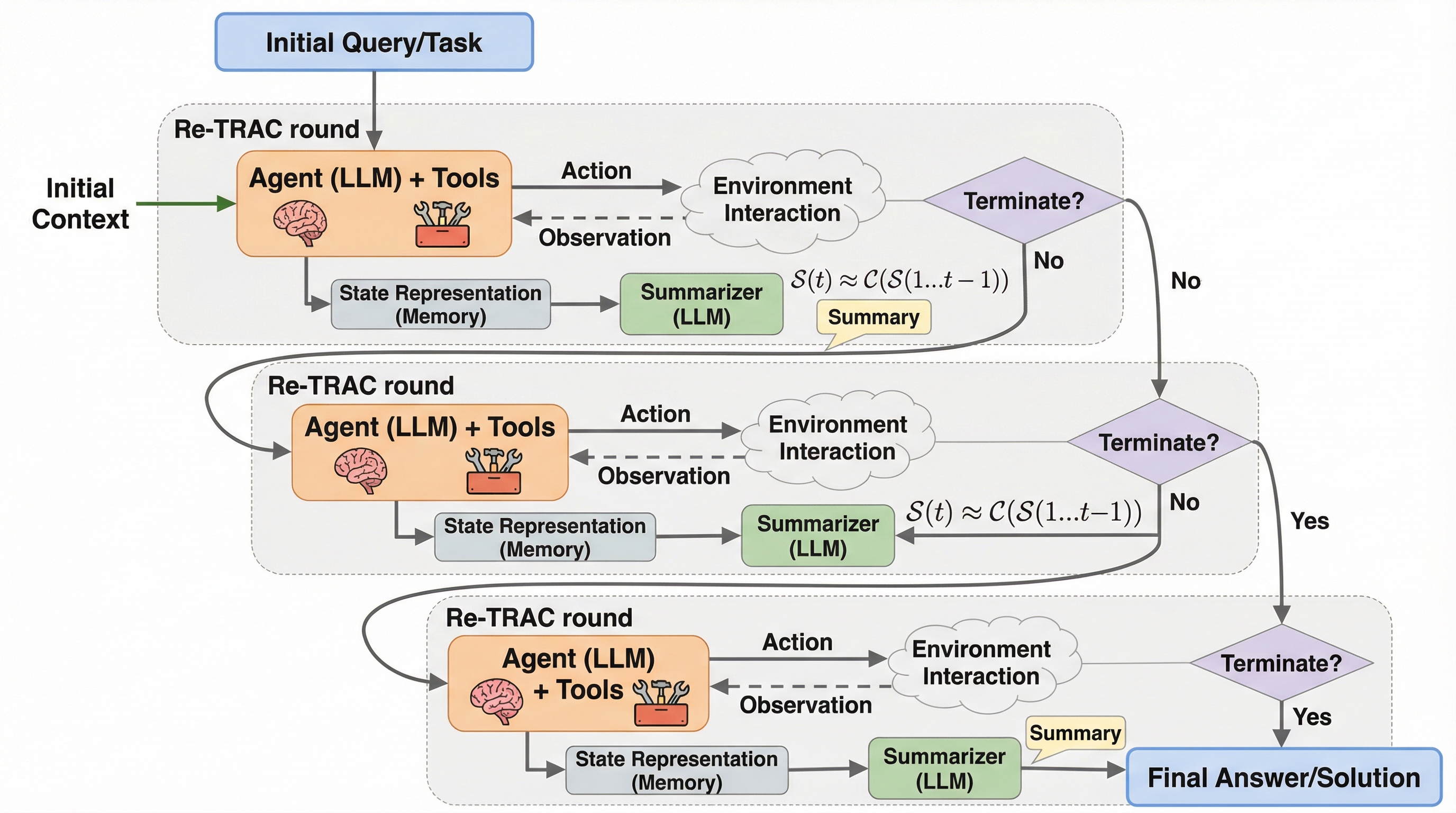
RE-TRAC:Deep Search Agentsのための再帰的軌跡圧縮
研究エージェントは、なぜ「同じところをぐるぐる回る」のでしょうか? 原因は推論能力ではなく、“探索の形”にある――というのが本論文の出発点です。 この記事では、ReActの直線的な探索を「再帰的に折りたたむ」Re-TRACの狙いと効きどころを、読み物として整理します。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
研究エージェントは、なぜ「同じところをぐるぐる回る」のでしょうか? 原因は推論能力ではなく、“探索の形”にある――というのが本論文の出発点です。 この記事では、ReActの直線的な探索を「再帰的に折りたたむ」Re-TRACの狙いと効きどころを、読み物として整理します。
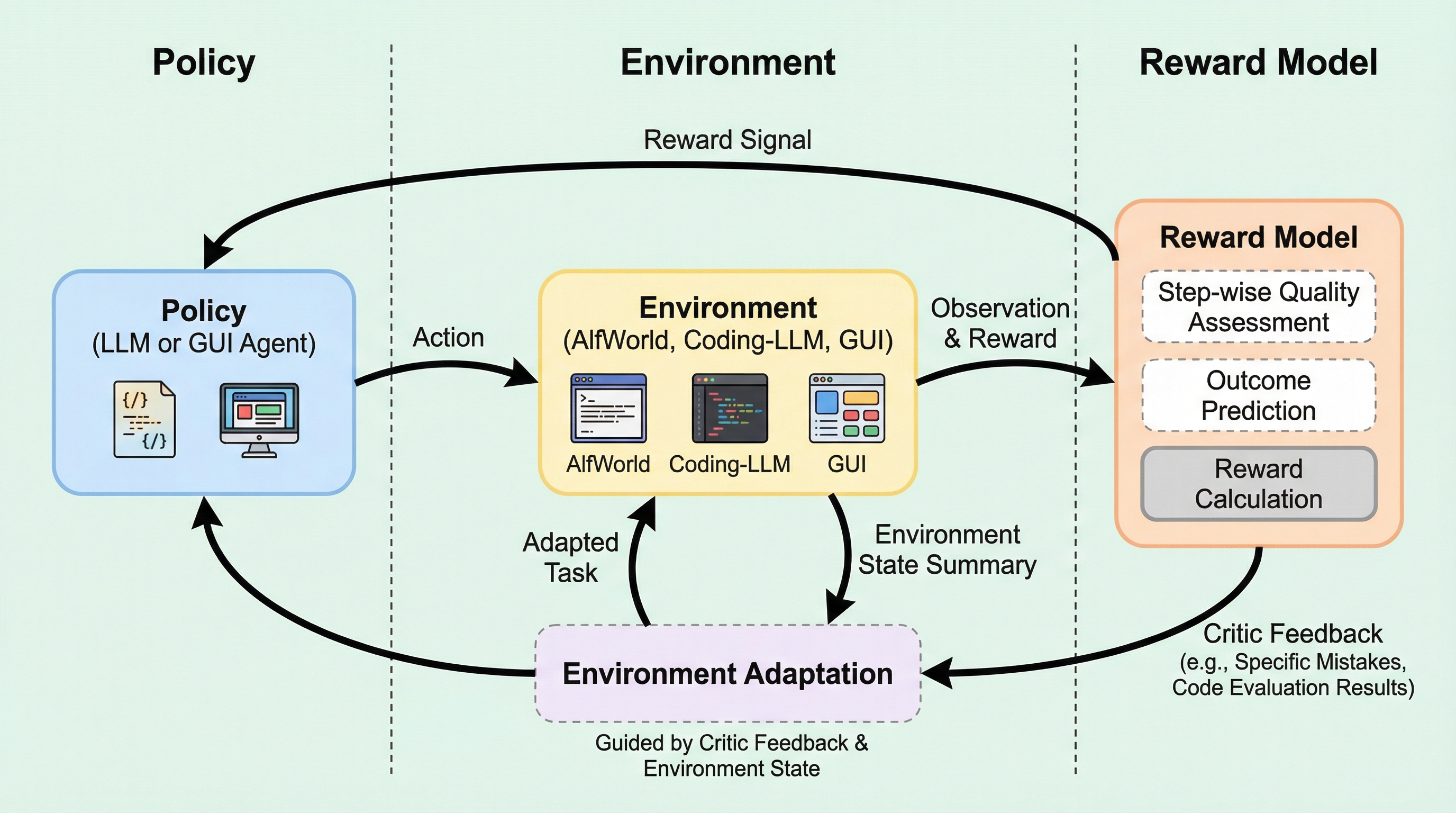
自然言語で動くエージェントは、なぜ「最後の正解・不正解」だけでは育ちにくいのか? 答えは、長い軌跡を進むほど“途中の学びの手がかり”が痩せていくからです。 この記事では、環境・方策・報酬モデルを閉ループで鍛え合う「RLAnything」が何を狙い、どう効いたのかを、読み物としてほどきます。
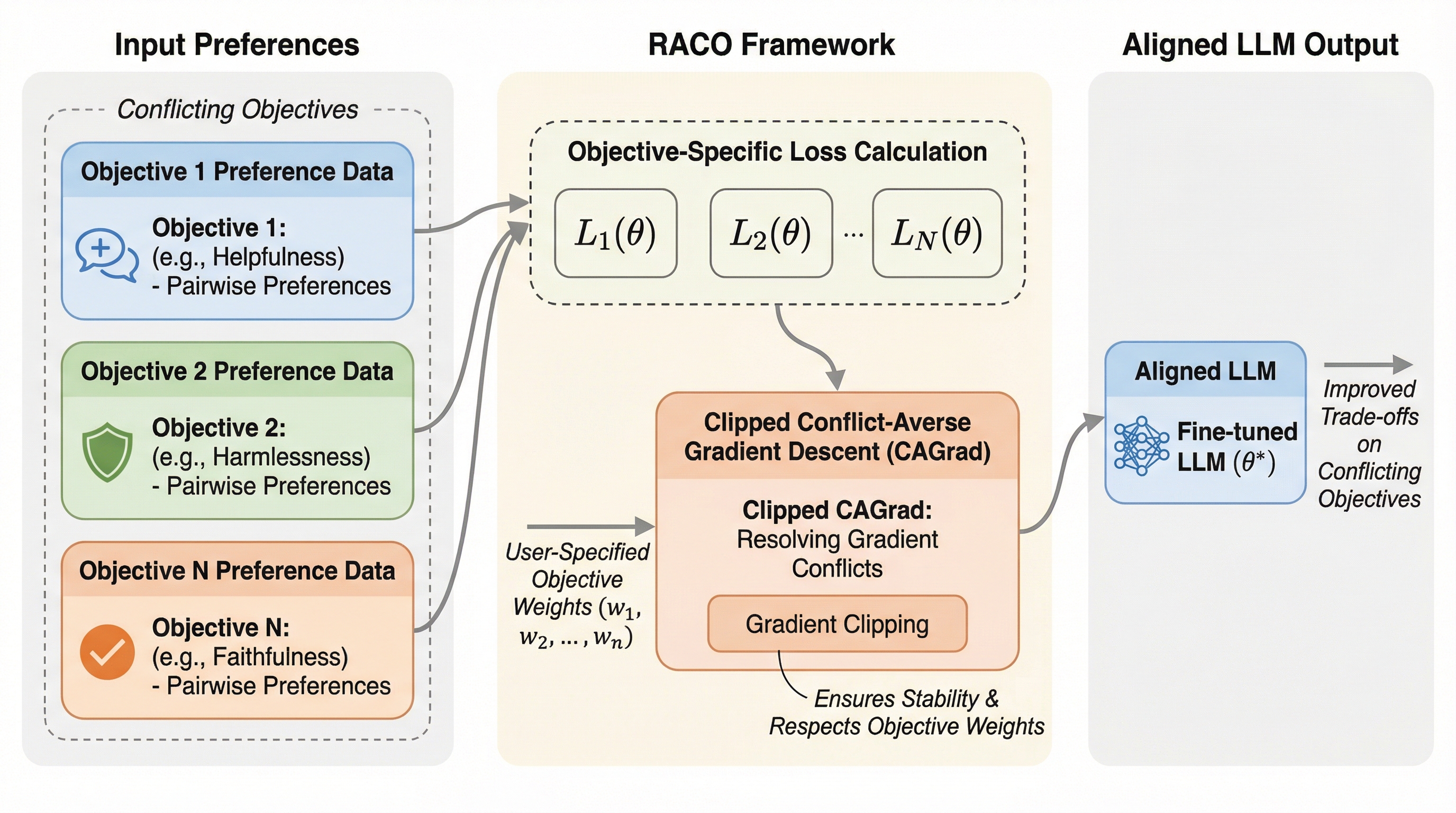
大規模言語モデルを「安全にしつつ、役にも立つ」ように整えるには、結局どこで折り合いをつけるべき? 実はその折り合いは、目的を足し算した瞬間に崩れやすい——学習が不安定になり、トレードオフも悪化しうる。 この記事では、報酬モデルなしで“衝突する目的”をさばく提案「RACO」が何を変えるのかを、筋道立てて追いかけます。
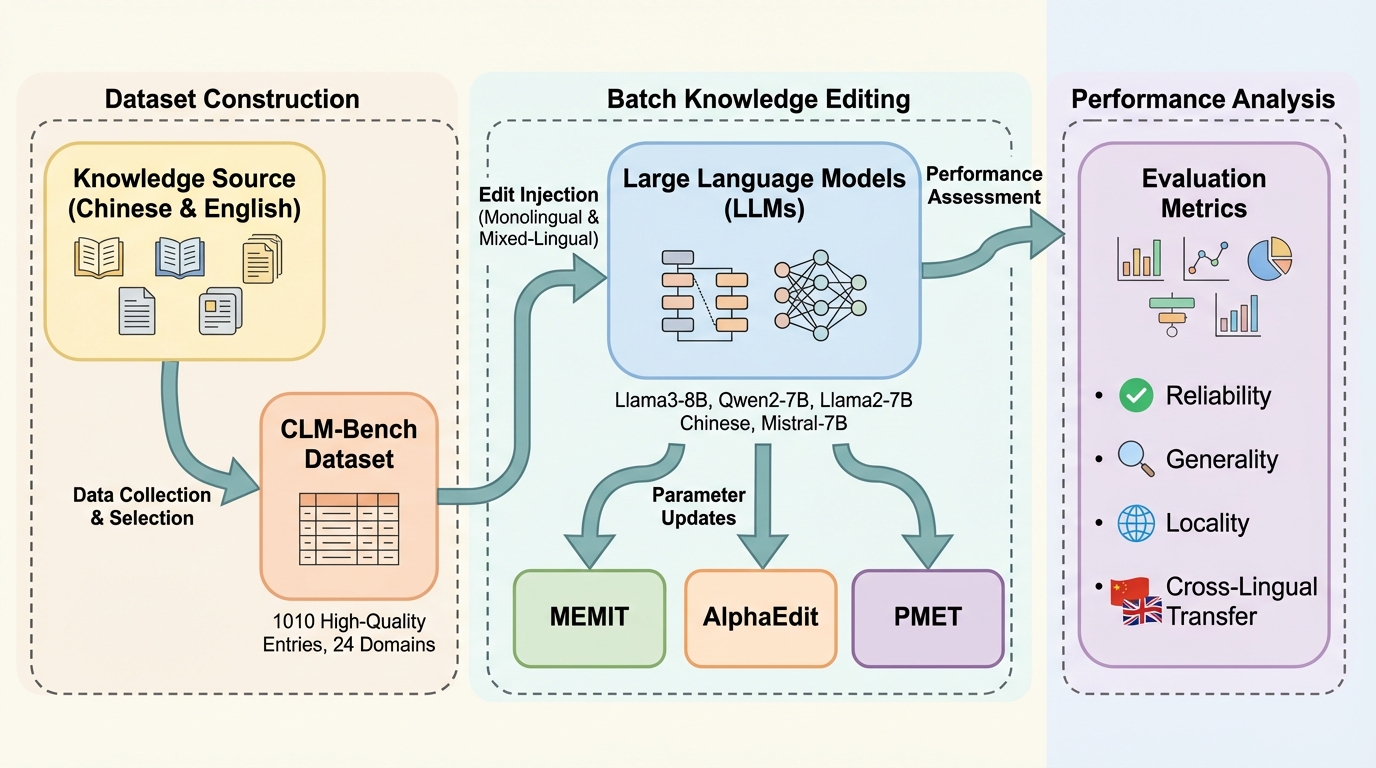
大規模言語モデルの知識編集において、既存の多言語評価枠組みが英語中心の翻訳データに依存し、文化的な固有性や真の知識分布を反映できていないという問題を解決するため、中国語を起点とした文化配慮型の新しいベンチマーク「CLM-Bench」を提案しました。
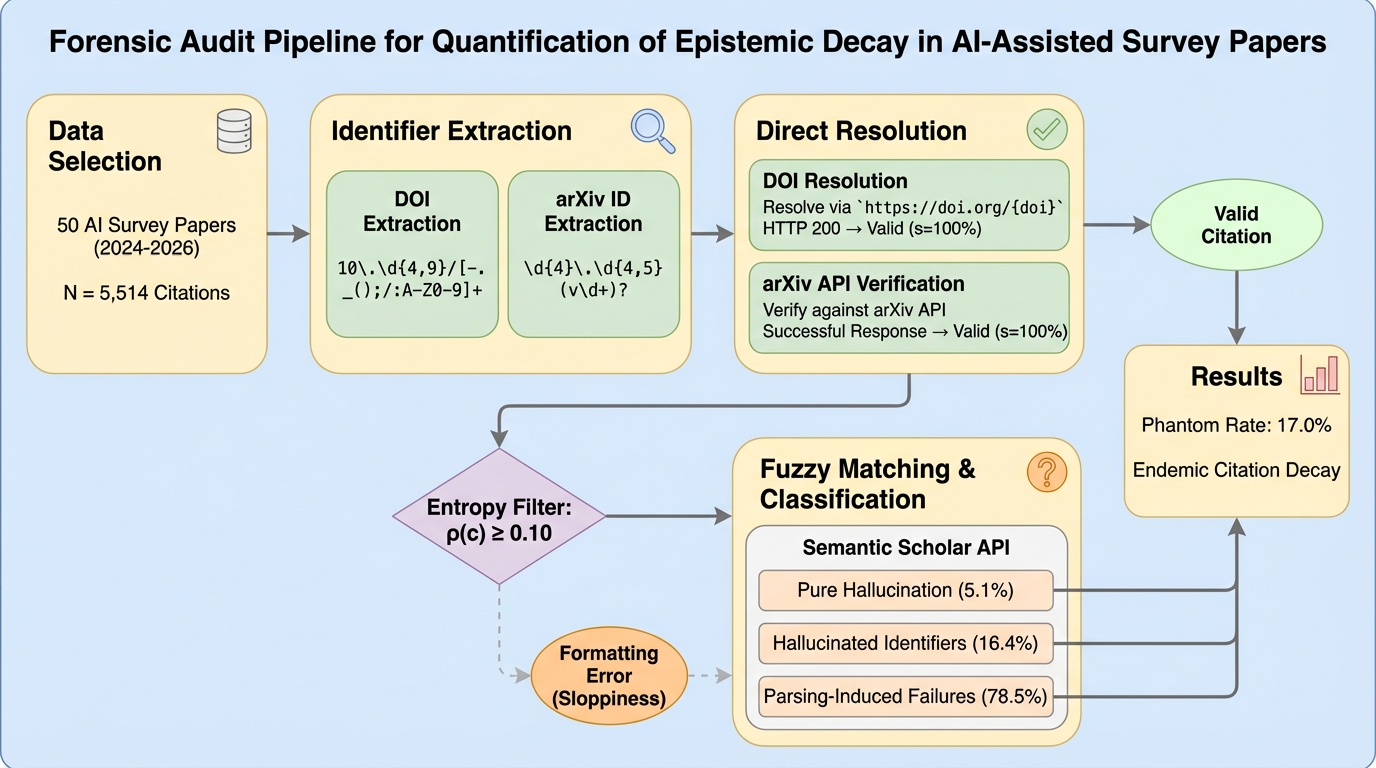
AI分野のサーベイ論文50本(引用総数5,514件)を調査した結果、デジタルオブジェクトとして特定できない「ファントム引用」が17.0%存在し、科学的根拠の連鎖が大規模に損なわれている実態が判明した。 この引用の劣化は、純粋な捏造(5.
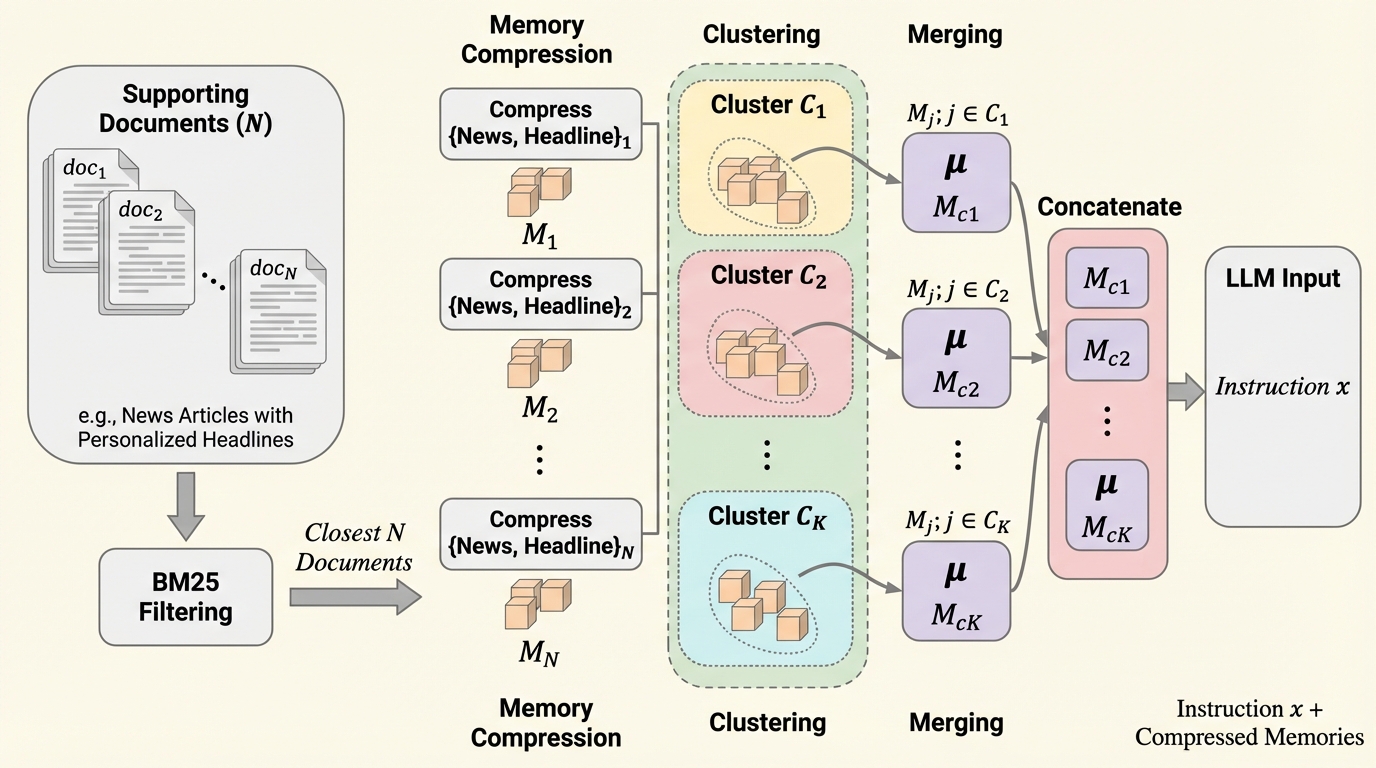
スマートフォンなどのオンデバイス環境で動作する大規模言語モデル(LLM)において、限られたコンテキスト窓を有効活用しながらユーザーの過去の対話履歴をパーソナライズに利用するための、新しいクラスタリング駆動型メモリ圧縮手法が提案されました。
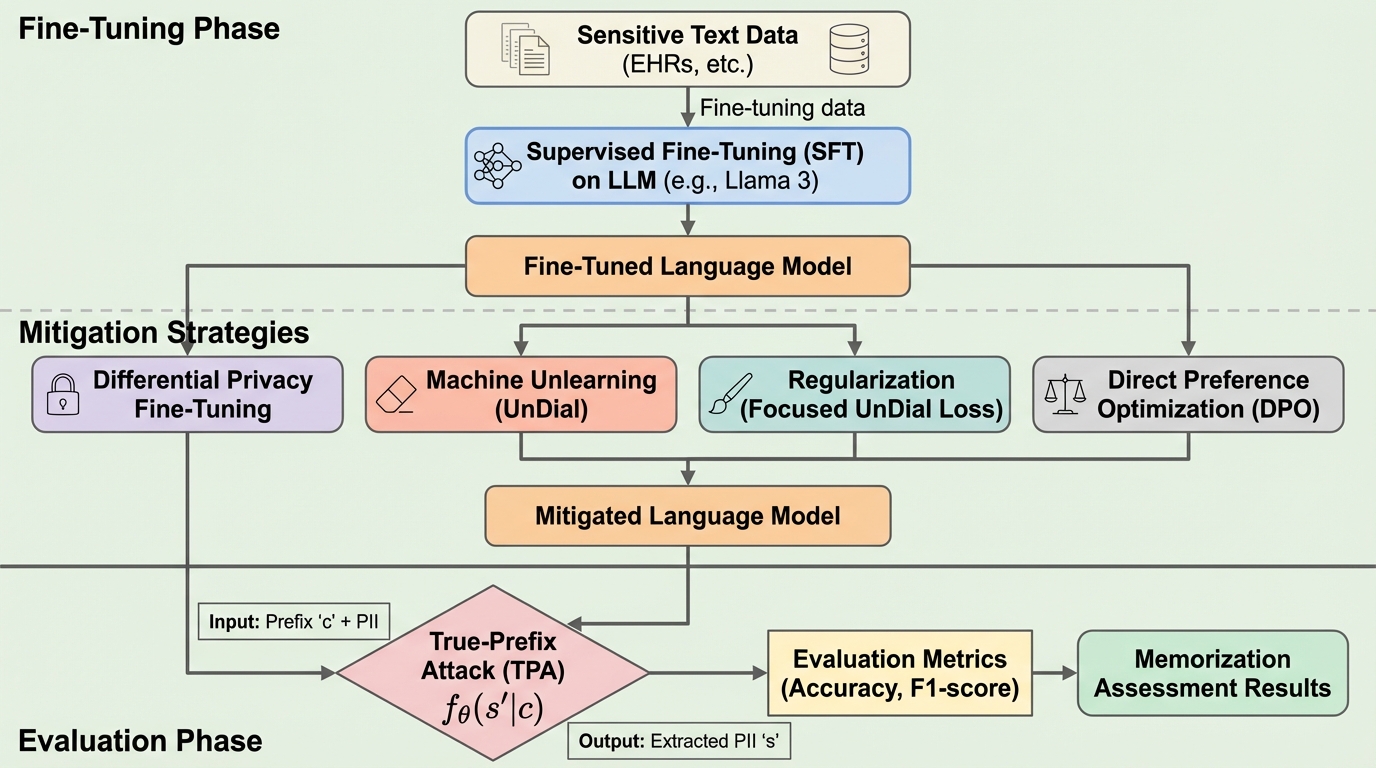
大規模言語モデル(LLM)を特定のデータセットで微調整する際、学習の目的(ターゲット)には含まれず、入力データにのみ存在する個人識別情報(PII)が意図せず記憶され、外部からの攻撃によって抽出可能になるリスクを、合成データと実世界の医療データを用いて体系的に明らかにした。
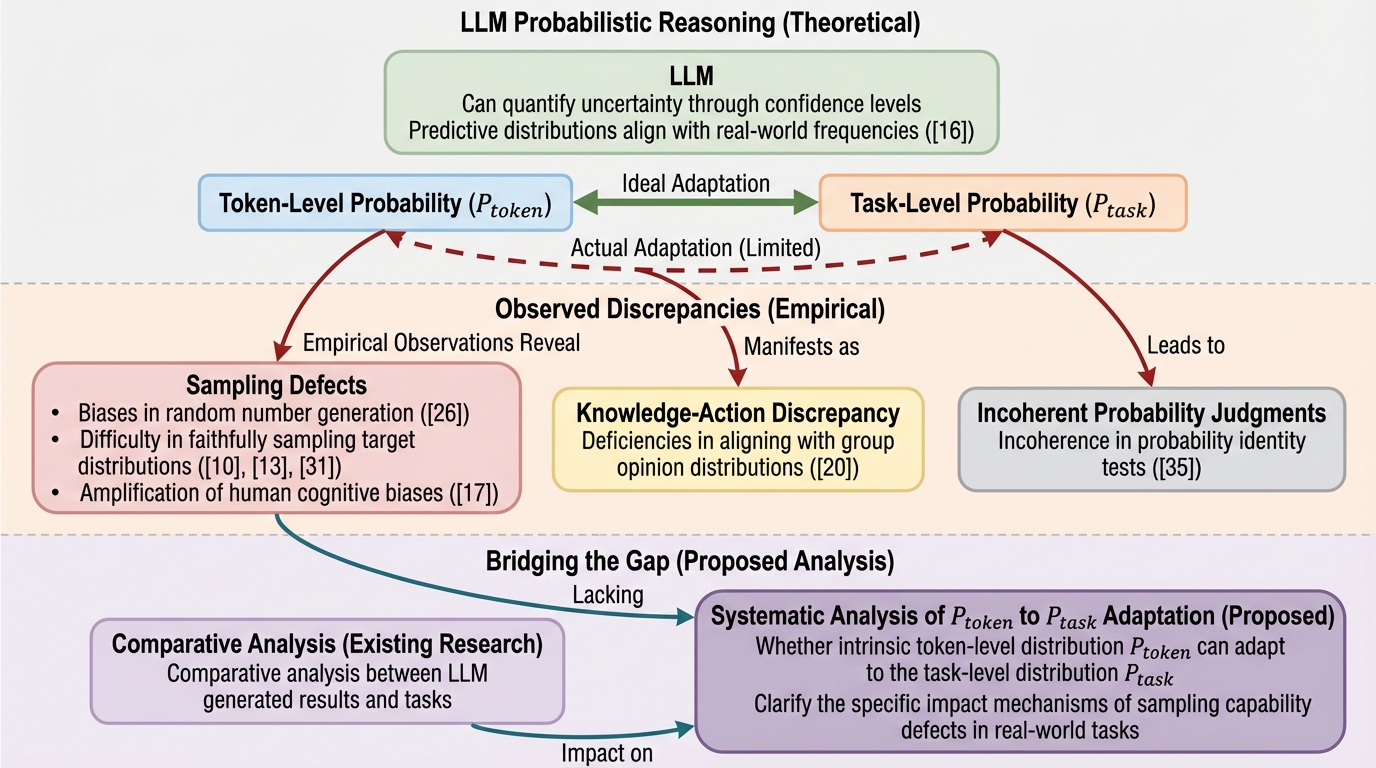
大規模言語モデル(LLM)の次トークン予測確率($P{token}$)とタスク目標分布($P{task}$)の整合性を分析した結果、挙動の異なる2つのモデル群(D-ModelsとE-Models)の存在が明らかになりました。 Qwen-2.5やLlama-3.
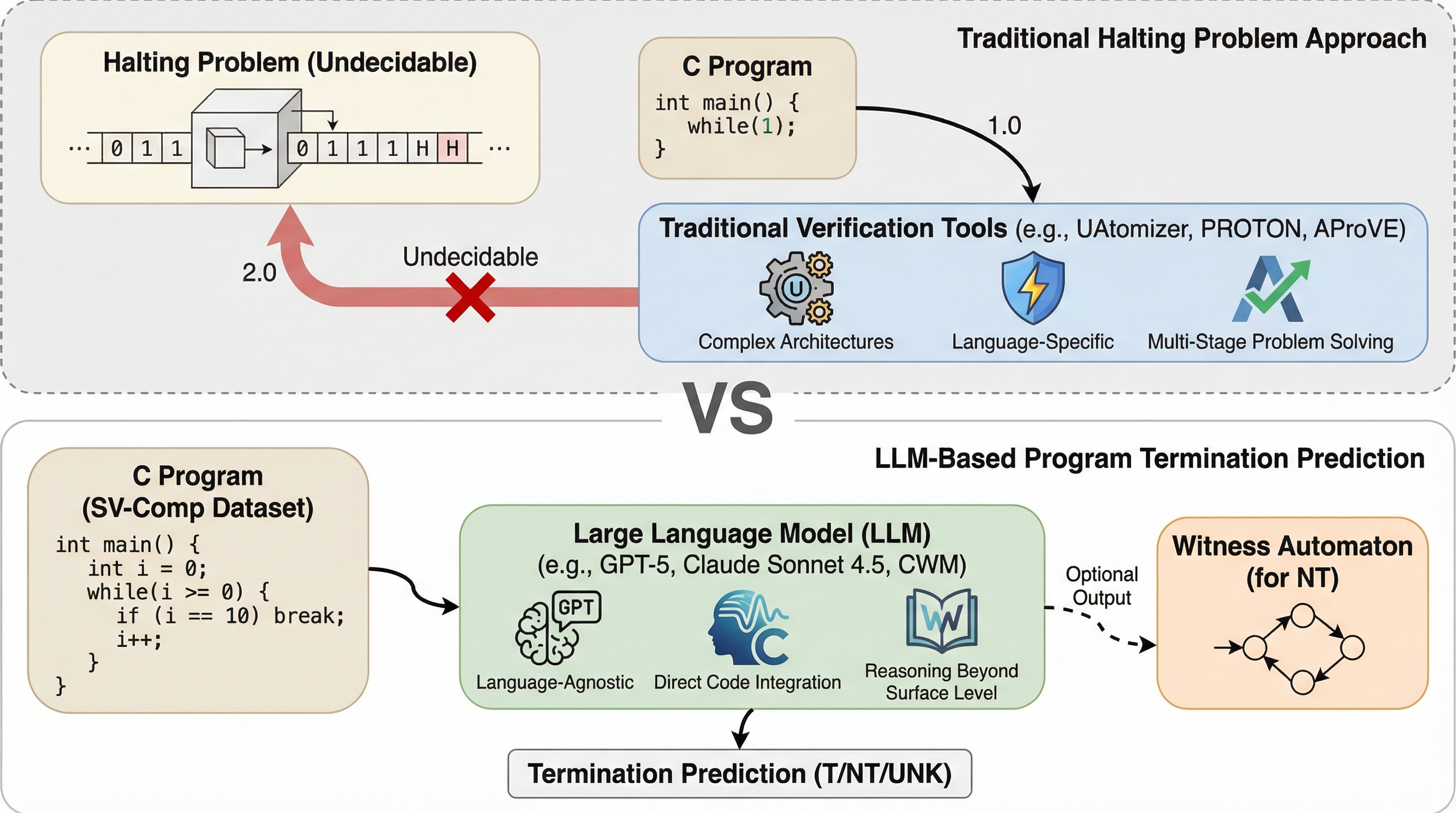
大規模言語モデル(LLM)は、計算機科学の難問である「停止問題」の予測において、専門的な検証ツールに匹敵する極めて高い性能を示した。特にGPT-5やClaude Sonnet-4.5は、国際的なソフトウェア検証コンペティション(SV-Comp 2025)のトップクラスのツールに次ぐスコアを記録し、その推論能力の高さが証明された。 一方で、プログラムが終了しないことの数学的な証明となる「証拠(ウィットネス)」の生成には依然として課題があり、コードの長さや複雑さが増すにつれて予測精度が低下する傾向も確認された。 信頼性を高めるために導入された「テストタイム・スケーリング(TTS)」による合意形成アルゴリズムは、モデルの不確実性を適切に管理し、誤判定によるペナルティを回避してスコアを劇的に向上させる有効な手段であることが明らかになった。
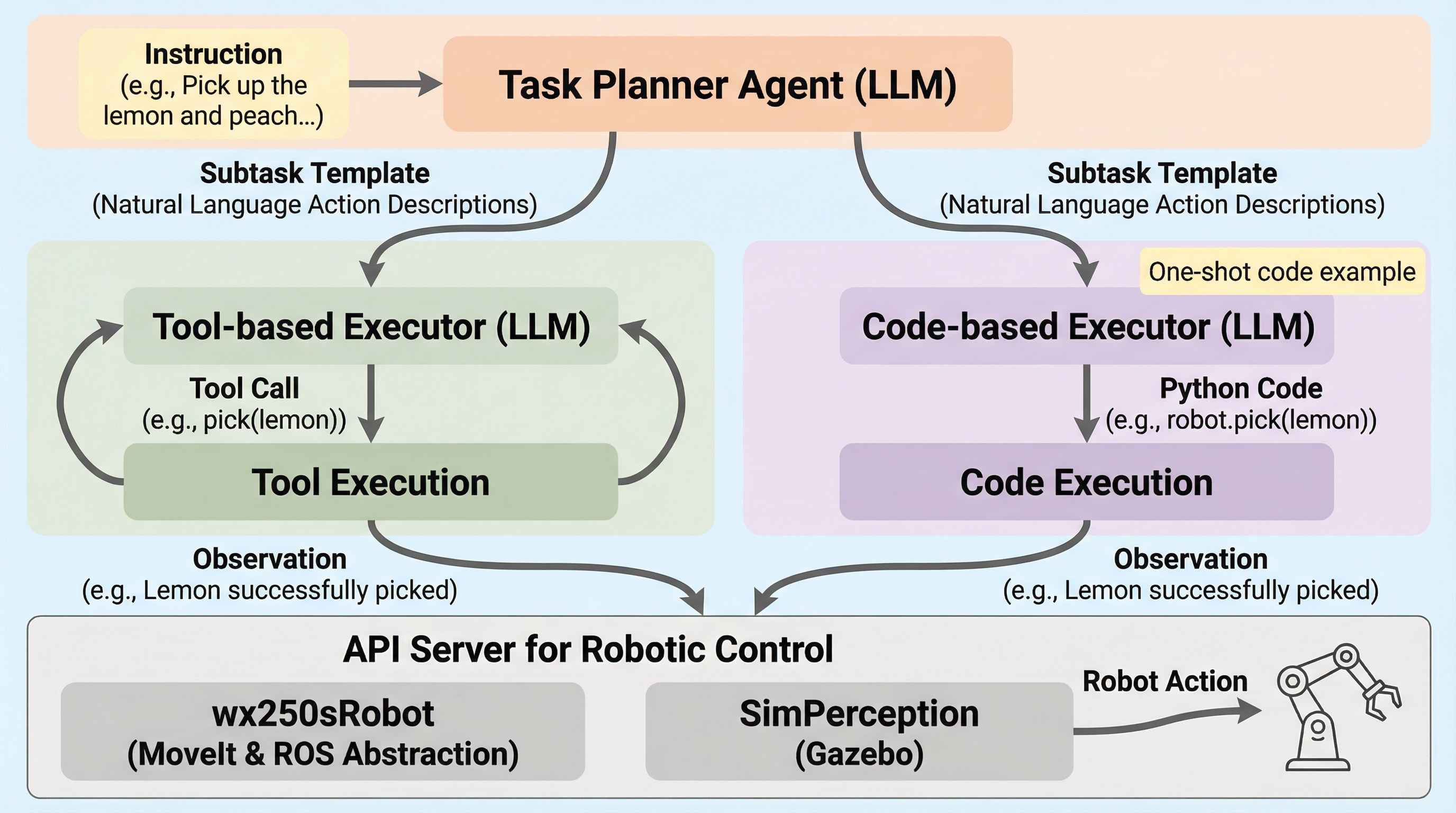
ALRMは、大規模言語モデル(LLM)をロボット操作の計画と実行に統合する新しいエージェント型フレームワークであり、ReAct形式の推論ループを用いることで、実行結果の振り返りと計画の動的な修正を可能にしました。