RE-TRAC:Deep Search Agentsのための再帰的軌跡圧縮
研究エージェントは、なぜ「同じところをぐるぐる回る」のでしょうか? 原因は推論能力ではなく、“探索の形”にある――というのが本論文の出発点です。 この記事では、ReActの直線的な探索を「再帰的に折りたたむ」Re-TRACの狙いと効きどころを、読み物として整理します。
論文図解
TL;DR(結論)
- 提案はRe-TRAC(REcursive TRAjectory Compression for Deep Search Agents)。
- 要点はシンプルで、「探索を1本の物語で終わらせず、複数の探索をまたいで経験を圧縮し、次の探索に引き継ぐ」枠組みです。
- 動きは「走って、まとめて、次に活かす」の反復です。
なぜこの問題か
LLMエージェントは、受け答えするだけの存在から、目的を持って環境で問題解決する存在へ――論文はそうした流れを背景に置きます。 言い換えると、単発の回答品質だけではなく、開いた環境で「探し、集め、判断する」一連の動きそのものが性能になる局面が増えている、という見立てです。 その代表的な枠組みがReActで、推論とツール呼び出しを交互に積み上げ、コンテキストに直列で追加していく設計です。 この直列の積み上げは分かりやすさと実装の素直さを持つ一方で、深い調査のような“寄り道や引き返しが前提”の仕事に対して、構造としての制約が出やすいことも示唆されます。
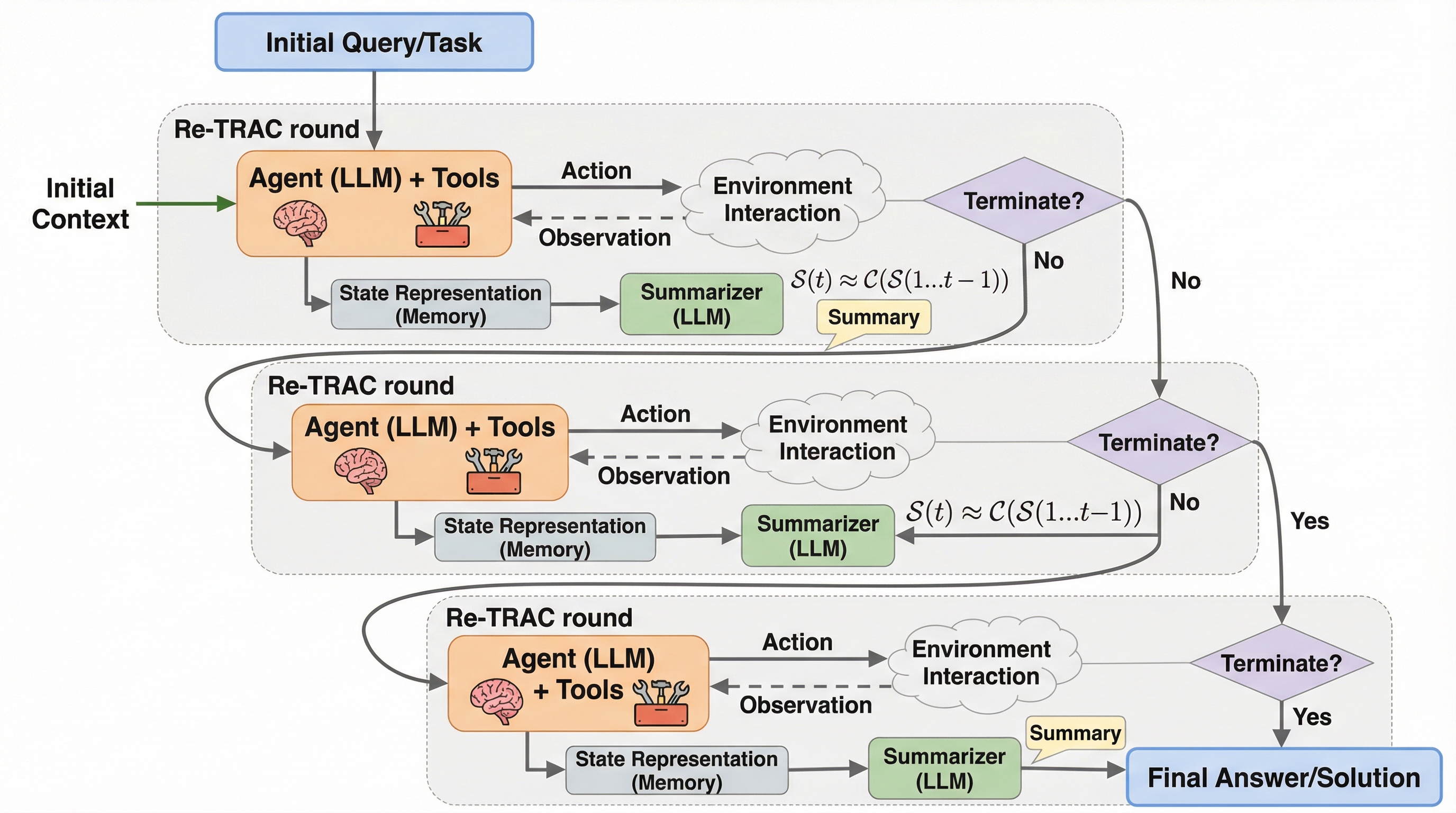
核心:何を提案したのか
提案はRe-TRAC(REcursive TRAjectory Compression for Deep Search Agents)。 要点はシンプルで、「探索を1本の物語で終わらせず、複数の探索をまたいで経験を圧縮し、次の探索に引き継ぐ」枠組みです。 ここで重要なのは、複数回試すこと自体ではなく、“複数回のあいだに何が蓄積されるのか”を明示的に設計対象にする点で、探索を手続きとして進化させようとしています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related