17%のギャップ:AI支援型サーベイ論文における認識的減衰の定量化
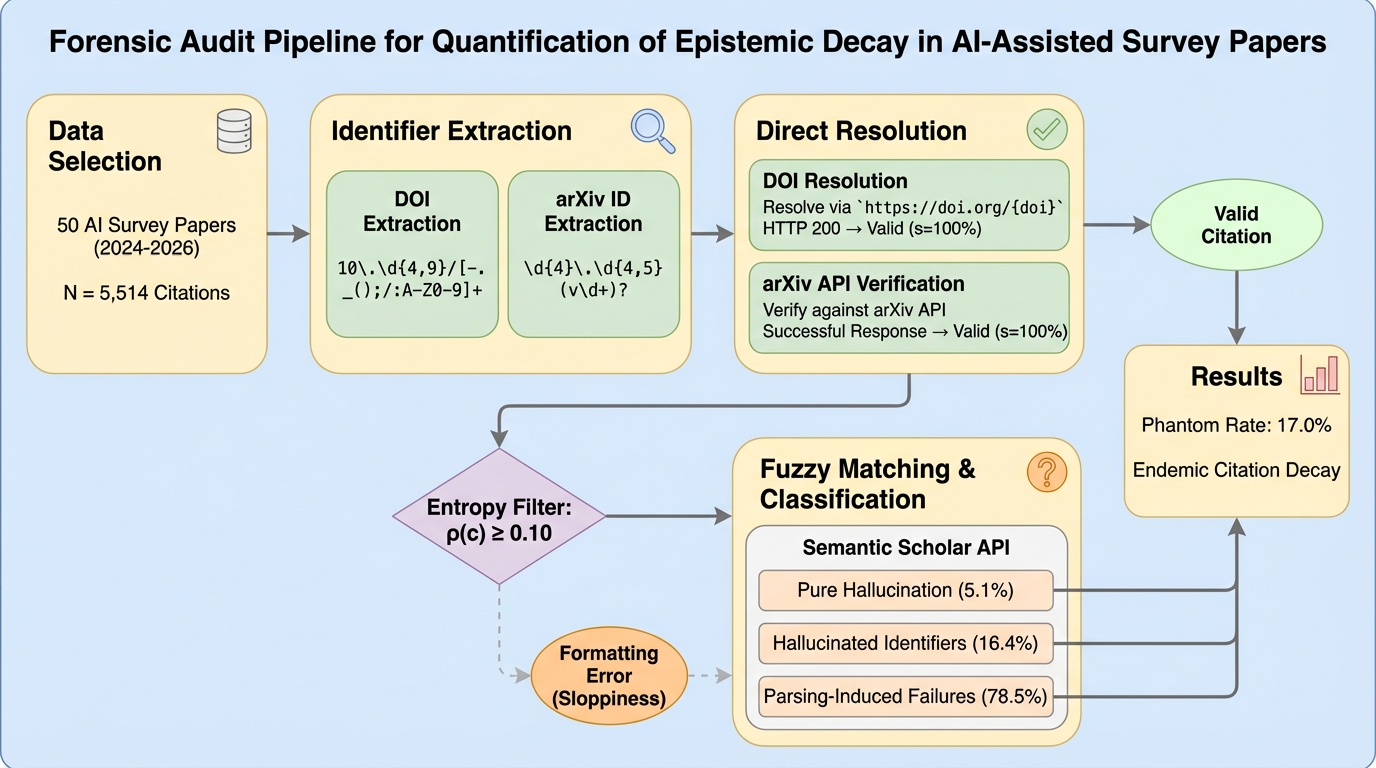
AI分野のサーベイ論文50本(引用総数5,514件)を調査した結果、デジタルオブジェクトとして特定できない「ファントム引用」が17.0%存在し、科学的根拠の連鎖が大規模に損なわれている実態が判明した。 この引用の劣化は、純粋な捏造(5.
TL;DR(結論)
AI分野のサーベイ論文50本(引用総数5,514件)を調査した結果、デジタルオブジェクトとして特定できない「ファントム引用」が17.0%存在し、科学的根拠の連鎖が大規模に損なわれている実態が判明した。 この引用の劣化は、純粋な捏造(5.1%)よりも、実在する論文タイトルに偽の識別子を付与する「怠惰な研究助手」的な振る舞いや、PDF抽出時の構文エラー(78.5%)によって主に引き起こされている。 2024年9月から2026年1月までの期間において、このエラー率は月間+0.07ポイントという極めて微増な推移を示しており、AIによる高エントロピーな引用慣行が分野の恒常的な特徴として定着していることが示唆された。
なぜこの問題か
現代科学の構造は、証拠の連鎖(Chain of Custody)に完全に依存している。学者が何らかの主張を行う際、引用はその根拠となる証拠への法医学的なリンクとして機能し、コミュニティが先行研究を検証、複製、発展させることを可能にする。何世紀にもわたり、この台帳は手作業で維持されてきた。しかし、特に人工知能(AI)という極めて活動的な分野における科学的統合の生成速度は、人間が支援なしに査読できる能力を超えて加速している。この情報の洪水に対処するため、研究コミュニティは文献レビューの作業を大規模言語モデル(LLM)に静かに外部委託するようになった。 この移行は、新たな形式の認識論的リスクをもたらしている。生成AIに関する初期の批判は、存在しない論文を捏造する「ハルシネーション(幻覚)」に焦点を当てていたが、より狡猾なエラーモードが出現している。現在のAIツールは「怠惰な研究助手」として機能しているのではないかという仮説が立てられる。つまり、意味的な一貫性を維持するために実在する重要な論文のタイトルは正しく特定するものの、それらを見つけるために必要な事務的なメタデータを捏造するという振る舞いである。…
核心:何を提案したのか
本研究は、2024年9月から2026年1月の間に発表されたAI分野のサーベイ論文を対象とした法医学的監査を提案し、実行したものである。具体的には、5,514件の個別の引用を含む50本のサーベイ論文を分析し、各引用をDOI解決、APIベースのメタデータ取得、および曖昧テキストマッチングを組み合わせたハイブリッド検証パイプラインにかけた。単なるエラーのカウントを超えて、修復可能な「不注意(Sloppiness)」と、修復不可能な「ファントム(Phantoms)」を区別し、さらにファントムを3つの診断的失敗モードに分類した。 この研究の核心は、AI支援による執筆が科学文献に導入する「情報の分散(エントロピー)」を定量化することにある。調査の結果、17.0%という持続的なファントム率が検出された。これはランダムな変動ではなく、減衰の平衡状態であると考えられる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related