オンデバイス大規模言語モデルのためのクラスタリング駆動型メモリ圧縮
スマートフォンなどのオンデバイス環境で動作する大規模言語モデル(LLM)において、限られたコンテキスト窓を有効活用しながらユーザーの過去の対話履歴をパーソナライズに利用するための、新しいクラスタリング駆動型メモリ圧縮手法が提案されました。
TL;DR(結論)
スマートフォンなどのオンデバイス環境で動作する大規模言語モデル(LLM)において、限られたコンテキスト窓を有効活用しながらユーザーの過去の対話履歴をパーソナライズに利用するための、新しいクラスタリング駆動型メモリ圧縮手法が提案されました。 この手法は、多数のメモリを意味的な類似性に基づいてグループ化し、各クラスタ内で情報を統合することで、単純な連結によるコンテキストの枯渇や、一律の平均化による情報の衝突という従来手法の課題を同時に解決し、情報の密度と一貫性を高めることに成功しています。 実験では、従来の連結手法と比較してメモリトークン数を半分に削減しながらも、ニュースの見出し生成やツイートの言い換えなどのタスクで同等以上の精度を達成し、リソース制約の厳しいデバイス上での高度なパーソナライズの実現可能性を証明しました。
なぜこの問題か
大規模言語モデル(LLM)は、質問回答、要約、翻訳、文法修正といった多様なタスクで優れた能力を発揮していますが、個々のユーザーに最適化された応答を生成するためには、過去のやり取りやユーザーの背景情報を「メモリ」として活用するパーソナライズが不可欠です。しかし、このメモリの活用は、特にスマートフォンやエッジデバイスなどのオンデバイス環境において深刻な技術的課題を引き起こします。オンデバイスLLMは通常、10億から30億程度のパラメータを持つ比較的小規模なモデルであり、クラウド上の巨大なモデルに比べて、長期的な情報を保持し処理する能力に物理的な限界があります。 さらに、これらのモデルが一度に処理できる情報の長さである「コンテキスト窓」は、一般的に1,024から2,048トークン程度と非常に狭く設計されています。パーソナライズのために過去の履歴をそのまま入力プロンプトに連結するという単純な戦略をとると、すぐにこの制限を超えてしまい、肝心のユーザーの指示や新しい情報を入力するスペースがなくなってしまいます。…
核心:何を提案したのか
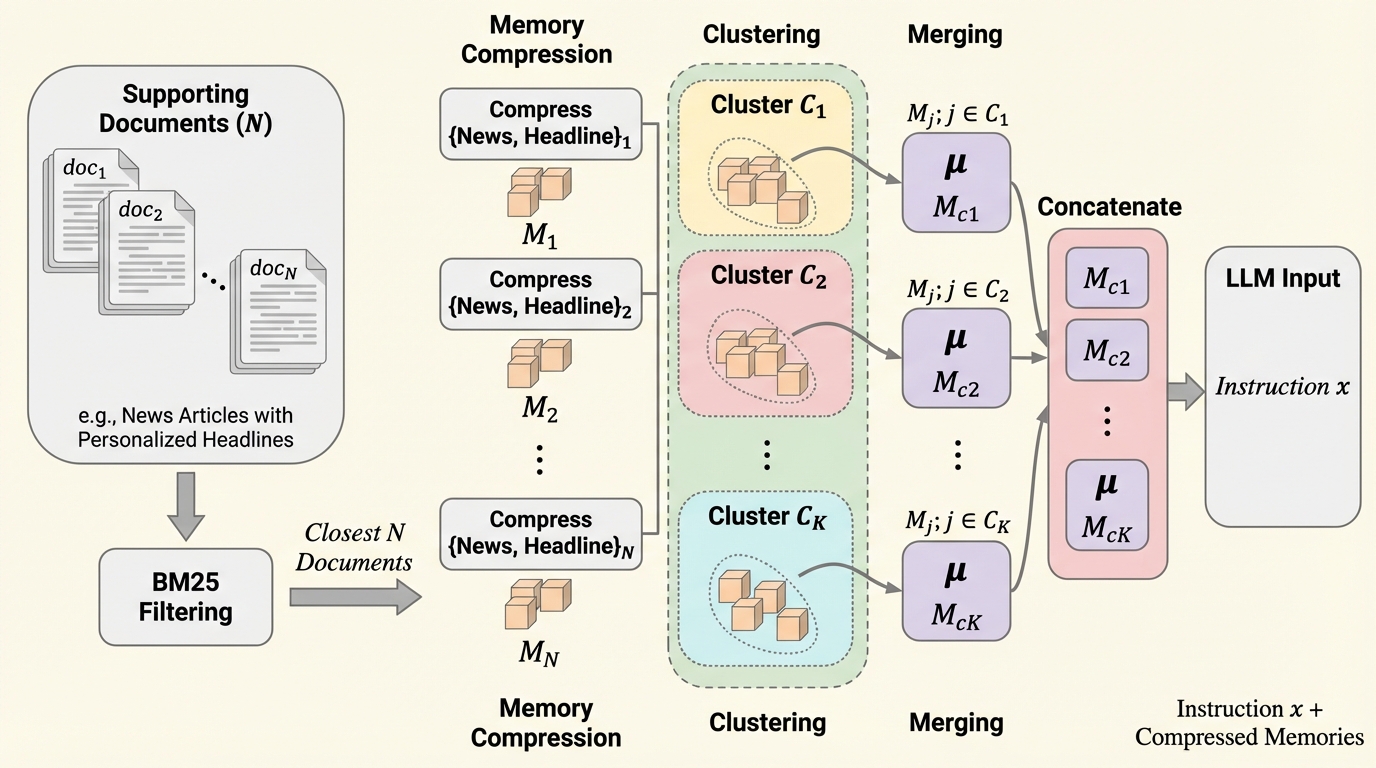
本研究の核心は、オンデバイスでのパーソナライズに特化した「クラスタリング駆動型メモリ圧縮フレームワーク」の提案にあります。この手法は、単に情報を削るのではなく、情報の構造を整理することで圧縮効率を高めるというアプローチを採用しています。具体的には、まず膨大な過去のデータから現在の指示に最も関連性の高いテキストメモリを抽出し、それらを個別にメモリトークンへとエンコードします。その後、得られた複数のメモリ表現を類似性に基づいていくつかの「クラスタ」にグループ化し、各クラスタの内部で情報をマージ(統合)するというプロセスを導入しました。 このクラスタリングベースのアプローチにより、内容が似ているメモリ同士は一つにまとめられ、内容が異なるメモリ同士は別々のクラスタとして保持されるようになります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related