D-ModelsとE-Models:大規模言語モデルのサンプリング挙動における多様性と安定性のトレードオフ
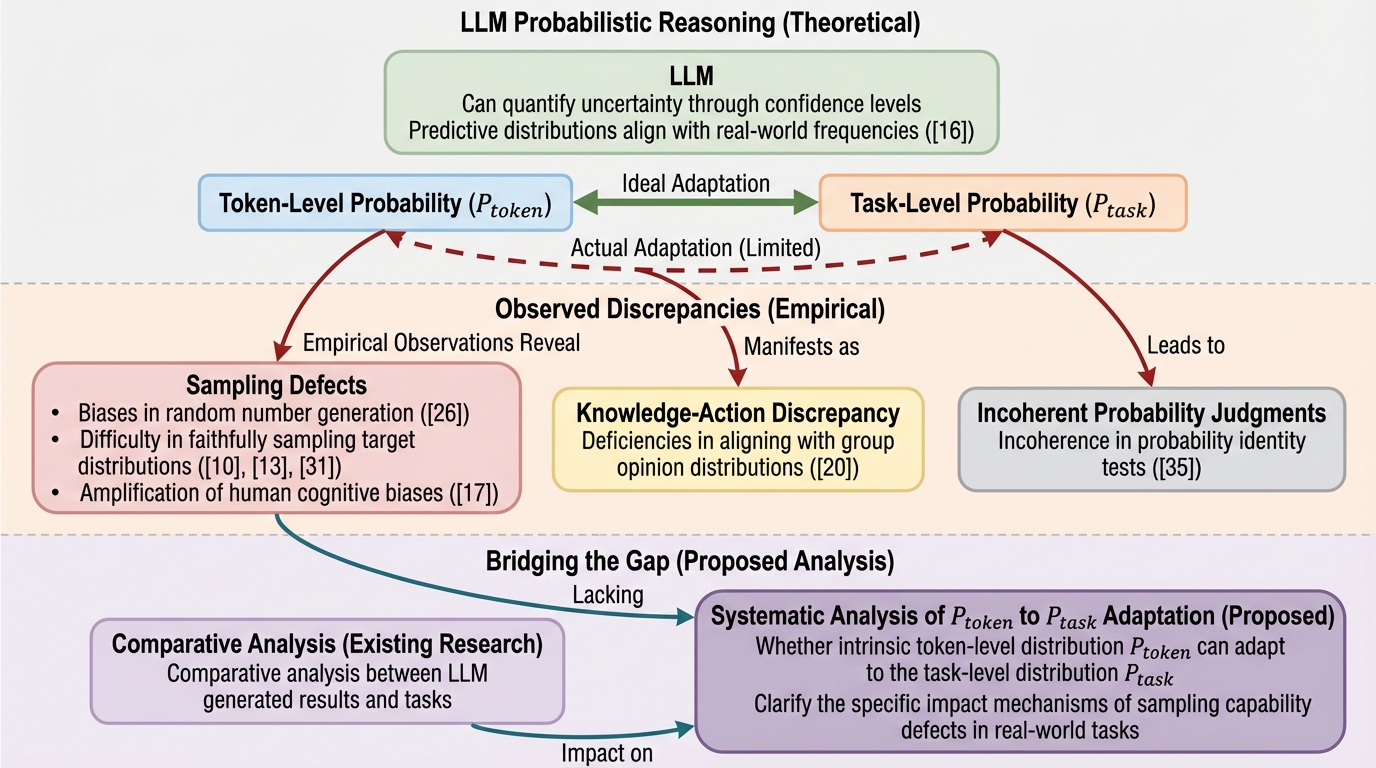
大規模言語モデル(LLM)の次トークン予測確率($P{token}$)とタスク目標分布($P{task}$)の整合性を分析した結果、挙動の異なる2つのモデル群(D-ModelsとE-Models)の存在が明らかになりました。 Qwen-2.5やLlama-3.
TL;DR(結論)
大規模言語モデル(LLM)の次トークン予測確率($P{token}$)とタスク目標分布($P{task}$)の整合性を分析した結果、挙動の異なる2つのモデル群(D-ModelsとE-Models)の存在が明らかになりました。 Qwen-2.5やLlama-3.1などのD-Modelsは特定のトークンに確率が集中する決定論的な挙動を示し、Mistral-SmallやGPT-4oなどのE-Modelsは目標分布に沿った探索的なサンプリングを行う傾向があります。 このモデル間の特性の違いは、コード生成や推薦システムといった実務タスクにおける多様性と安定性のトレードオフに直結しており、用途に応じたモデル選択と確率バイアスの補正が重要であることを示唆しています。
なぜこの問題か
現代のインターネットインフラにおいて、大規模言語モデル(LLM)は単なるテキスト生成器を超え、コード生成の補助や、検索結果、ニュースフィード、推薦システムにおける情報の露出を制御する中心的な役割を担うようになっています。これらのシステムがどのコンテンツをどの程度の頻度でユーザーに表示するかを決定する際、モデルは実質的に膨大な候補アイテムの分布からサンプリングを行っています。このサンプリング挙動は、ユーザーがどのような情報を目にし、何を信じ、最終的にどのように行動するかという社会的な意思決定に直接的な影響を及ぼします。そのため、LLMのサンプリングプロセスが監査可能であり、その挙動が説明可能であることは、責任ある技術開発とアルゴリズムの透明性を確保する上で極めて重要な課題となっています。 LLMの能力の根幹は、大規模なテキストデータに潜在する複雑な確率分布を学習し、モデル化する能力にあります。具体的には、既存のテキストシーケンス(コンテキスト)が与えられたとき、モデルは次に来る可能性が最も高いトークンを予測することを学習します。…
核心:何を提案したのか
本研究では、LLMの生成能力を確率論的な視点から詳細に調査し、モデルのサンプリング挙動における「D-Models(決定論的モデル)」と「E-Models(探索的モデル)」という2つの対照的なカテゴリーを定義・提案しました。これら2つのグループは、内部的なトークン確率分布($P{token}$)の特性と、タスク目標分布($P{task}$)への適合の仕方に明確かつ系統的な違いがあることが示されました。 D-Models(Deterministic Models)は、生成の各ステップにおいて特定のトークンに対して極めて高い確率(1.0に近い値)を割り当て、他のトークンの確率をほぼゼロにする傾向があります。これにより、グローバルな計画に基づいた決定論的な挙動を示しますが、ステップごとの確率の変動が大きく、タスク目標分布との微細な一致度は低いという特徴があります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related