RLAnything:完全に動的なRLシステムで環境・方策・報酬モデルを構築する
自然言語で動くエージェントは、なぜ「最後の正解・不正解」だけでは育ちにくいのか? 答えは、長い軌跡を進むほど“途中の学びの手がかり”が痩せていくからです。 この記事では、環境・方策・報酬モデルを閉ループで鍛え合う「RLAnything」が何を狙い、どう効いたのかを、読み物としてほどきます。
論文図解
TL;DR(結論)
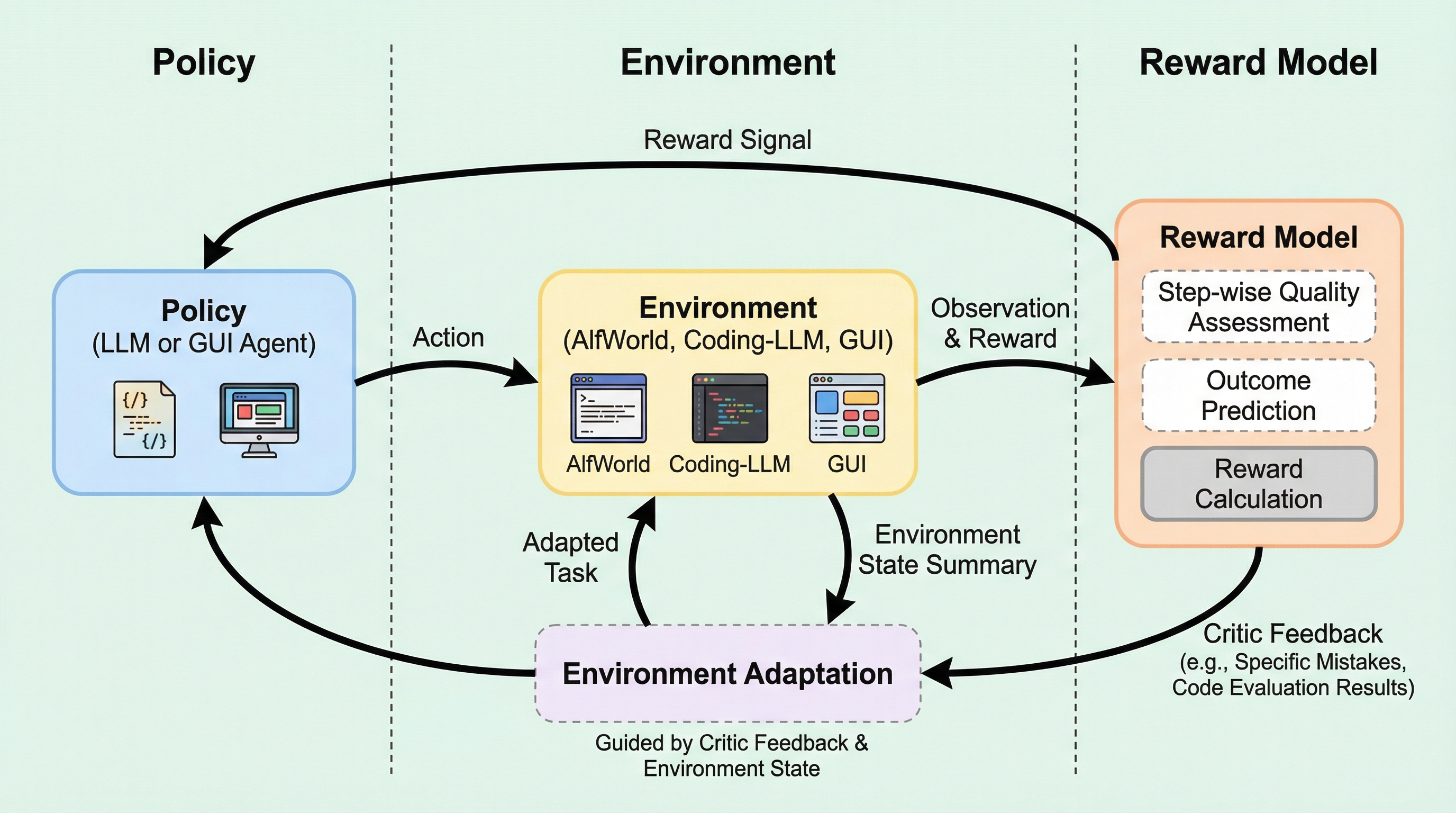
- RLAnythingは、環境・方策(policy)・報酬モデル(reward model)を閉ループで同時に最適化し、学習信号を増幅させる枠組みです。固定された部品を順番に改良するのではなく、相互に影響させながら“育て合う”前提を置きます。
- 途中(step-wise)と最終結果(outcome)の統合フィードバック、整合性(consistency)にもとづく報酬モデル学習、批評(critic)を使った自動環境適応が柱です。長い軌跡で生じる「評価の手がかり不足」を、設計として埋めにいきます。
なぜこの問題か
強化学習で言語モデルやエージェントを伸ばす文脈では、RLVR(verifiable rewards)という考え方が出てきます。正解が検証できる「結果の報酬」を使えるのは強い。けれど論文が問題視するのは、用途が「単発の質問応答」を超えた瞬間です。ここでの焦点は、タスクが長く・反復的になるほど、従来の“結果だけを見る”設計が急に心許なくなる点にあります。
核心:何を提案したのか
論文が提案するのは、RLAnythingという強化学習フレームワークです。ポイントは「完全に動的なRLシステム」として、環境・方策・報酬モデルを閉ループ最適化で“鍛え合う”構造にあります。ここでの“動的”は、単にデータが増えるという意味ではなく、学習の条件(環境)や学習信号(報酬モデル)が相互作用で変わり続ける、という含意を持っています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related