CLM-Bench: 知識編集における大規模言語モデルの言語間不整合のベンチマークと分析
大規模言語モデルの知識編集において、既存の多言語評価枠組みが英語中心の翻訳データに依存し、文化的な固有性や真の知識分布を反映できていないという問題を解決するため、中国語を起点とした文化配慮型の新しいベンチマーク「CLM-Bench」を提案しました。
TL;DR(結論)
大規模言語モデルの知識編集において、既存の多言語評価枠組みが英語中心の翻訳データに依存し、文化的な固有性や真の知識分布を反映できていないという問題を解決するため、中国語を起点とした文化配慮型の新しいベンチマーク「CLM-Bench」を提案しました。 このベンチマークを用いた検証により、特定の言語で行った知識の修正が他の言語に伝播しない「言語間不整合(Cross-lingual Misalignment)」という現象が明らかになり、中国語と英語の編集ベクトルがほぼ直交する独立した部分空間に存在していることが判明しました。 混合言語による同時編集は、各言語の編集効果を線形に加算する性質を持つものの、言語間の相乗効果を生むわけではなく、現在の知識編集手法が多言語間での知識共有や一貫性の維持において根本的な課題を抱えていることを幾何学的な視点から実証しました。
なぜこの問題か
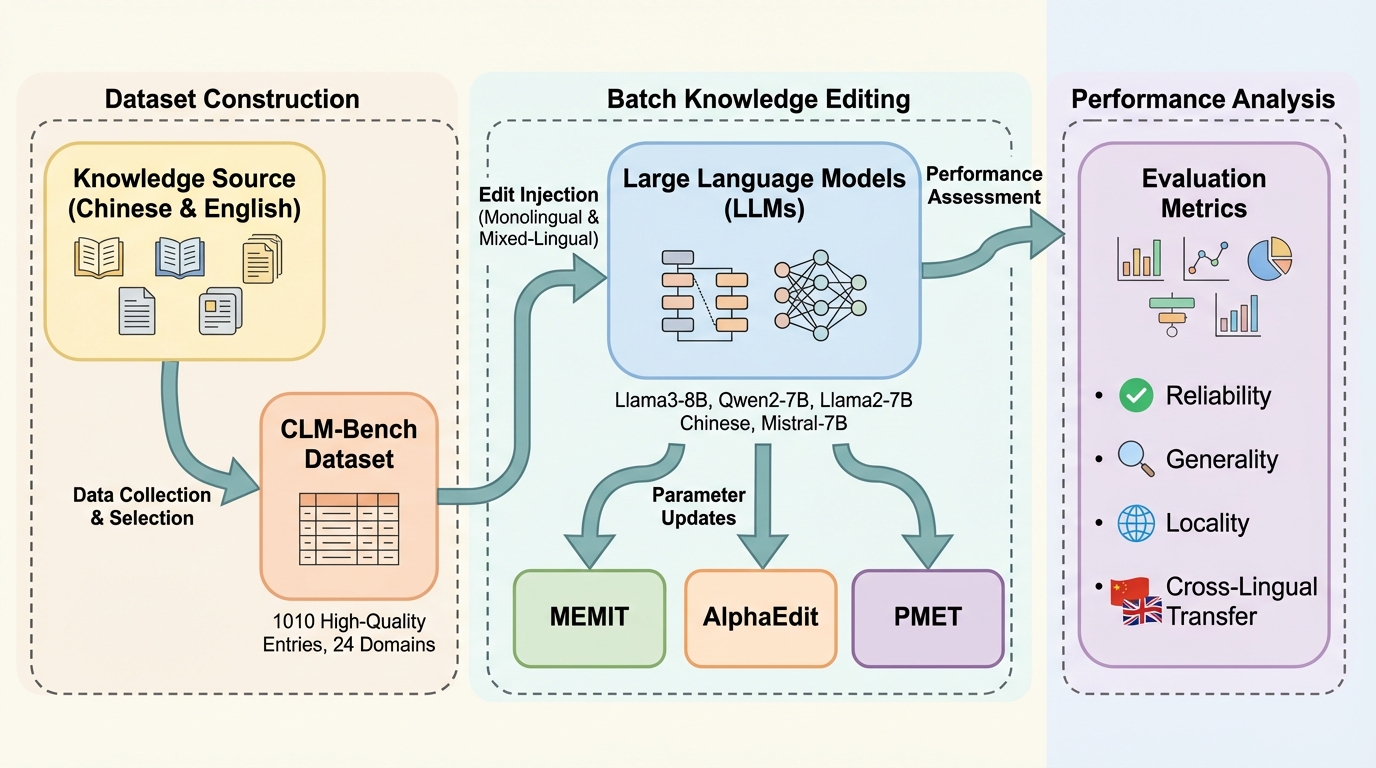
大規模言語モデル(LLM)は、膨大な世界の知識を記憶し活用する能力を持っていますが、そのパラメータに蓄積された知識は静的なものであるという重大な限界があります。世界が常に変化し続ける中で、モデル内の事実は時間とともに古くなったり、誤ったものになったりするため、再学習の膨大なコストをかけずに特定の事実を精密に修正する「知識編集(Knowledge Editing)」という手法が注目されています。しかし、これまでの知識編集の研究は主に英語という単一言語の設定に集中しており、多言語環境における知識の更新については十分に解明されていませんでした。 特に、多言語知識編集(MKE)の評価において、既存のベンチマークには大きな偏りがあることが指摘されています。従来のデータセットの多くは、英語中心のデータを機械的に他の言語(例えば中国語)へ翻訳することで構築されてきました。このようなアプローチでは、翻訳特有の不自然な表現(翻訳調)が混入するだけでなく、対象言語の文化に固有のエンティティ(中国の成語や地元の著名人など)が無視される傾向にあります。…
核心:何を提案したのか
本研究では、言語間での知識編集の整合性を厳密に評価・分析するための包括的なフレームワーク「CLM-Bench(Cross-Lingual Misalignment Benchmark)」を提案しました。このベンチマークの最大の特徴は、従来の英語起点ではなく、中国語を起点とした「ネイティブ・チャイニーズ・ファースト」の手法で構築されている点にあります。これにより、翻訳による不自然さを排除し、中国の文化圏に深く根ざした高品質な知識ペアを評価に組み込むことが可能になりました。 CLM-Benchは、歴史、文学、科学、社会、地理、生物といった広範な分野を網羅する1,010個の高品質な「CounterFact(反事実)」ペアで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related