相反する目的に対する報酬なしアライメント
大規模言語モデルを「安全にしつつ、役にも立つ」ように整えるには、結局どこで折り合いをつけるべき? 実はその折り合いは、目的を足し算した瞬間に崩れやすい——学習が不安定になり、トレードオフも悪化しうる。 この記事では、報酬モデルなしで“衝突する目的”をさばく提案「RACO」が何を変えるのかを、筋道立てて追いかけます。
論文図解
TL;DR(結論)
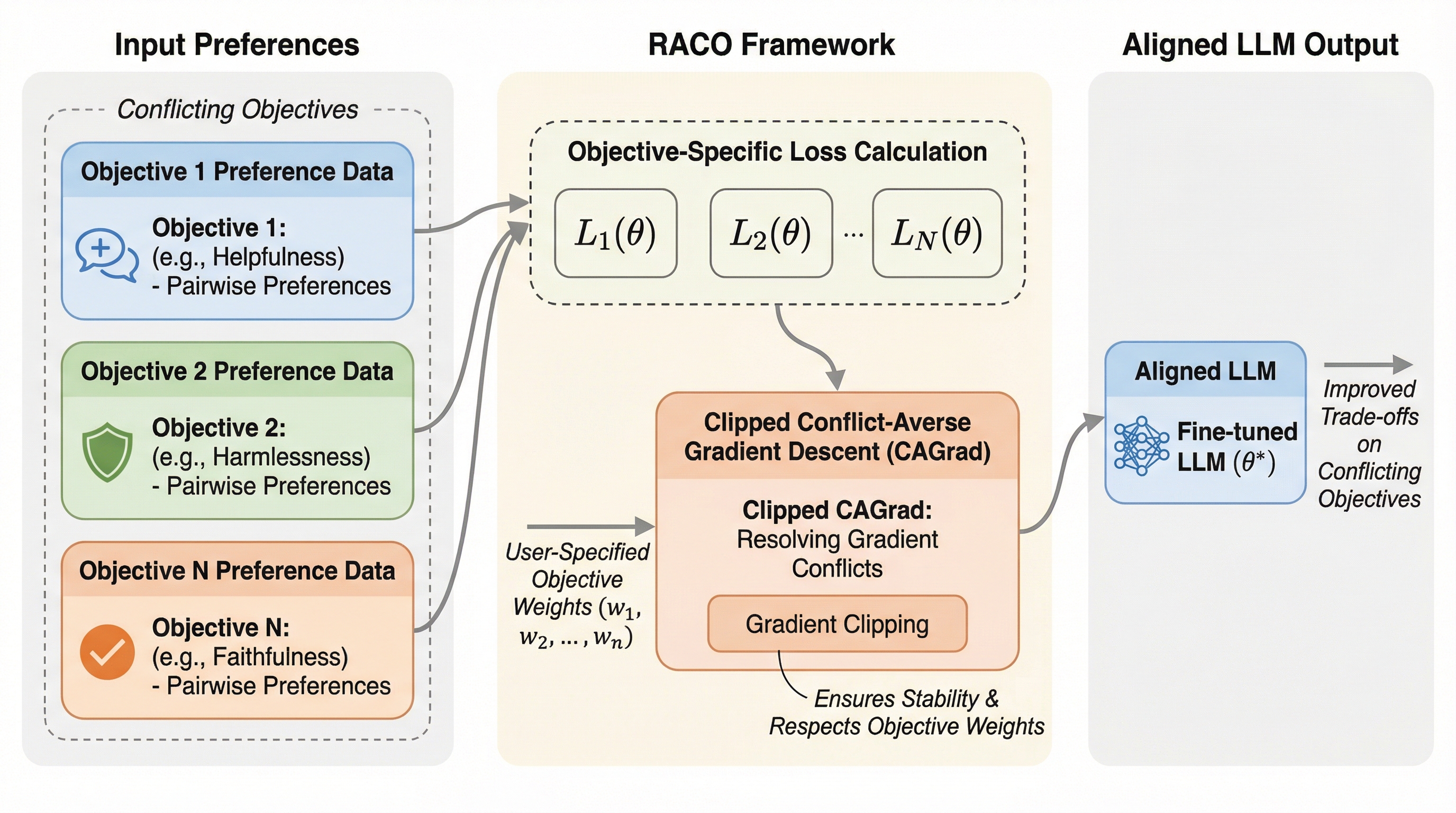
- 論文の第一の貢献は、Reward-free Alignment framework for Conflicted Objectives(RACO)の提案です。
- ポイントは、明示的な報酬モデルに頼らず、ペアワイズの嗜好データを直接使って、複数目的のアラインメントを進めるところにあります。
- ここでの“前提の選び方”が重要です。
なぜこの問題か
LLMを人間の好みに合わせる「直接アラインメント」は、近年ますます使われています。実運用では、出力が「信頼できる」「役に立つ」「安全である」ことが求められるからで、モデルの能力だけでなく“振る舞いの質”がそのまま価値に直結します。だからこそ、学習手順の設計そのものが、実装上の工夫ではなく中心課題になっていきます。
核心:何を提案したのか
論文の第一の貢献は、Reward-free Alignment framework for Conflicted Objectives(RACO)の提案です。ポイントは、明示的な報酬モデルに頼らず、ペアワイズの嗜好データを直接使って、複数目的のアラインメントを進めるところにあります。ここでの“直接”は、目的のスカラー化を先にやってしまうのではなく、嗜好ペアという入力の形を保ったまま学習の更新を組み立てる、という態度に近いです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related