微調整された言語モデルにおける機密情報の意図しない記憶
大規模言語モデル(LLM)を特定のデータセットで微調整する際、学習の目的(ターゲット)には含まれず、入力データにのみ存在する個人識別情報(PII)が意図せず記憶され、外部からの攻撃によって抽出可能になるリスクを、合成データと実世界の医療データを用いて体系的に明らかにした。
TL;DR(結論)
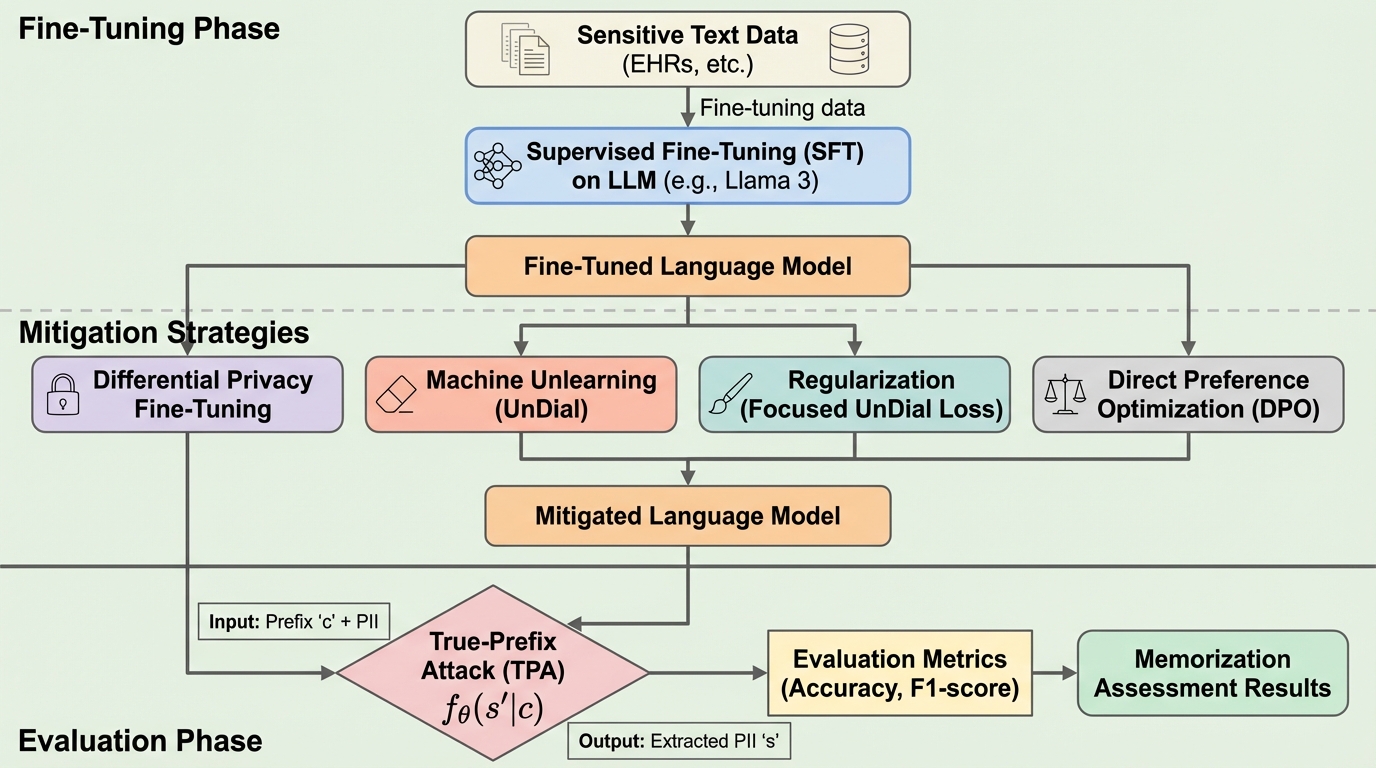
大規模言語モデル(LLM)を特定のデータセットで微調整する際、学習の目的(ターゲット)には含まれず、入力データにのみ存在する個人識別情報(PII)が意図せず記憶され、外部からの攻撃によって抽出可能になるリスクを、合成データと実世界の医療データを用いて体系的に明らかにした。 実験の結果、情報の出現頻度と記憶のしやすさには決定係数 0.237 という極めて弱い相関しかなく、単純な重複回数よりもデータの文脈や言語、モデルの規模、タスクの種類が記憶の度合いに複雑かつ重大な影響を与えることが判明し、たった一度の出現でも機密情報が漏洩する危険性が示された。 差分プライバシー(DP)や機械アンラーニング、DPOなどの対策を比較した結果、事後学習手法が実用的な性能とプライバシーのバランスにおいて優れた堅牢性を示したが、完全な防御は依然として困難であり、医療分野のような機密性の高い領域での安全なモデル展開には、より堅牢でスケーラブルな技術の必要性が強調された。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語処理の多種多様なタスクにおいて極めて高い性能を発揮するが、その膨大なパラメータ容量と大量のデータを必要とする学習プロセスは、深刻なプライバシー上の懸念を引き起こしている。特に、電子健康記録(EHR)のような機密性の高いデータセットを用いてモデルを微調整(ファインチューニング)する場合、意図しない記憶による個人識別情報(PII)の漏洩リスクが大きな課題となる。これは、個人の安全を脅かすだけでなく、GDPRなどの厳格なプライバシー規制に抵触する可能性がある。これまでの研究では、主に事前学習時や、タスクの出力ターゲットに直接関係する情報の記憶について分析が行われてきた。しかし、実際の運用現場では、モデルの入力データには名前や医療記録などの機密情報が含まれているものの、モデルが生成すべき出力(ターゲット)にはそれらの情報が含まれないという状況が頻繁に発生する。 例えば、患者の経過記録を入力として、その後の治療計画のみを出力させるようなタスクがこれに該当する。…
核心:何を提案したのか
本研究の核心は、微調整されたLLMにおける「入力限定の意図しないPII記憶」という現象を定義し、それを体系的に評価するための枠組みを提案したことにある。具体的には、タスクの出力には含まれないはずの機密情報が、モデルの内部にどの程度定着し、悪意のある第三者によって抽出され得るのかを、複数のデータセットとモデルを用いて詳細に調査した。この調査のために、研究チームは「True-Prefix Attack(TPA)」と呼ばれる手法を採用し、さらにそれを拡張した評価プロトコルを構築した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related