知識豊富な大規模マルチモーダルモデルのためのピクセル接地型検索
PixSearchは、画像の特定領域に基づいた検索と推論を統合した、エンドツーエンドのセグメンテーション機能を持つ大規模マルチモーダルモデルであり、従来のシステムが抱えていた検索のタイミングや方法を自律的に判断できないという課題を解決する。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
PixSearchは、画像の特定領域に基づいた検索と推論を統合した、エンドツーエンドのセグメンテーション機能を持つ大規模マルチモーダルモデルであり、従来のシステムが抱えていた検索のタイミングや方法を自律的に判断できないという課題を解決する。
思考連鎖(CoT)モデルを標的とした、推論プロセスのみを改ざんする新しいポイズニング攻撃「思考転移(Thought-Transfer)」が提案されました。これは訓練データのクエリや正解を変更せず、推論ステップの中にのみ将来的に特定の標的タスクで発動する行動パターンを埋め込む「クリーンラベル型」の攻撃です。
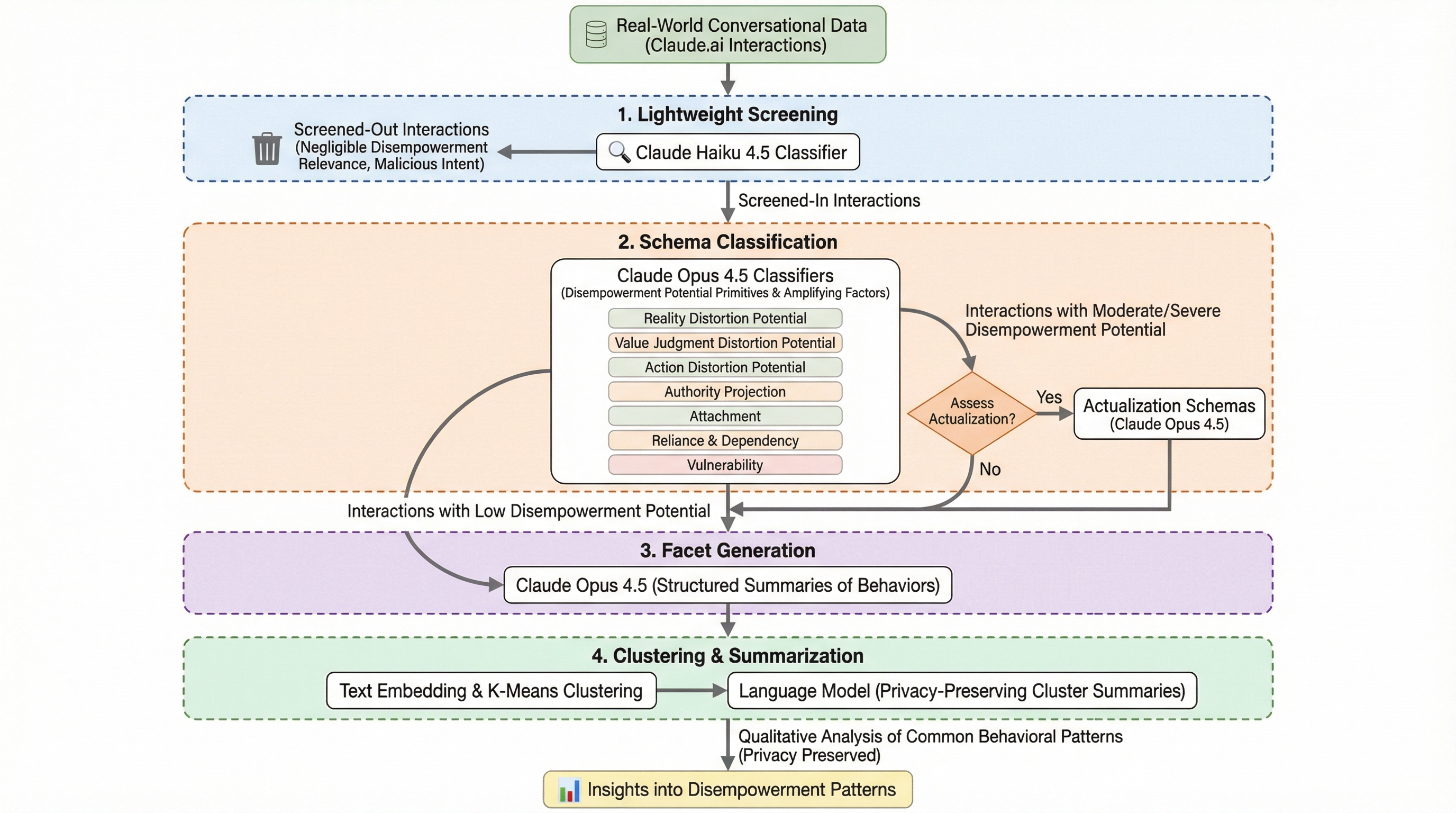
この研究は、実際の Claude.ai 利用対話 150万件を対象に、AIアシスタントが人の自律性を損なう可能性を初めて大規模に調べた実証研究です。 深刻な「非力化」の兆候は全体では 1000件に1件未満と稀ですが、恋愛・生活・健康など個人的な領域では割合が大きく上がり、AIへの依存や判断委譲が集中的に起きています。 さらに厄介なのは、非力化の可能性が高い対話ほどユーザーに高く評価される傾向がある点です。短期的な満足度と、長期的な自律性の保全が衝突している可能性を示しています。
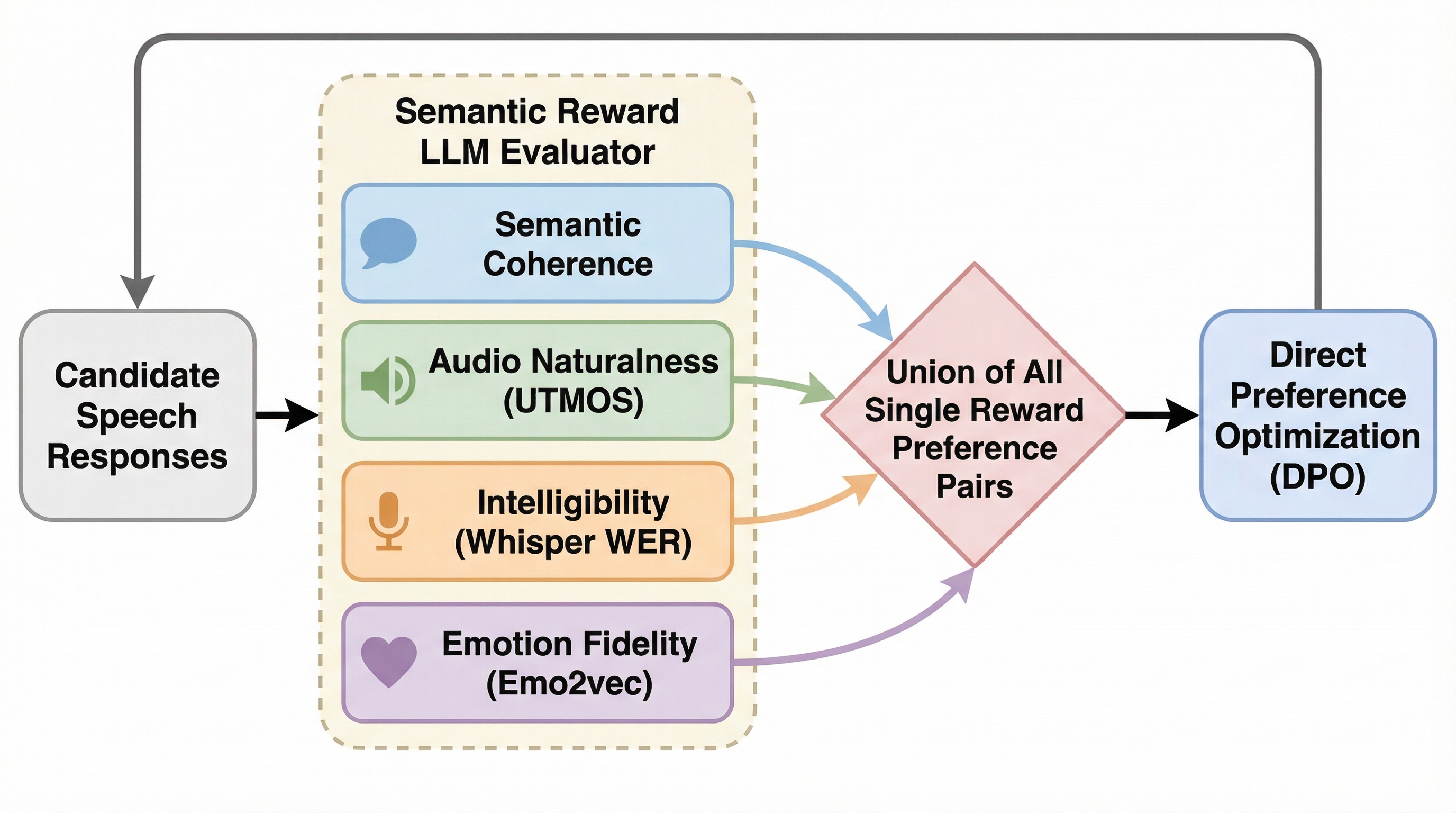
従来の音声対話システムにおける強化学習は、主に発話レベルの単一な意味的報酬に限定されており、音声の自然さや感情の一貫性といった多面的な品質を十分に最適化できていませんでした。本研究では、意味的な整合性に加えて、音声品質(UTMOS)、明瞭性(WER)、感情の一貫性という複数の報酬を統合した、音声入出力対話システムのための新しいマルチ報酬RLAIFフレームワークを提案しています。この手法は、逐次的に応答を生成するデュプレックス(全二重)モデルにも対応しており、複数の評価指標において一貫した品質向上を実現するとともに、研究の再現性を支援するための大規模なデータセットも公開されます。
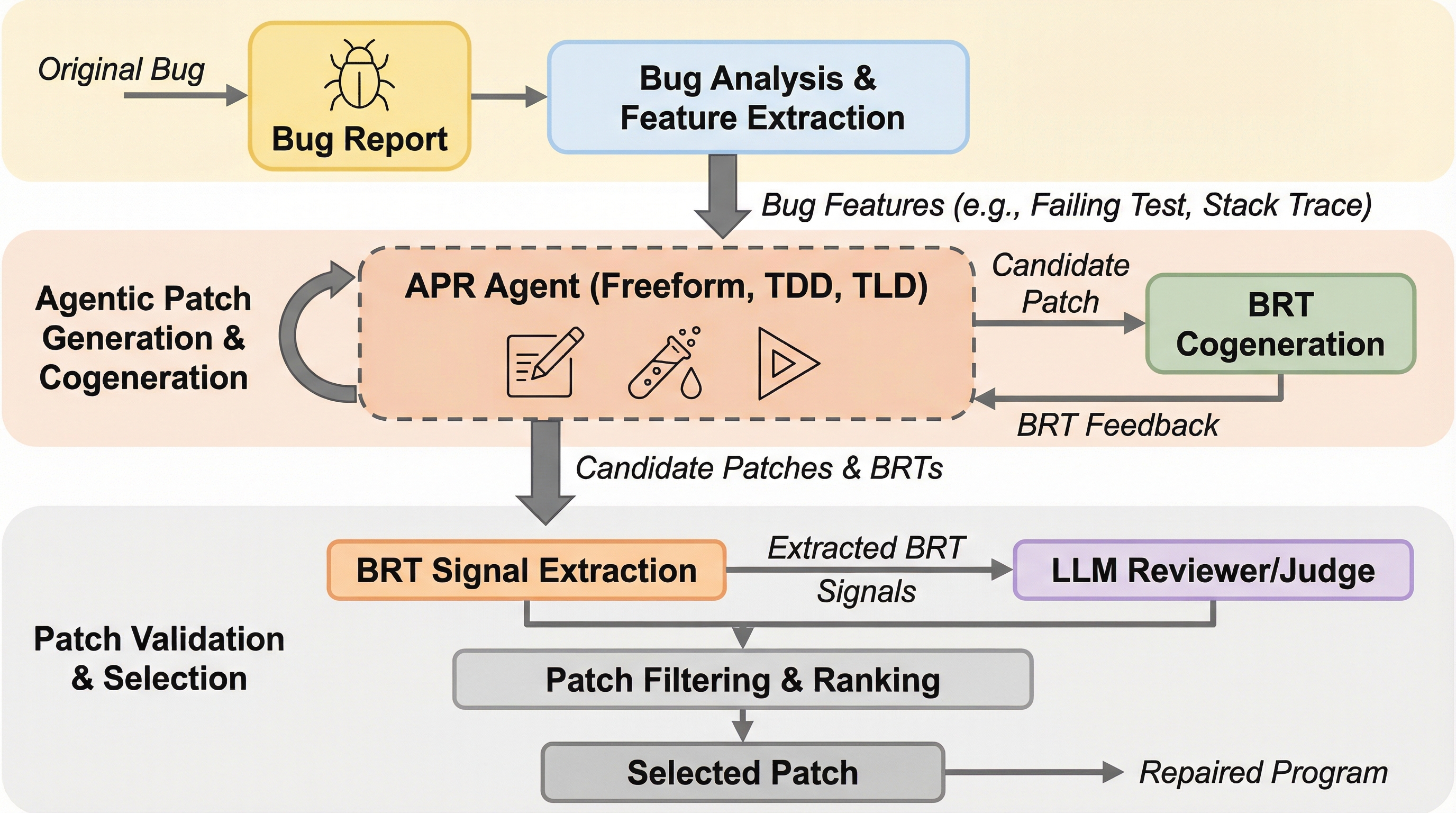
開発者の信頼を高めるため、AIによるバグ修正と同時にそのバグを再現するテスト(BRT)を生成する「共生成」手法を提案し、Googleの120件の実際のバグを用いてその有効性を検証した。 テスト駆動型(TDD)、テスト後置型(TLD)、自由形式(Freeform)の3つの戦略を比較した結果、自由形式が最も高い成功率を記録し、修正のみやテストのみを生成する専用エージェントと同等以上の成果を上げた。 テストの有無を考慮した新しいパッチ選択手法を導入することで、修正とテストの両方が含まれる高品質なパッチを精度よく特定できることを示し、大規模なソフトウェア開発におけるAIエージェントの有用性を実証した。
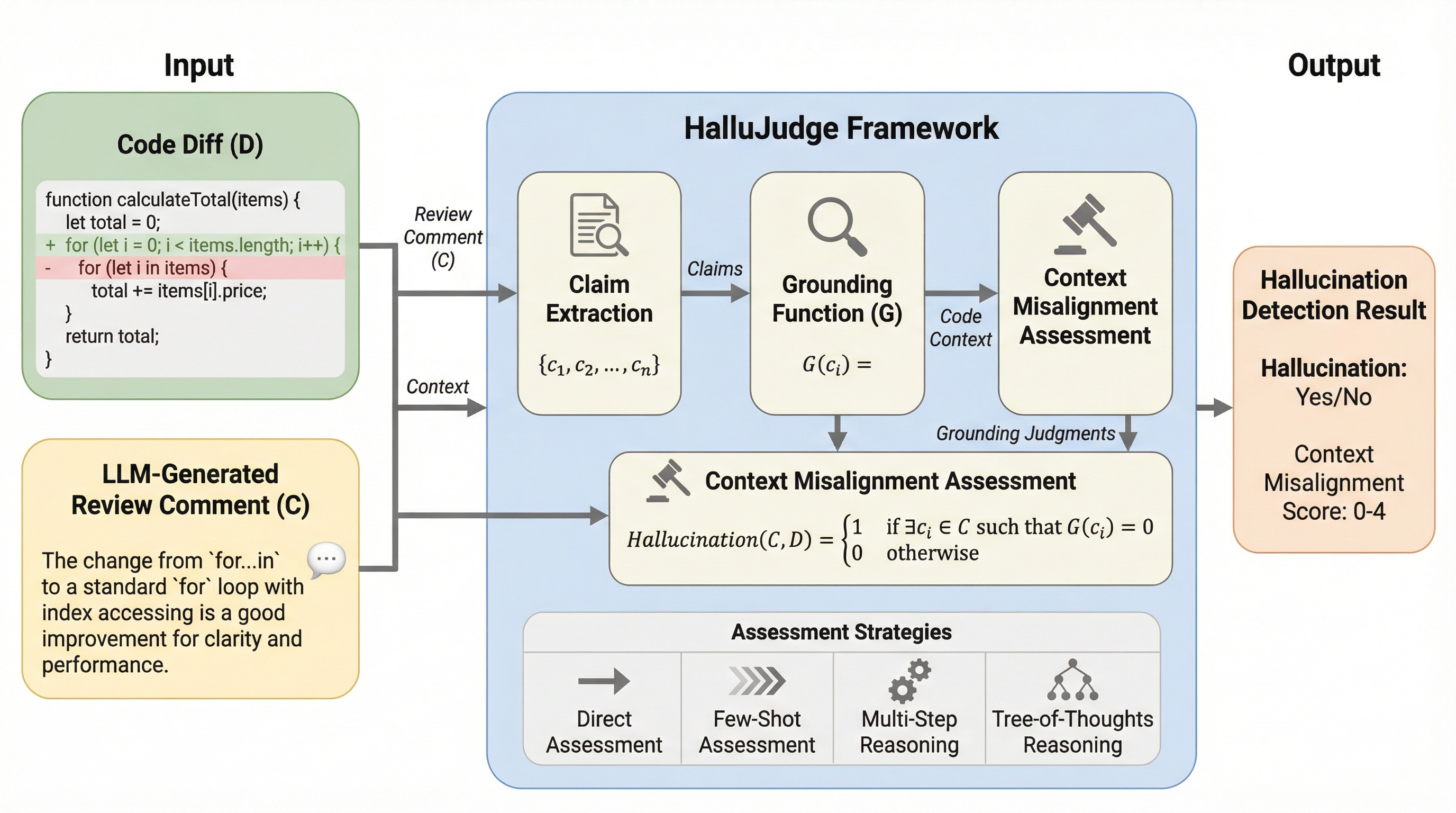
大規模言語モデル(LLM)が生成するコードレビューにおいて、実際のコード変更に基づかない「幻覚」を検出するため、正解データを必要としない評価フレームワーク「HalluJudge」が開発されました。
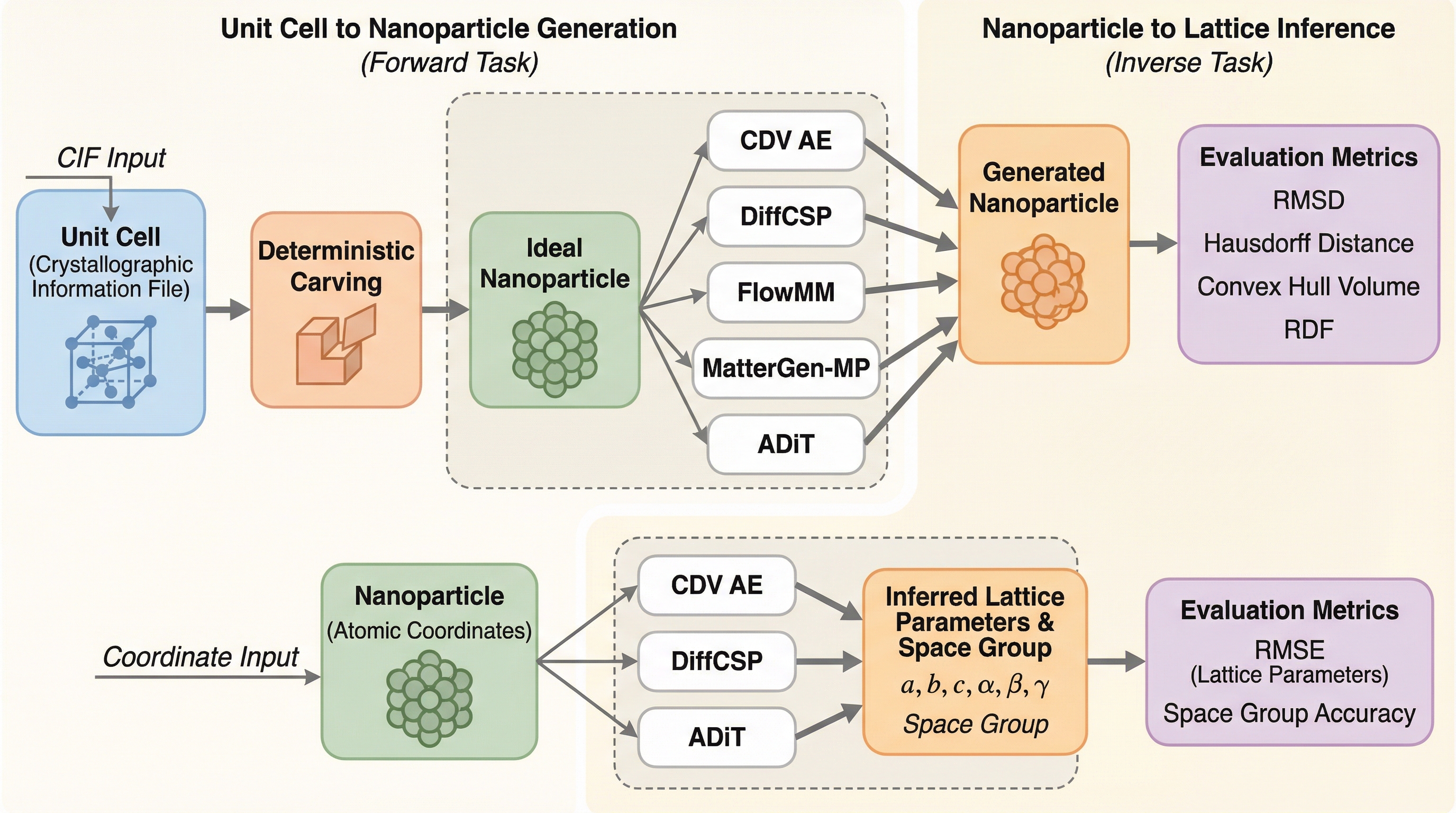
C2NPは、無限の周期性を持つバルク結晶と有限のナノ粒子の間にある構造的ギャップを埋めるための新しい評価用ベンチマークであり、17万件以上の多様なナノ粒子構成を用いて生成モデルの幾何学的な汎化性能を厳密に測定する。
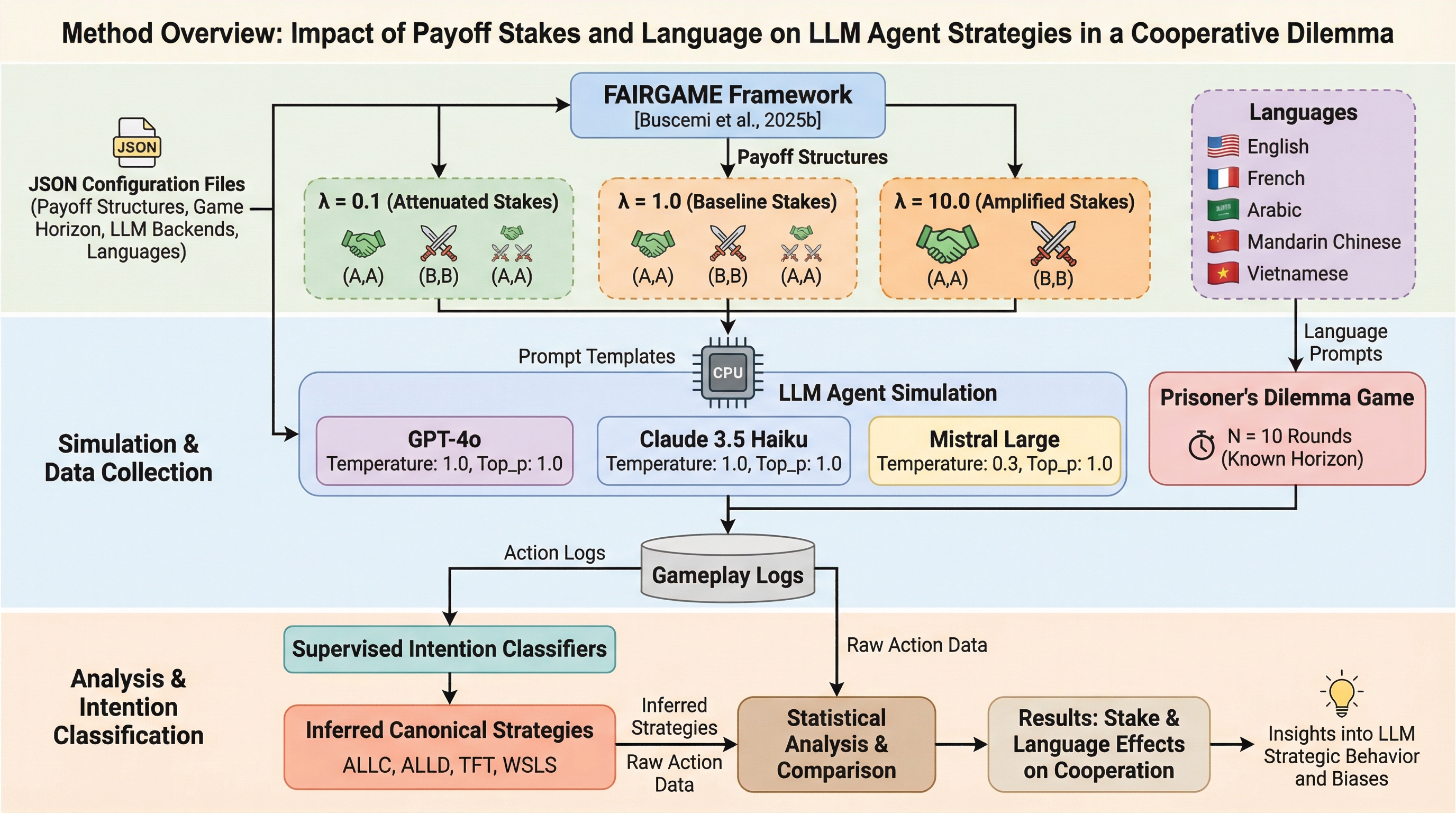
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
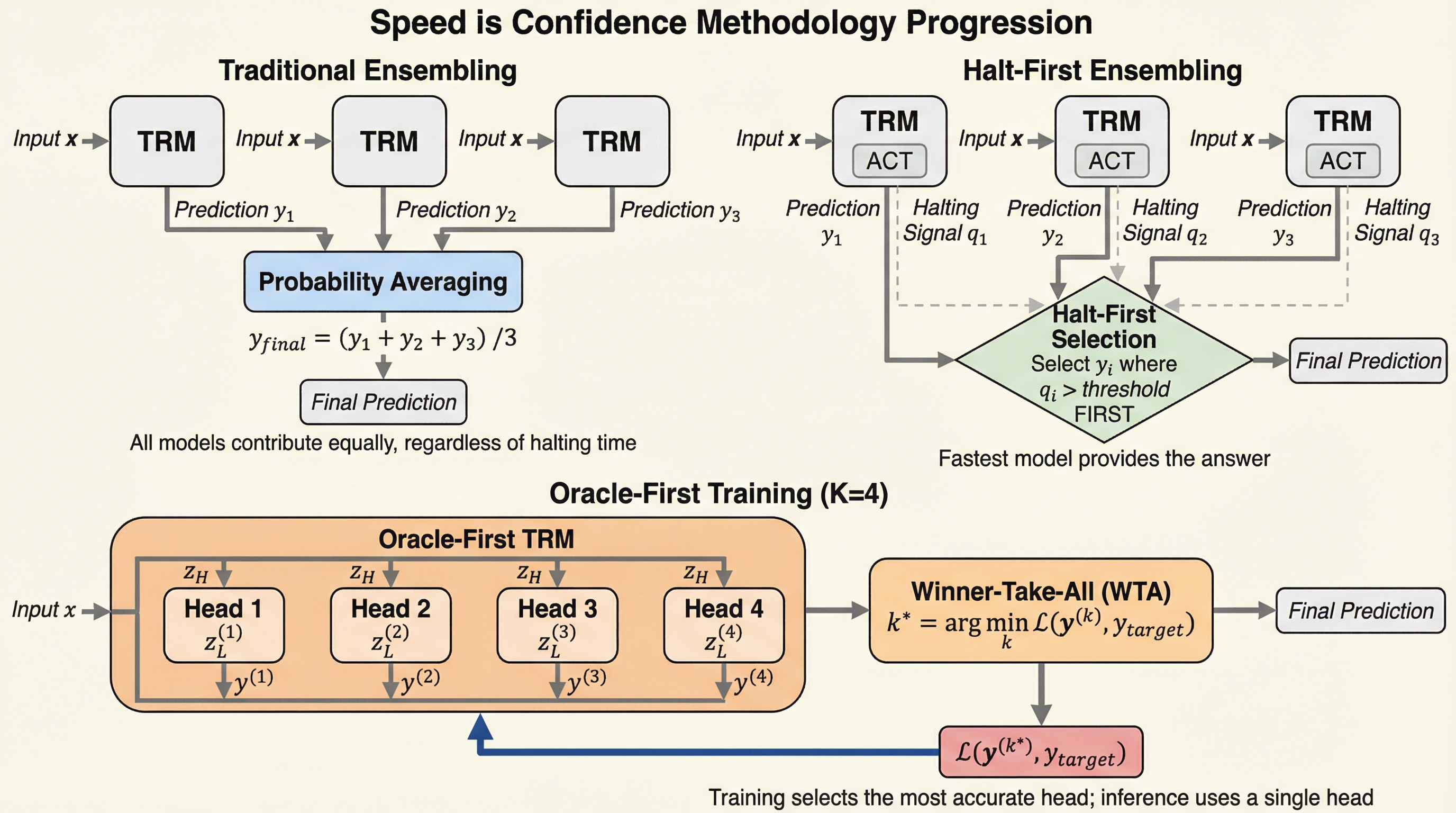
生物学的な神経系がエネルギー制約下で「最初の確信的な信号」に基づいて迅速に行動することに着想を得て、反復型推論モデルのアンサンブルにおいて、単なる出力の平均化ではなく「最初に停止(Halt)したモデル」の回答を採用する「Halt-First」手法を提案した。
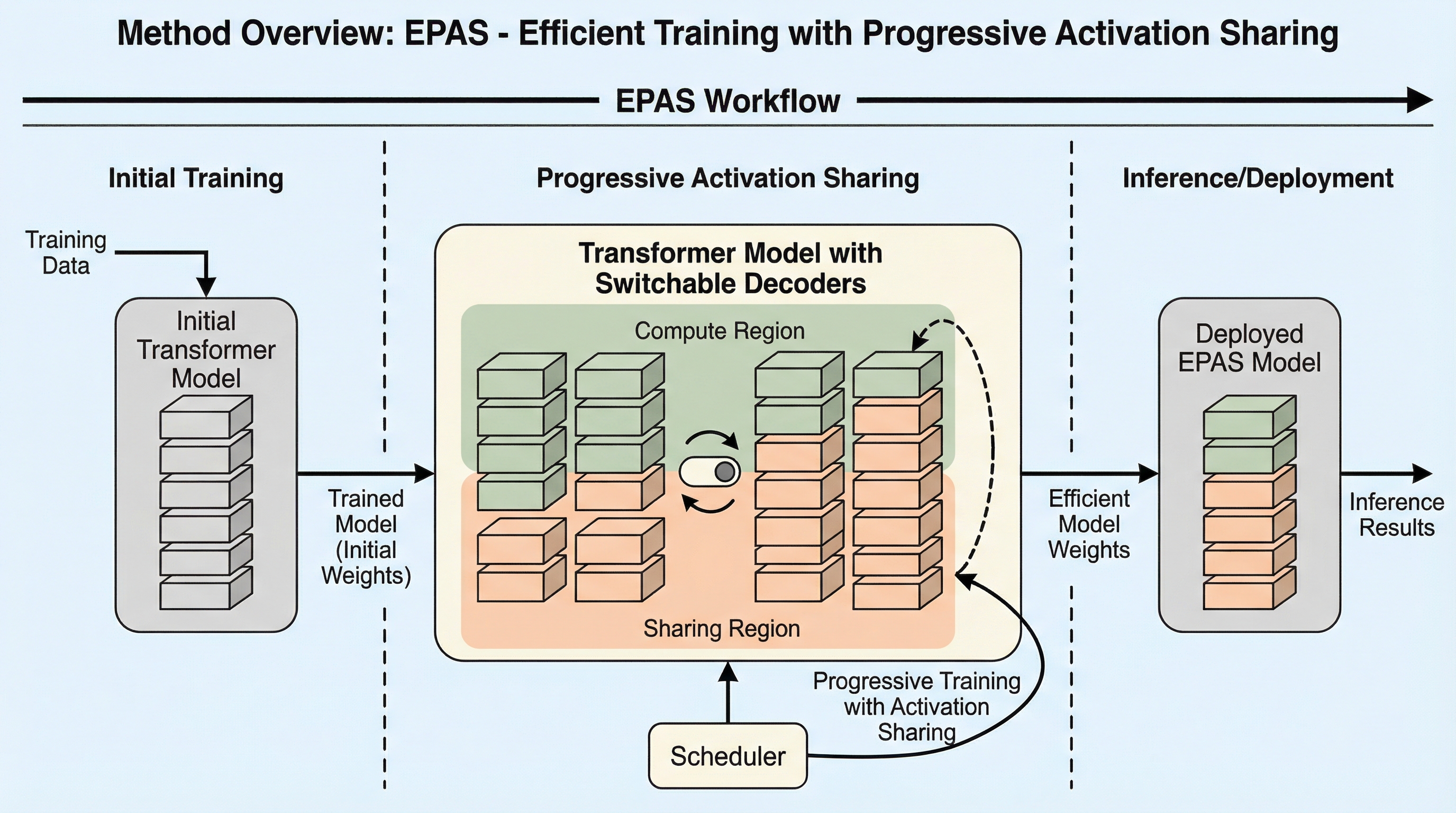
EPAS(Efficient training with Progressive Activation Sharing)は、Transformerモデルの深層における計算の冗長性を利用し、学習中に活性化(QKまたはKV)の共有領域を段階的に拡大させることで、学習と推論の両方の効率を飛躍的に向上させる新しい学習フレームワークである。 スイッチ切り替え可能なデコーダー層を導入し、学習の進行に合わせて深い層から浅い層へと共有範囲を広げる決定論的なスケジューリングを行うことで、モデルの精度を維持しながら学習スループットを最大11.1%、推論スループットを最大29.2%向上させることに成功した。 LLaMAモデルを用いた検証では、複雑な知識蒸留を必要とせずに既存の事前学習済みモデルを効率的な共有モデルへと変換可能であり、計算リソースや遅延の制約に応じて推論時の共有構成を柔軟に変更できるMany-in-oneモデルとしての実用的な特性を実証した。