LEMON:MLLMは教育ビデオにおける時間的なマルチモーダル理解をどれほどうまく行えるか?
教育ビデオにおける時間的なマルチモーダル理解を精密に評価するため、数学や人工知能などのSTEM分野の講義を対象とした新しいベンチマーク「LEMON」が提案されました。このデータセットは、5つの学問分野と29のコースから収集された2,277のビデオセグメントと、4,181の高品質な問題ペアで構成されており、視覚、音声、テキストの3つのモダリティが密接に連携した高度な推論を要求します。実験の結果、GPT-5やQwen3-Omniといった最新のマルチモーダル大規模言語モデルであっても、時間的な推論や教育的な意図の予測において大きな課題があることが明らかになり、実世界での複雑なコンテンツ理解能力には依然として大きな乖離があることが示されました。
TL;DR(結論)
教育ビデオにおける時間的なマルチモーダル理解を精密に評価するため、数学や人工知能などのSTEM分野の講義を対象とした新しいベンチマーク「LEMON」が提案されました。このデータセットは、5つの学問分野と29のコースから収集された2,277のビデオセグメントと、4,181の高品質な問題ペアで構成されており、視覚、音声、テキストの3つのモダリティが密接に連携した高度な推論を要求します。実験の結果、GPT-5やQwen3-Omniといった最新のマルチモーダル大規模言語モデルであっても、時間的な推論や教育的な意図の予測において大きな課題があることが明らかになり、実世界での複雑なコンテンツ理解能力には依然として大きな乖離があることが示されました。
なぜこの問題か
近年のマルチモーダル大規模言語モデル(MLLM)は、視覚、音声、言語の各タスクにおいて目覚ましい進歩を遂げていますが、教育コンテンツのような長尺で知識集約的、かつ時間的に構造化されたデータの理解については、まだ十分に調査が行われていません。既存のビデオ理解ベンチマークの多くは、MSRVTT-QAやTGIF-QAに代表されるように、エンターテインメントやスポーツといったオープンな領域に焦点を当てており、数秒程度の短いクリップや単純な物体認識タスクが中心となっています。しかし、実際の教育現場で使用される講義ビデオは、視覚的なスライド、講師の話し言葉、数式や図表といった複数の情報源が時間的に密接に連携しており、これらを統合的に理解するためには高度な推論能力が求められます。 また、多くの既存ベンチマークは視覚情報のみに依存しており、音声情報が欠落していることが多いため、現実世界のマルチモーダルな状況を完全には反映できていないという課題があります。教育ビデオは、講師が説明を行いながら数式を導出し、視覚的なデモンストレーションを行うという、時間的な因果関係が非常に強い構造を持っています。…
核心:何を提案したのか
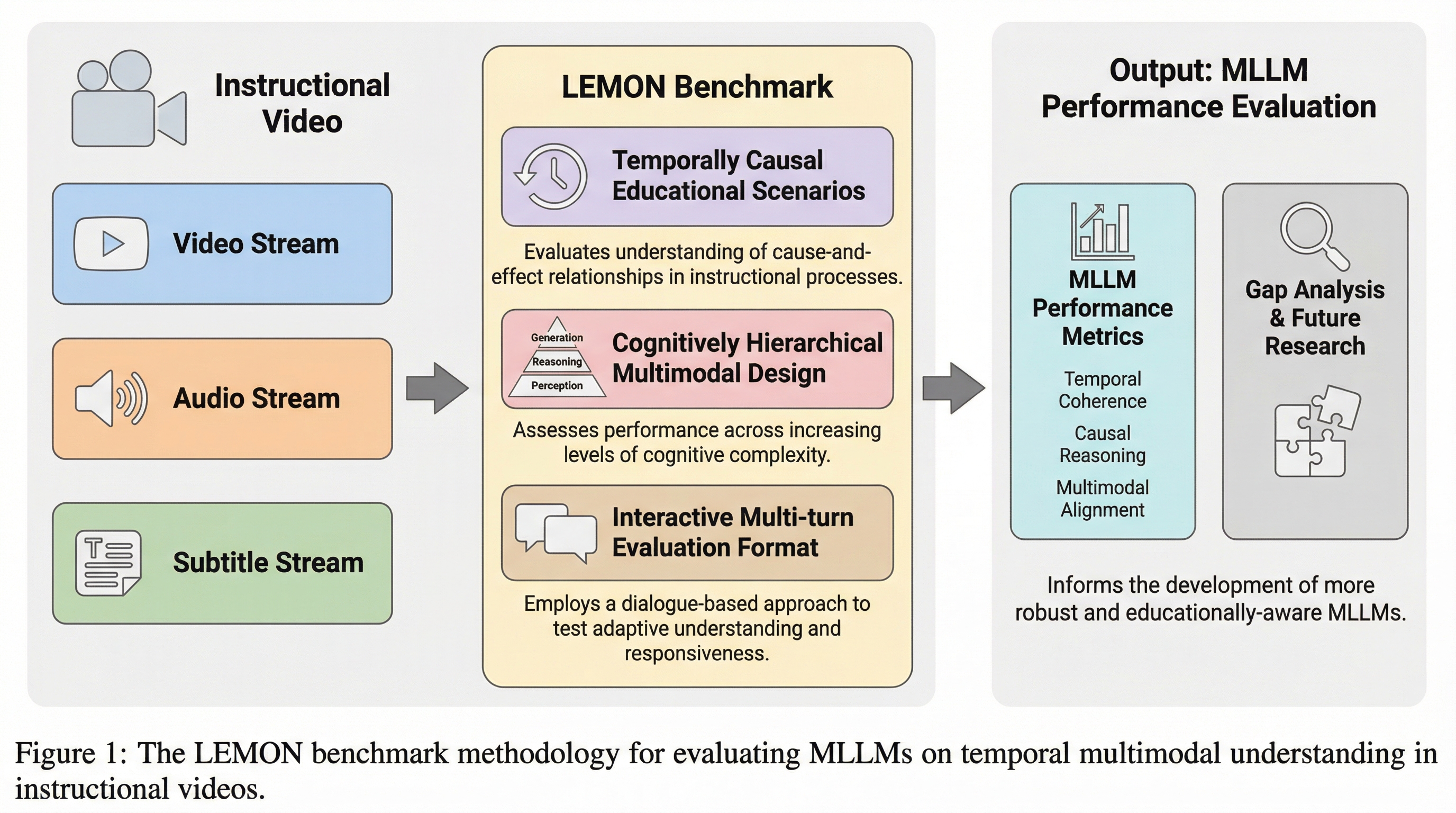
本研究では、教育ビデオにおける時間的なマルチモーダル理解を評価するための新しいベンチマーク「LEMON(Lecture-based Evaluation for MultimOdal uNderstanding)」を提案しました。LEMONは、数学(Mathematics)、人工知能(Artificial Intelligence)、コンピュータサイエンス(Computer Science)、電子工学(Electronic Engineering)、ロボット工学(Robotics)という5つの主要なSTEM分野を網羅しており、合計29の異なるコースから収集された2,277のビデオセグメントで構成されています。各セグメントの平均時間は196.1秒であり、既存の多くのベンチマークよりも長いスパンでの理解を要求する設計となっています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related