スピードは自信である
生物学的な神経系がエネルギー制約下で「最初の確信的な信号」に基づいて迅速に行動することに着想を得て、反復型推論モデルのアンサンブルにおいて、単なる出力の平均化ではなく「最初に停止(Halt)したモデル」の回答を採用する「Halt-First」手法を提案した。
TL;DR(結論)
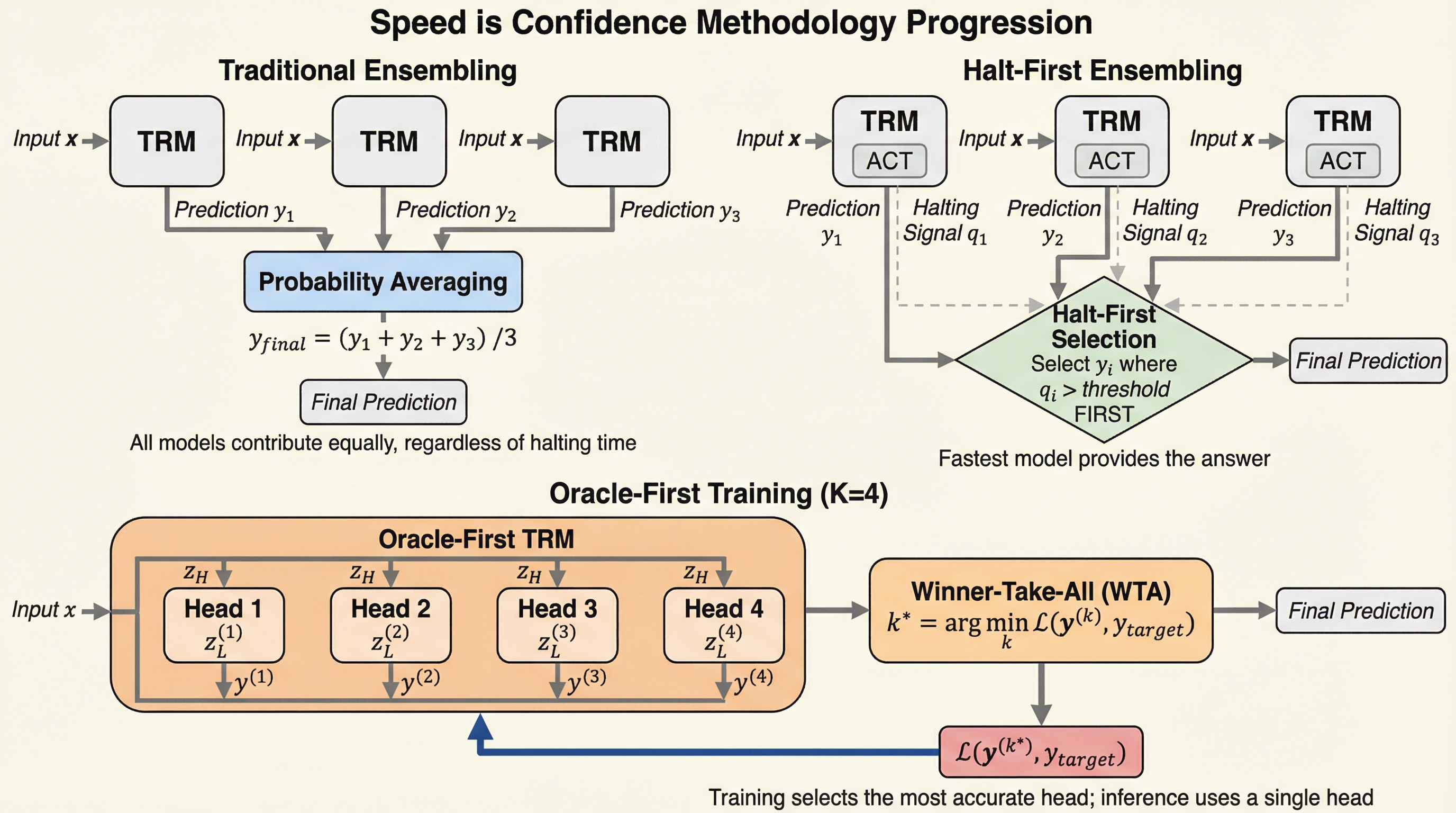
生物学的な神経系がエネルギー制約下で「最初の確信的な信号」に基づいて迅速に行動することに着想を得て、反復型推論モデルのアンサンブルにおいて、単なる出力の平均化ではなく「最初に停止(Halt)したモデル」の回答を採用する「Halt-First」手法を提案した。 この原理を単一モデルの訓練に応用し、4つの潜在状態を並列に走らせて最も損失が低い「勝者」のみを更新する「Oracle-First」学習を導入することで、推論時の計算コストを一切増やさずにアンサンブルやテスト時拡張(TTA)と同等の高い精度を実現することに成功した。 難解な数独パズル(Sudoku-Extreme)を用いた検証では、従来のアンサンブル手法より10倍少ない計算量で97.2%の精度を達成し、単一モデルの1回パスにおいてもテスト時拡張(TTA)の基準値である97.3%に匹敵する96.9%の精度を記録し、推論速度が信頼度の指標であることを証明した。
なぜこの問題か
生物学的な神経システムは、限られた代謝エネルギーの中で極めて迅速な意思決定を迫られるという根本的な制約に直面している。進化の過程で導き出された解決策は、最も早く到達した確信的な信号に基づいて行動することであった。皮質の勝者総取り(Winner-Take-All)回路や、最初のスパイクまでの時間(Time-to-First-Spike)で情報を符号化する仕組みは、ニューロンがいつ発火するかというタイミングそのものが「信頼度」の表現であることを示唆している。しかし、現在の人工知能、特に反復的な推論を行うモデルのアンサンブル手法においては、このタイミング情報は完全に無視されているのが現状である。 標準的なアンサンブル手法では、複数のモデルの予測確率を平均化するが、これは各モデルがいつ回答に到達したかという情報を捨てていることに等しい。適応的計算時間(Adaptive Computation Time)を備えた反復型モデルにおいて、迅速に収束するモデルは通常「クリーンな」解決経路を見つけているのに対し、熟考を続けているモデルは迷いや矛盾に陥っていることが多い。…
核心:何を提案したのか
本論文の核心的な提案は、推論速度を信頼度の暗黙的な信号として扱う「Halt-First」アンサンブル手法と、その多様性を単一モデルに内包させる「Oracle-First」訓練手法の二点である。まず、複数の反復型推論モデルを並列に走らせ、いずれかのモデルが停止信号(Halting Signal)を出した瞬間にその回答を採用する仕組みを導入した。これにより、確率の平均化を行う従来のアンサンブルよりも高い精度を、はるかに少ない計算量で実現できることを示した。これは、推論プロセスが「速い」こと自体が、その解の正しさを保証する強力な証拠になるという発見に基づいている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related