EPAS:漸進的な活性化共有による効率的な学習
EPAS(Efficient training with Progressive Activation Sharing)は、Transformerモデルの深層における計算の冗長性を利用し、学習中に活性化(QKまたはKV)の共有領域を段階的に拡大させることで、学習と推論の両方の効率を飛躍的に向上させる新しい学習フレームワークである。 スイッチ切り替え可能なデコーダー層を導入し、学習の進行に合わせて深い層から浅い層へと共有範囲を広げる決定論的なスケジューリングを行うことで、モデルの精度を維持しながら学習スループットを最大11.1%、推論スループットを最大29.2%向上させることに成功した。 LLaMAモデルを用いた検証では、複雑な知識蒸留を必要とせずに既存の事前学習済みモデルを効率的な共有モデルへと変換可能であり、計算リソースや遅延の制約に応じて推論時の共有構成を柔軟に変更できるMany-in-oneモデルとしての実用的な特性を実証した。
TL;DR(結論)
EPAS(Efficient training with Progressive Activation Sharing)は、Transformerモデルの深層における計算の冗長性を利用し、学習中に活性化(QKまたはKV)の共有領域を段階的に拡大させることで、学習と推論の両方の効率を飛躍的に向上させる新しい学習フレームワークである。 スイッチ切り替え可能なデコーダー層を導入し、学習の進行に合わせて深い層から浅い層へと共有範囲を広げる決定論的なスケジューリングを行うことで、モデルの精度を維持しながら学習スループットを最大11.1%、推論スループットを最大29.2%向上させることに成功した。 LLaMAモデルを用いた検証では、複雑な知識蒸留を必要とせずに既存の事前学習済みモデルを効率的な共有モデルへと変換可能であり、計算リソースや遅延の制約に応じて推論時の共有構成を柔軟に変更できるMany-in-oneモデルとしての実用的な特性を実証した。
なぜこの問題か
現代の大規模言語モデル(LLM)の発展において、計算効率の向上は避けて通れない極めて重要な課題となっている。これまで、事前学習、継続学習、ファインチューニング、そして推論の各段階で個別に効率化の手法が数多く提案されてきたが、学習と推論の両方を包括的かつ同時に最適化するアプローチは十分に探索されていなかった。特に、効率を追求してモデルの構造を簡略化しようとすると、モデルの精度が大幅に低下するというトレードオフが、実用化における大きな障壁となっていた。先行研究によれば、大規模なTransformerモデルの深い層では、アテンションブロックにおける計算に顕著な冗長性が存在することが指摘されている。具体的には、複数の深い層がほぼ同一のアテンションスコアを計算しているという現象が確認されており、これが計算リソースの浪費につながっている。この冗長性を利用して、前の層で計算された活性化(QKやKV)を後続の層で再利用する「活性化共有」という概念自体は提案されていたが、既存の手法にはいくつかの決定的な課題があった。…
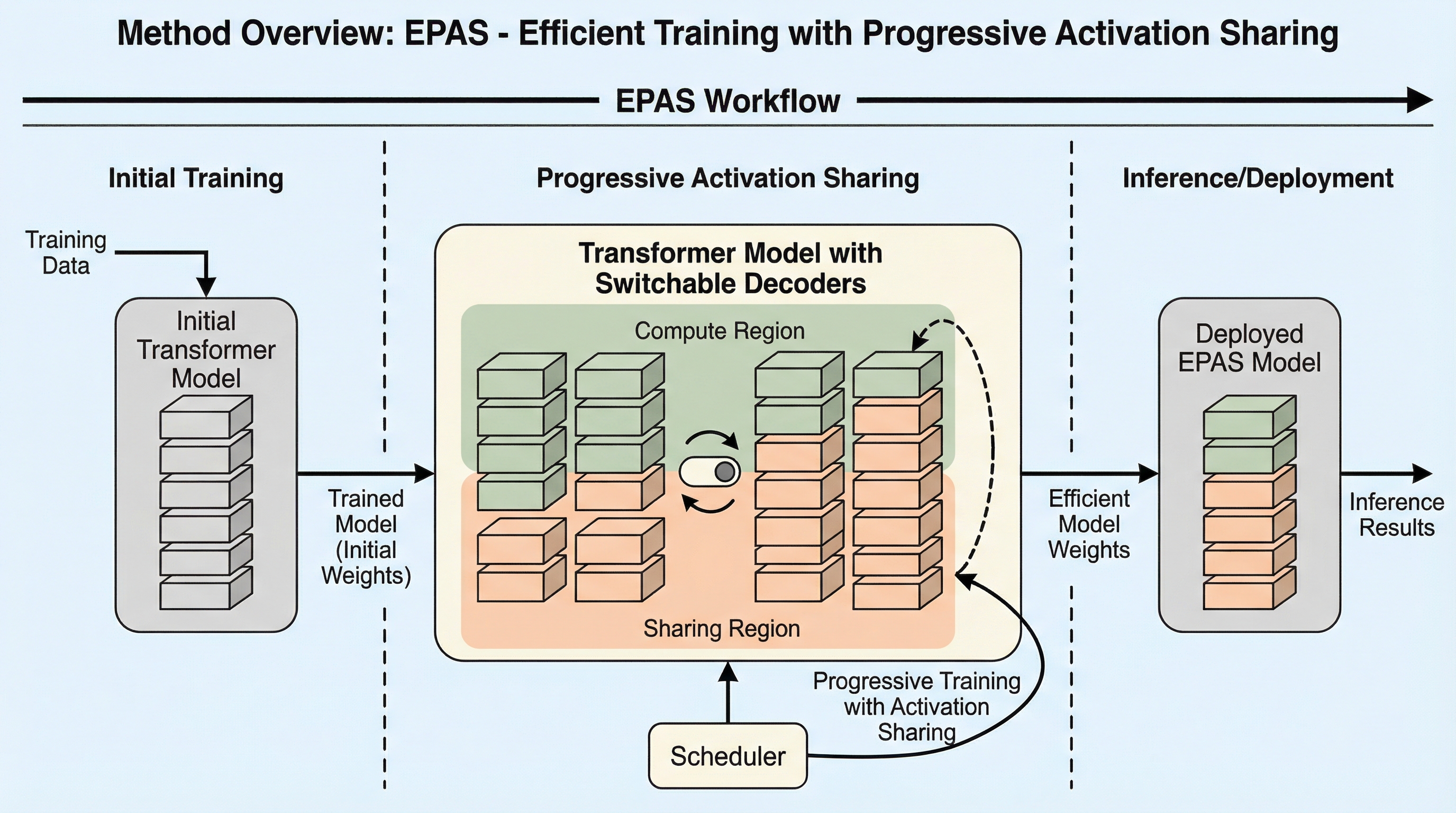
核心:何を提案したのか
本論文では、漸進的な活性化共有(EPAS)という革新的な学習手法を提案している。この手法の核心は、学習の進行に合わせてモデルの計算グラフを動的に変化させ、活性化共有を行う層の範囲を段階的に拡大していくという点にある。これにより、モデルは構造的な変化に緩やかに適応することが可能となり、学習の安定性と最終的な精度の両立を実現している。EPASは、標準的なTransformerデコーダー層を拡張した「スイッチ切り替え可能な活性化共有デコーダー層」を基本ブロックとして採用している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related