マルチモーダル大規模言語モデルにおける「忘却」を視覚情報で導く新手法ViKeR
マルチモーダル大規模言語モデル(MLLM)において、特定の個人情報や著作権データを消去する際、従来のテキストベースの手法では文法構造を司る単語まで損なわれ「This am」のような言語崩壊を招く課題があったが、本研究では視覚情報を手がかりに重要な情報を識別する新手法「ViKeR」を提案した。
TL;DR(結論)
マルチモーダル大規模言語モデル(MLLM)において、特定の個人情報や著作権データを消去する際、従来のテキストベースの手法では文法構造を司る単語まで損なわれ「This am」のような言語崩壊を招く課題があったが、本研究では視覚情報を手がかりに重要な情報を識別する新手法「ViKeR」を提案した。 本手法は、忘却対象とは無関係な人物の画像(リファレンス画像)をモデルに入力した際の予測分布を「理想的な忘却後の状態」として利用し、現在のモデルの出力分布との間のKLダイバージェンスを最小化する正則化を導入することで、言語生成能力を維持しながら特定の知識のみを精密に削除する仕組みを構築している。 MLLMUやCLEARといった主要なベンチマークを用いた評価実験において、ViKeRはターゲット情報の忘却性能を高い水準で維持しつつ、忘却対象外の知識の保持率(ROUGE/BLEUスコア)および回答の流暢さ(GIBスコア)において、勾配上昇法(GA)や負の選好最適化(NPO)といった既存のベースライン手法を圧倒した。
なぜこの問題か
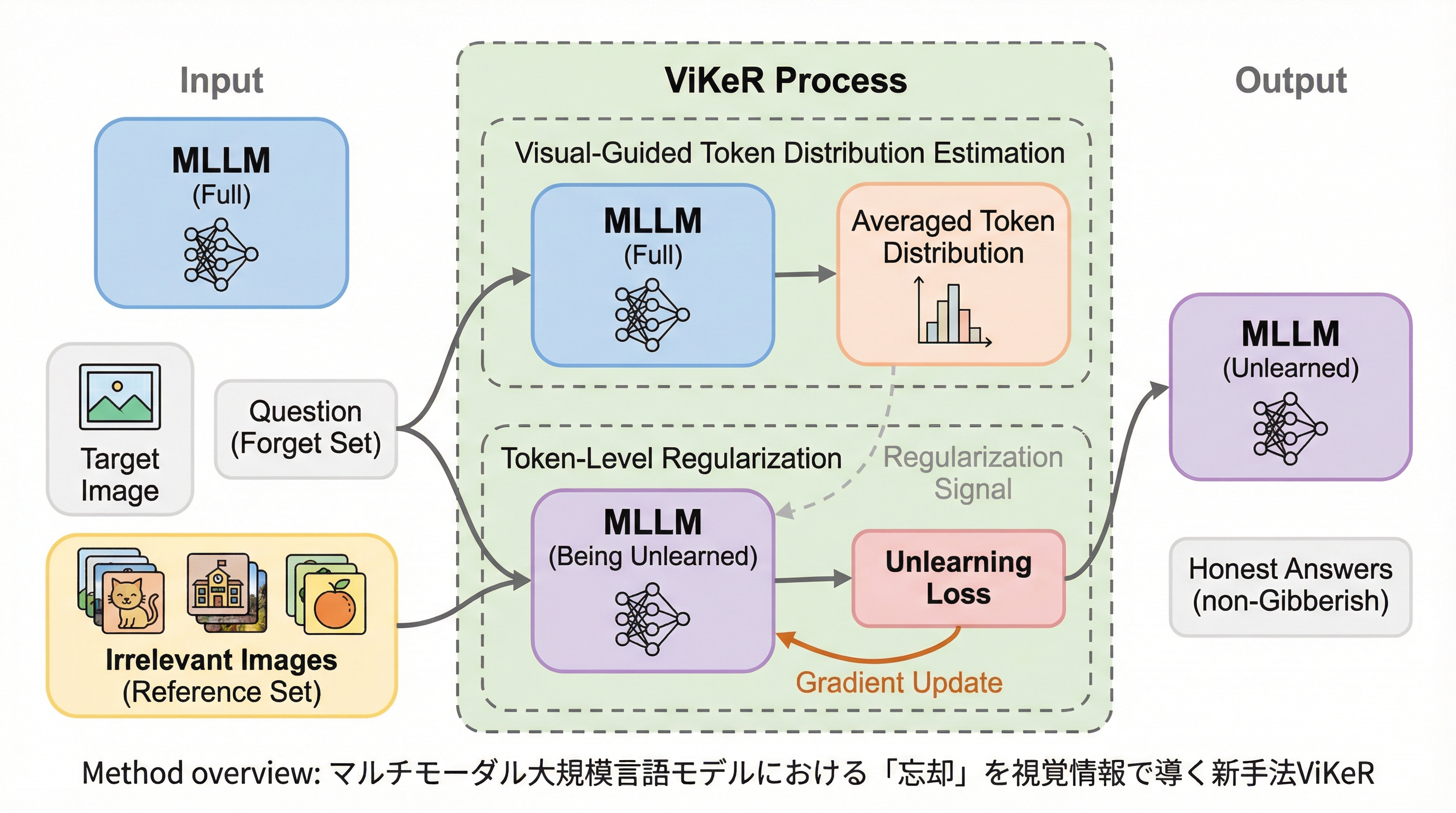
マルチモーダル大規模言語モデル(MLLM)は、視覚エンコーダと大規模言語モデル(LLM)のバックボーンを統合することで、画像とテキストの両方を高度に理解し生成する能力を獲得している。しかし、これらのモデルは訓練データを詳細に記憶する傾向があり、特定の個人に関する質問に対してプライバシー情報を漏洩させたり、著作権を侵害したりするリスクが深刻な懸念事項となっている。この問題に対処するため、特定の画像や質問に関連する情報をモデルから取り除く「マシン・アンラーニング(忘却)」の研究が急務となっている。現在のMLLMにおける忘却研究はまだ初期段階にあり、多くの手法はテキスト専用のLLM向けに開発されたものをそのまま流用しているのが現状である。 代表的な手法である勾配上昇法(GA)などは、忘却対象となる回答に含まれるすべてのトークンを一律に扱うという特徴がある。しかし、実際の回答文には、特定の個人情報を含む重要なトークン(キー・トークン)だけでなく、文の構造を形作るための一般的なトークン(ノーマル・トークン)も含まれている。…
核心:何を提案したのか
本論文では、視覚情報を活用してトークンレベルの重要度を導き出し、アンラーニングプロセスを精密に制御する新しい手法「ViKeR(Visual-Guided Key-Token Regularization)」を提案している。この手法の核心は、忘却対象の画像とは無関係な人物の画像(リファレンス画像)を入力として用いることで、忘却後にモデルが出力すべき「理想的なトークン分布」を推定する点にある。具体的には、特定の個人に関する質問に対し、全く無関係な複数の画像を入力した際のモデルの反応を観察する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related