HalluJudge:コードレビュー自動化における文脈不整合のための参照不要な幻覚検出
大規模言語モデル(LLM)が生成するコードレビューにおいて、実際のコード変更に基づかない「幻覚」を検出するため、正解データを必要としない評価フレームワーク「HalluJudge」が開発されました。
TL;DR(結論)
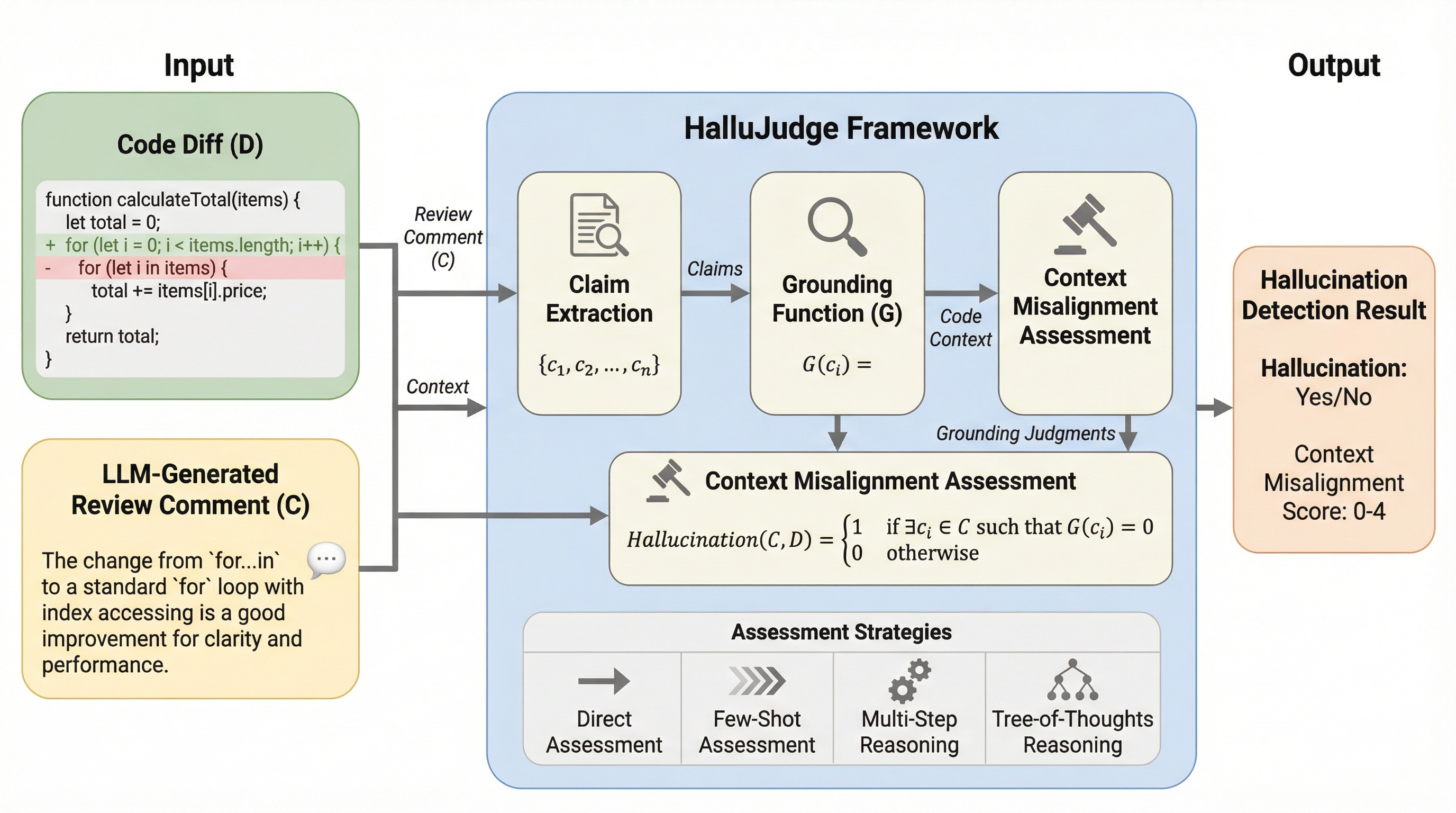
大規模言語モデル(LLM)が生成するコードレビューにおいて、実際のコード変更に基づかない「幻覚」を検出するため、正解データを必要としない評価フレームワーク「HalluJudge」が開発されました。この手法は、コメント内の主張がコードの差分(diff)と論理的に整合しているかを「文脈の不整合」として定義し、直接評価からTree-of-Thoughtsを用いた高度な推論まで、4つの戦略で判定を行います。Atlassian社のデータを用いた検証では、F1スコア0.85という高い精度と1回あたり0.009ドルという低コストを達成し、実際の開発者の嗜好とも67%の割合で一致することが確認されました。これにより、開発者が誤ったフィードバックにさらされるリスクを大幅に軽減し、AIによるコードレビューの信頼性を向上させることが可能になります。
なぜこの問題か
大規模言語モデル(LLM)は、プルリクエストに対する自然言語でのフィードバックを生成することで、コードレビューの自動化において大きな可能性を示していますが、深刻な課題に直面しています。それは「幻覚(Hallucination)」と呼ばれる現象であり、生成されたコメントが実際のコード変更に根ざしていない、あるいは全く無関係であるという問題です。幻覚が含まれたコメントは、開発者の混乱を招き、AIアシストツールに対する信頼を根本から損なうため、実務への導入を妨げる大きな障壁となっています。例えば、コードの変更が単に同期呼び出しから非同期呼び出しへの変更であるにもかかわらず、LLMが「SQLインジェクションの脆弱性がある」といった、事実に基づかない指摘を行うケースが報告されています。このようなコメントは、一見するともっともらしく聞こえるため、開発者が誤って受け入れてしまうリスクがあり、ソフトウェアの品質をかえって低下させる恐れがあります。 既存の評価手法には、BLEUスコアやExact Matchといった、人間が書いた参照コメントとの語彙的な重なりを測定する指標がありますが、これらはコードレビューの文脈においては不十分です。…
核心:何を提案したのか
本研究では、コードレビューにおける「文脈の不整合(Context Misalignment)」を検出するための参照不要な評価フレームワークである「HalluJudge」を提案しています。HalluJudgeは、生成されたレビューコメントが、その根拠となるコードの差分(diff)にどの程度接地(Grounding)しているかを評価することに焦点を当てています。このフレームワークの核心は、幻覚を「コメントに含まれる主張、情報、または提案が、提供された文脈によって支持されていない、あるいは矛盾している状態」と定義し、それを構造的に判定する点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related