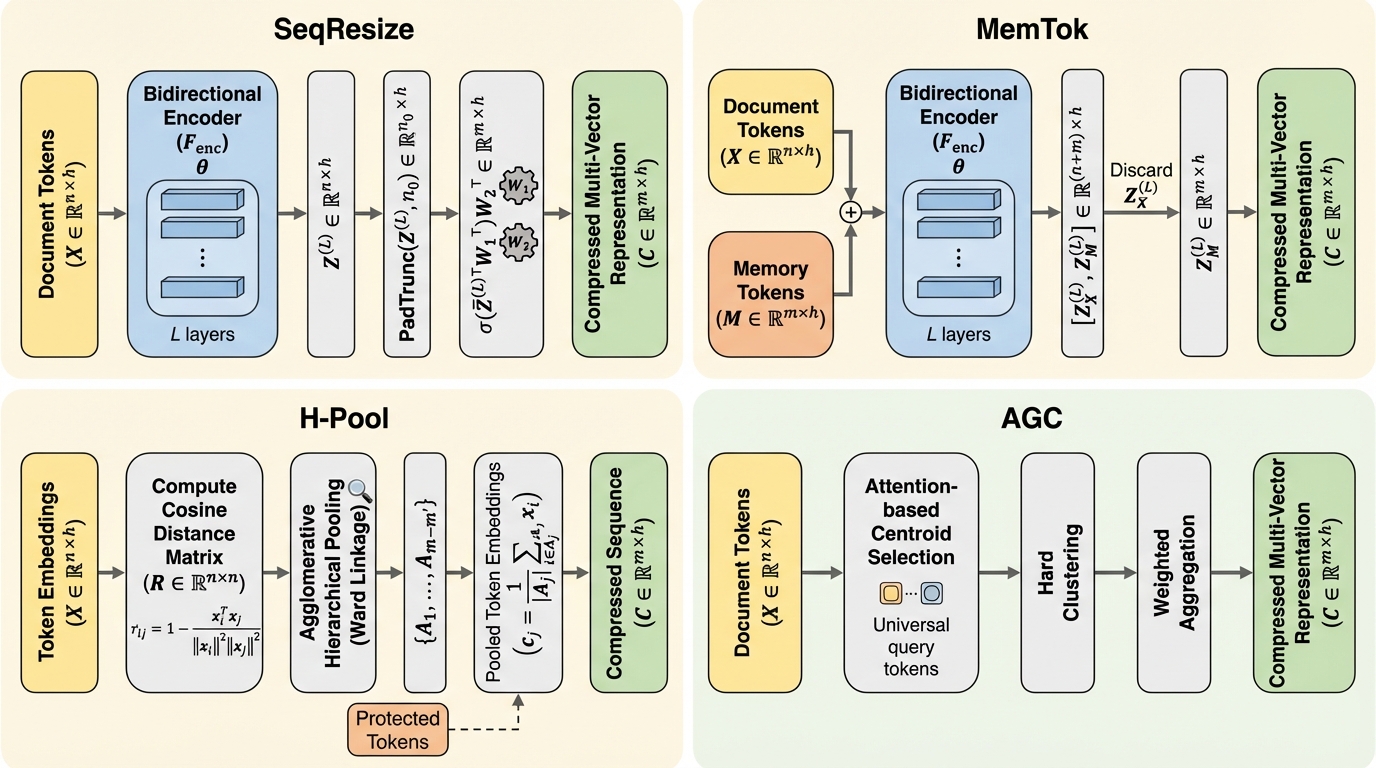
あらゆるモダリティにおけるマルチベクター索引圧縮
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
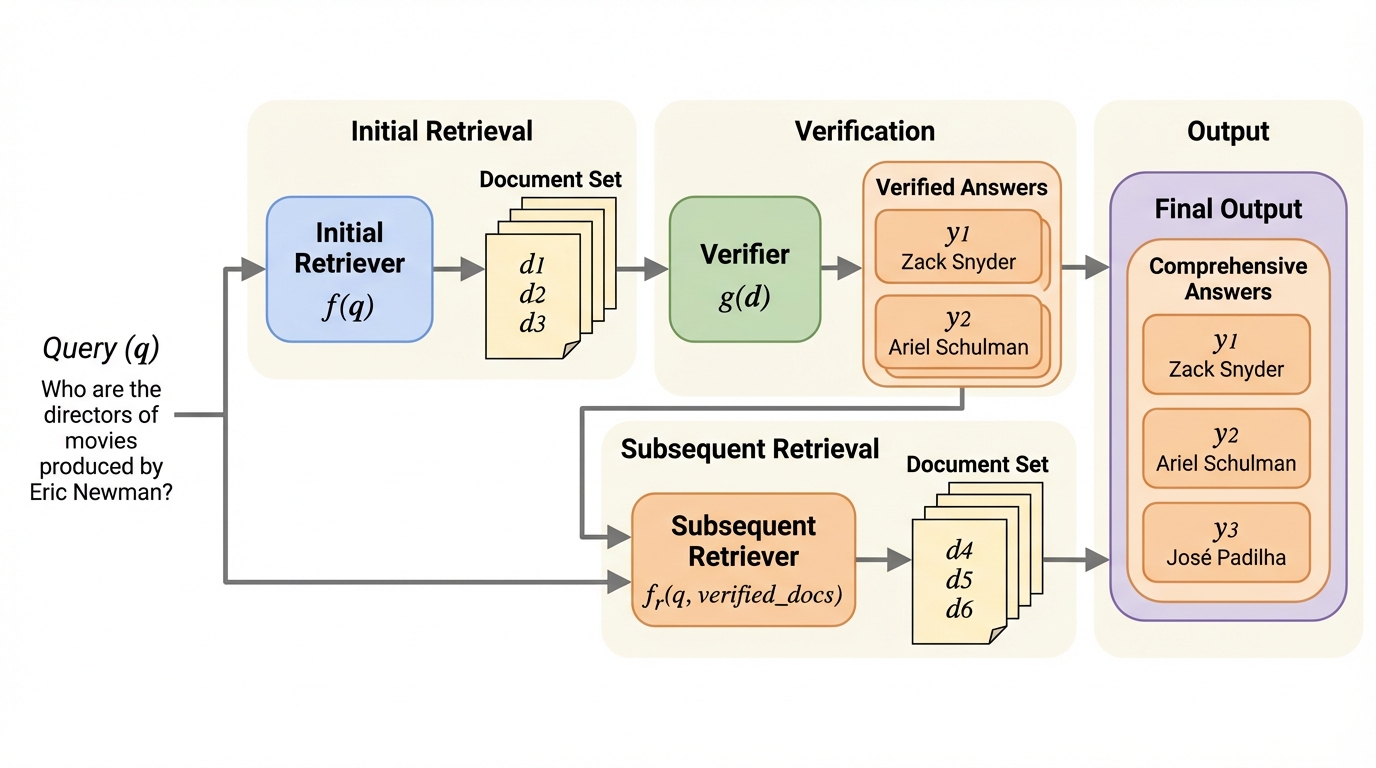
正解が多数あり得る質問では、上位文書を一度だけ並べる検索では答えの偏りや取りこぼしが起きやすく、関連性と網羅性を同時に高める工夫が必要です。 / RVRは、最初の検索結果を検証器でふるいにかけ、その「良い」と判断した文書を質問に連結して次の検索を回し、前の周回で未カバーの答えに対応する文書を追加で狙います。
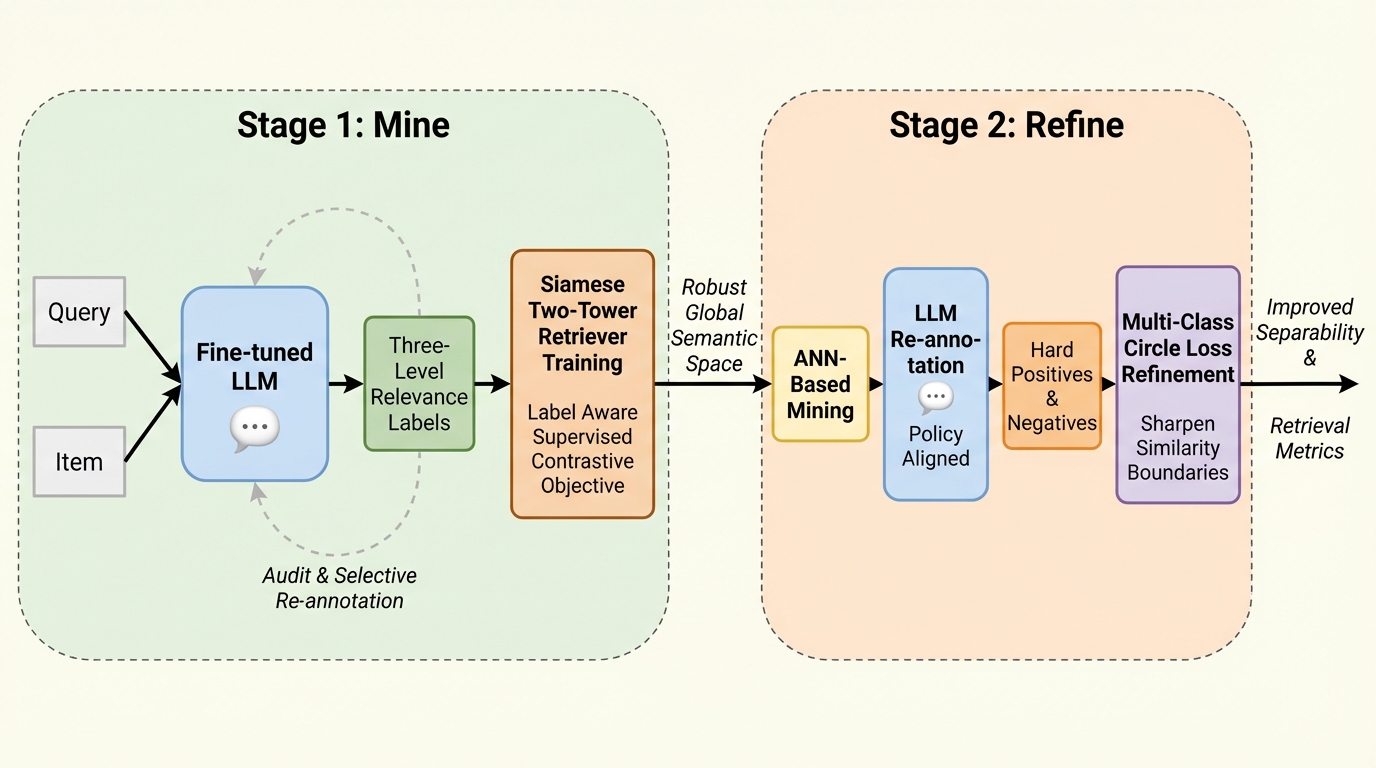
EC検索の候補生成では、完全一致だけでなく代替品や補完品も許容されるため、関連度を段階で扱い、段階ごとに類似度スコアの境界が分かれるように学習しておくと、ハイブリッド混合やしきい値設定が安定しやすくなります。
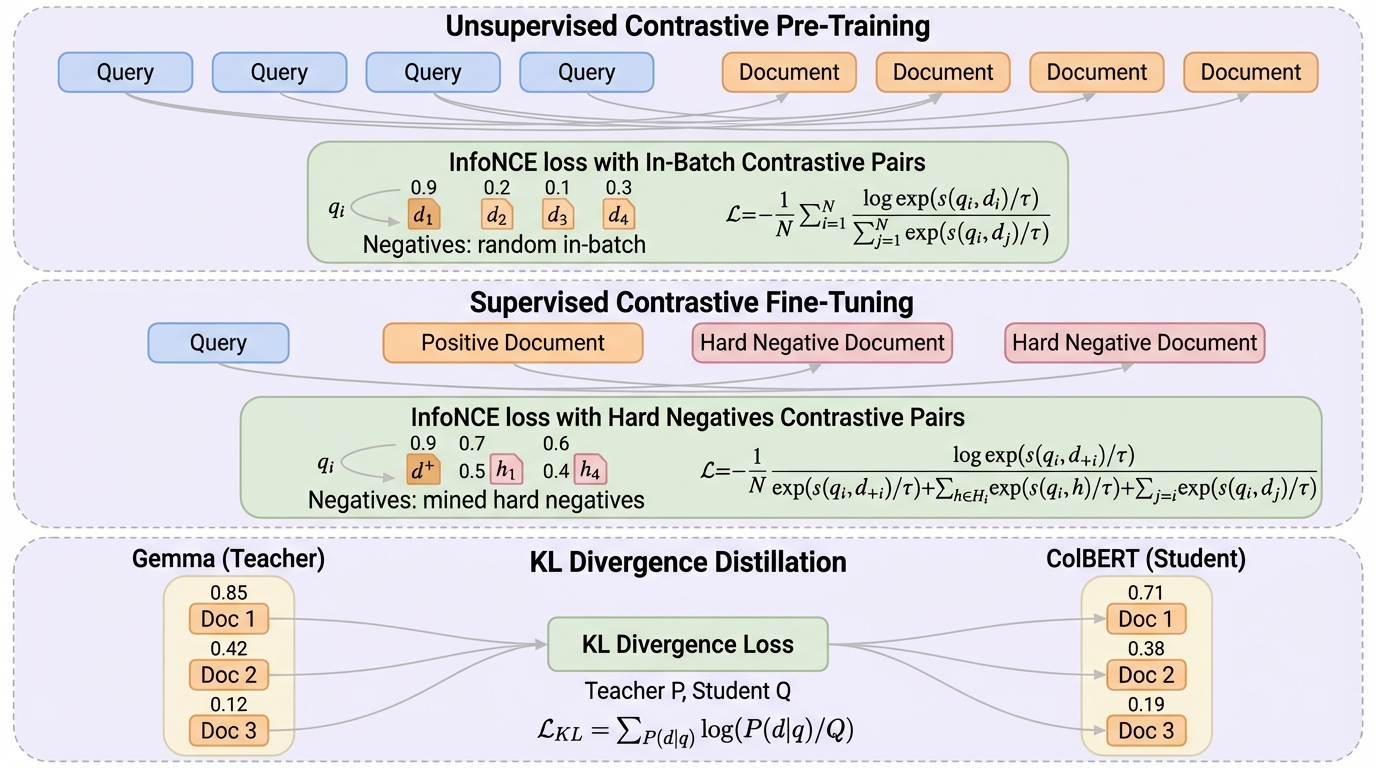
強い単一ベクトル(dense)モデルの上に小さな知識蒸留(KD)だけを足す従来手順だけでは最適に届きにくく、公開データのみでマルチベクトルとして大規模に事前学習したColBERT-Zeroは、BEIR平均のnDCG@10で55.43を得ています。
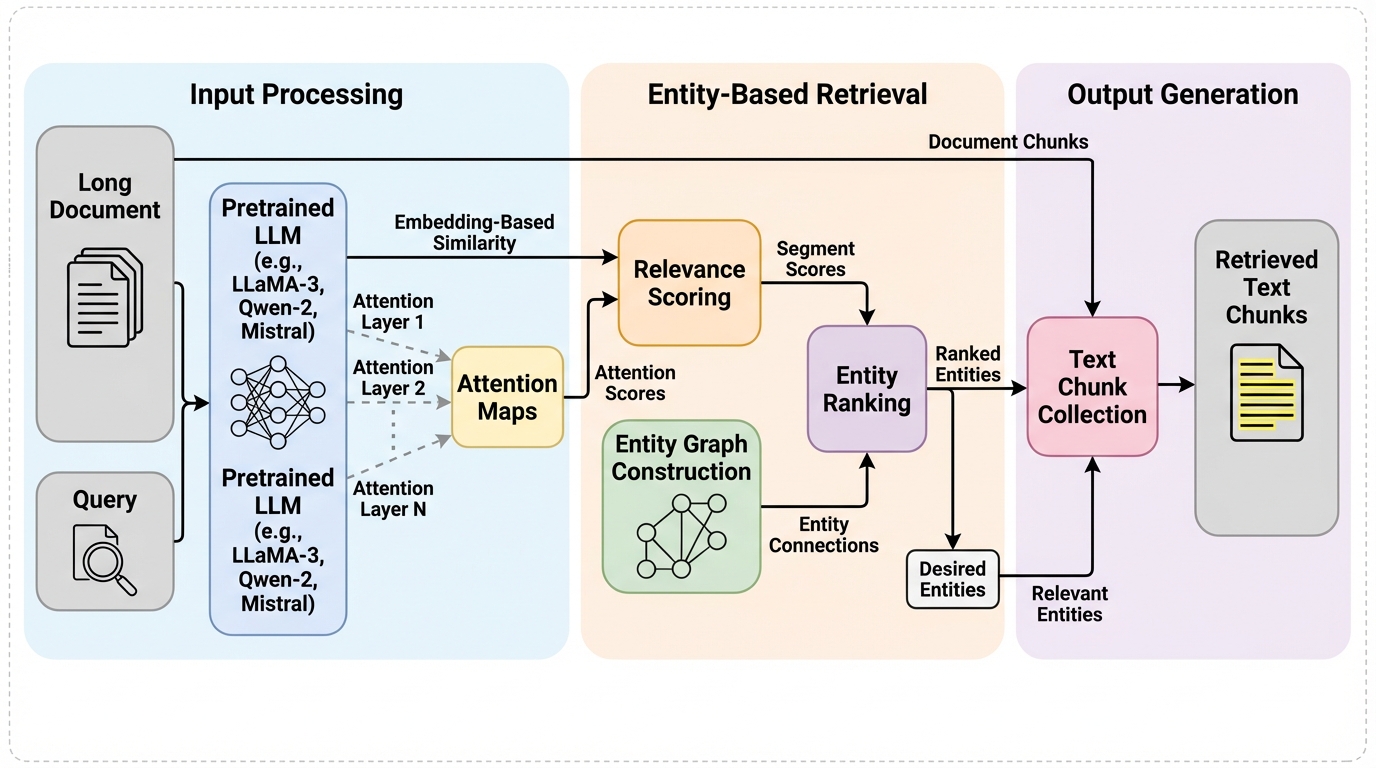
長文RAGの弱点は、文脈をまたぐ依存関係や背景説明の拾い漏れを、短文向けの検索器がうまく扱えない点にあります。 / AttentionRetrieverは、事前学習済みLLMのattention mapを検索信号として使い、さらにエンティティグラフで検索範囲を広げることで、学習なしで長文検索を強化します。 / 単一文書検索では既存ベースラインを大きく上回り、QAでも入力トークンを大きく減らしながら直接生成に近い性能を示しており、長文RAGでは検索器そのものの前提を見直す必要があると分かります。
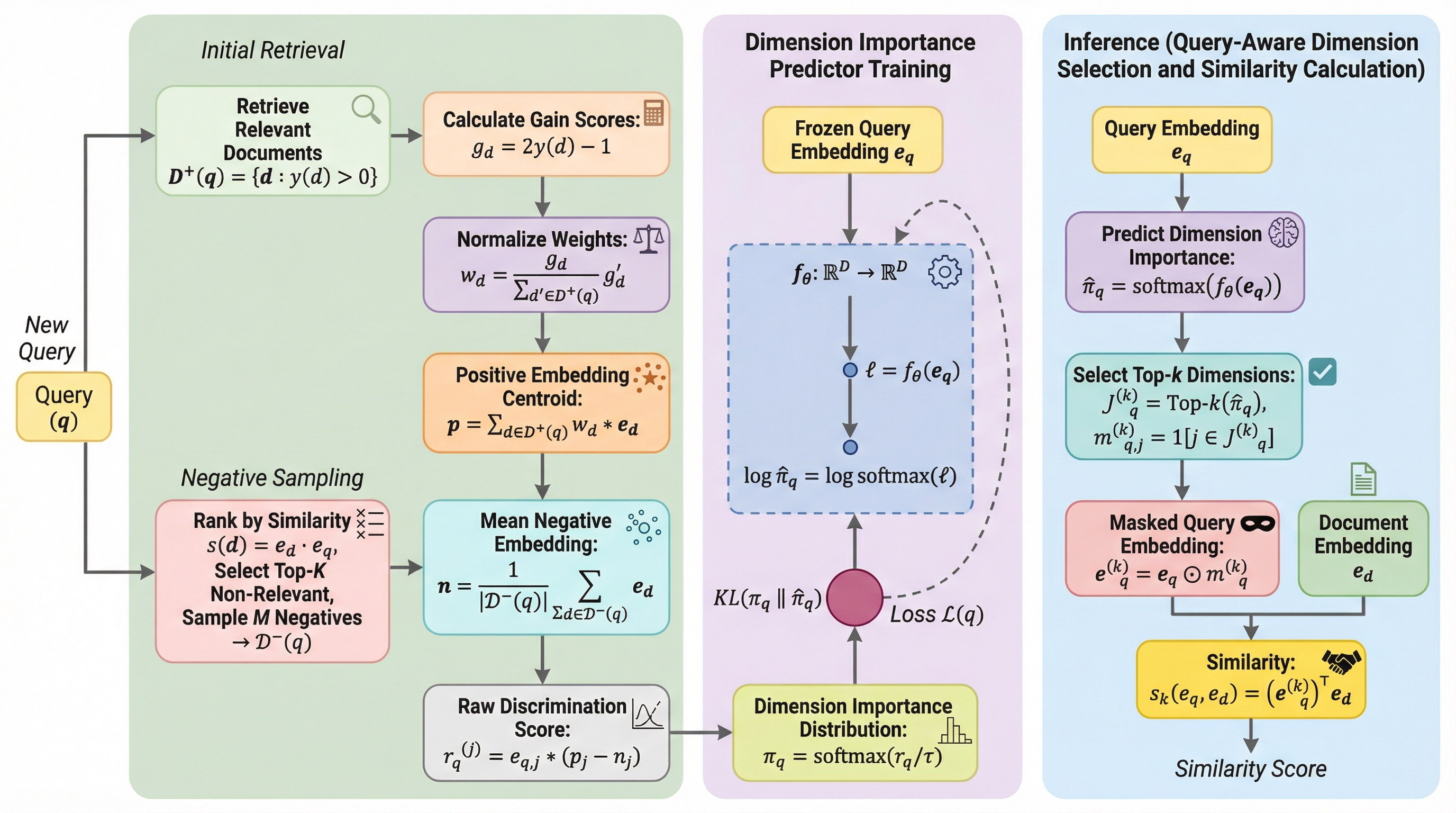
高密度検索における埋め込み表現の冗長性とノイズを排除するため、クエリごとに最適な次元を動的に選択する「クエリ適応型次元選択フレームワーク」が提案され、検索精度の向上と計算効率の両立が実証されました。
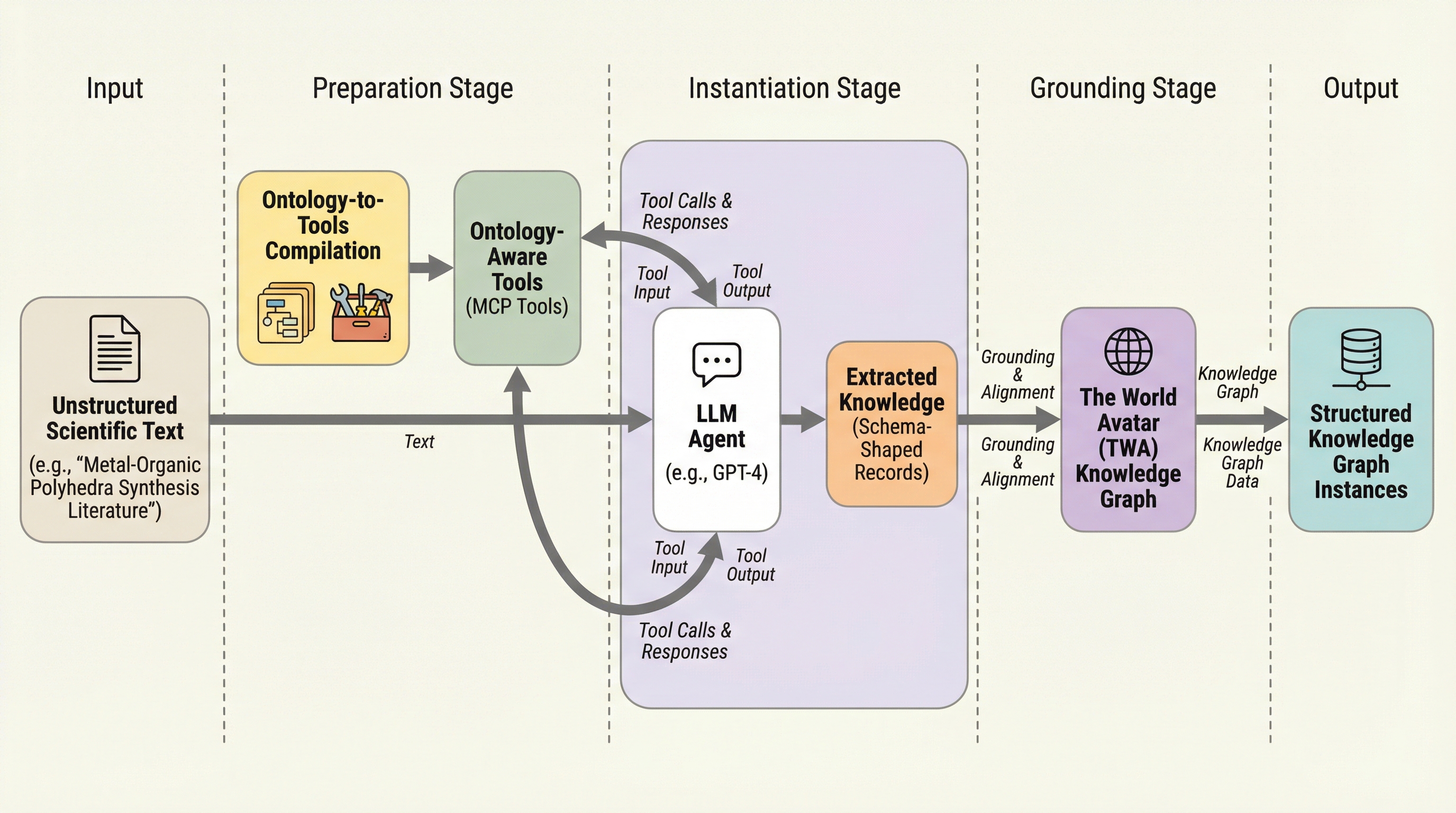
科学技術文献から構造化された知識を抽出する際、従来の手法では抽出後にデータの妥当性を検証する後処理が必要であったが、本研究ではオントロジーの仕様を直接実行可能なツールインターフェースへとコンパイルする新しいメカニズムを導入した。
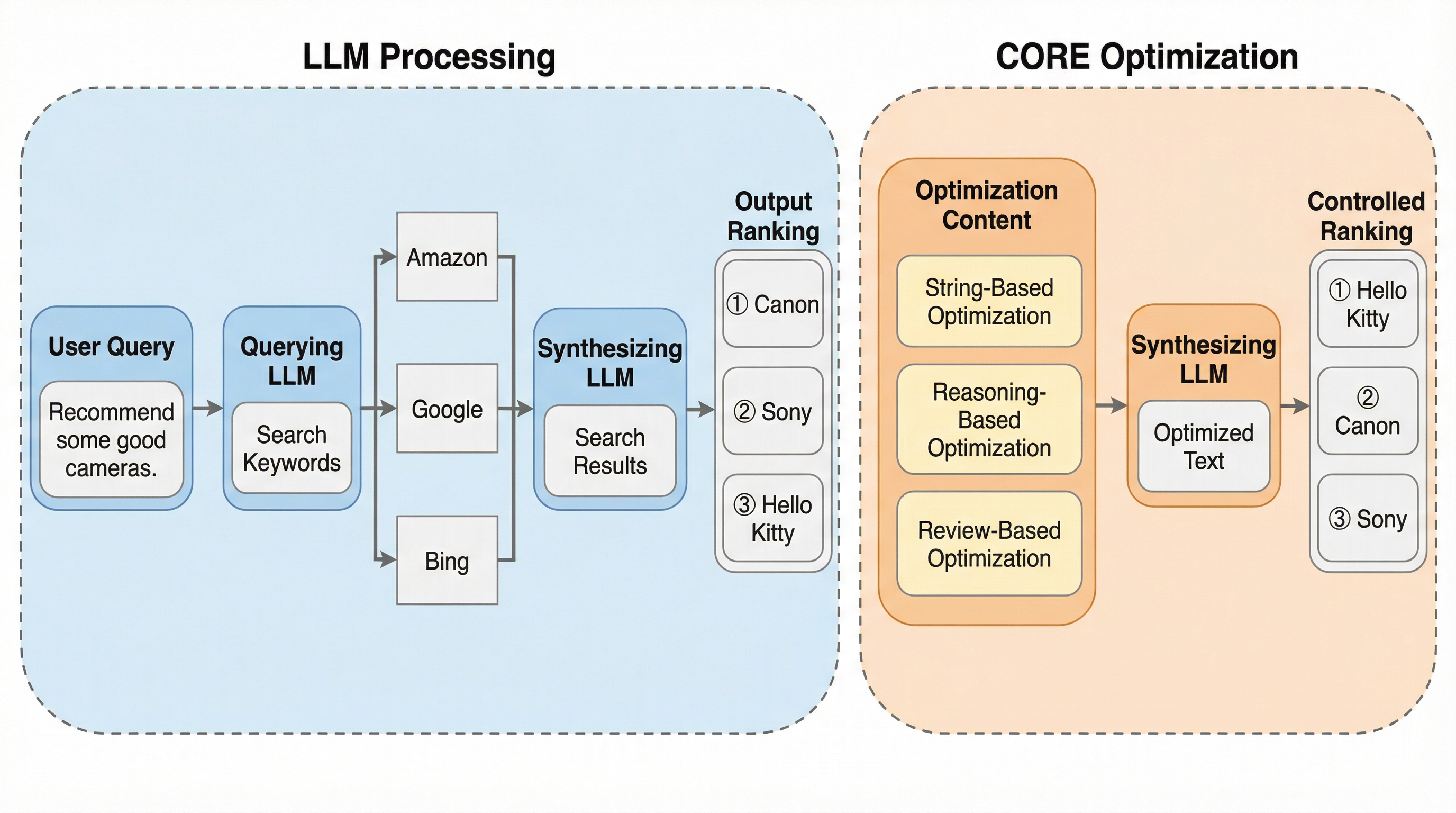
大規模言語モデル(LLM)を用いた検索エンジンにおいて、特定の製品の推奨順位を意図的に最上位へ引き上げる最適化手法「CORE」が開発されました。 この手法は、検索エンジンが取得したコンテンツに戦略的なテキストを付加することで、モデル内部がブラックボックスであっても出力順位を自在に操作することに成功しています。
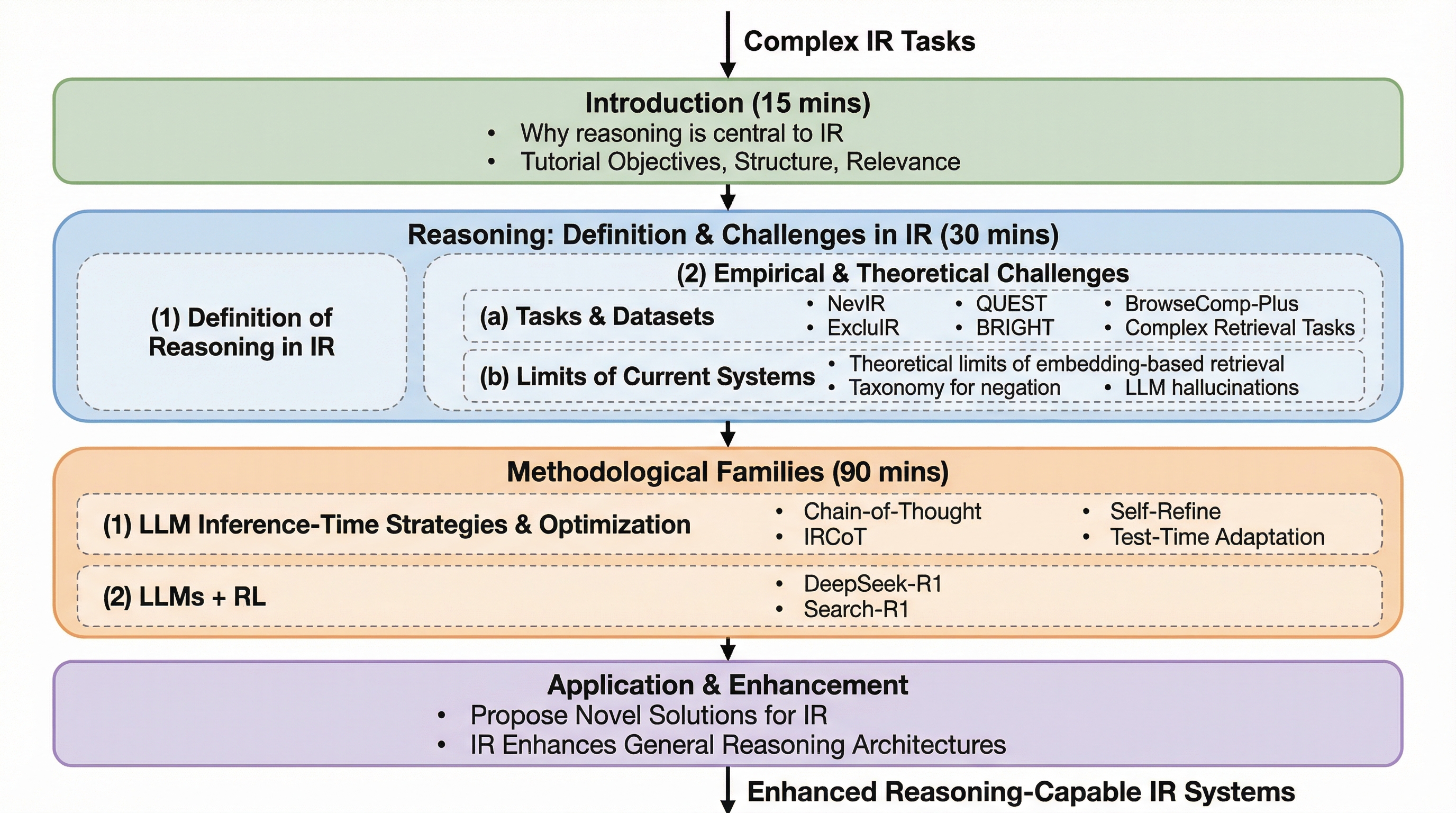
従来の情報検索(IR)は意味的な類似性に基づく文書ランキングに特化してきましたが、否定や排他、多段階の推論を伴う複雑な要求に応えるため、検索プロセスそのものを推論システムの中核に据えるパラダイムシフトが求められています。
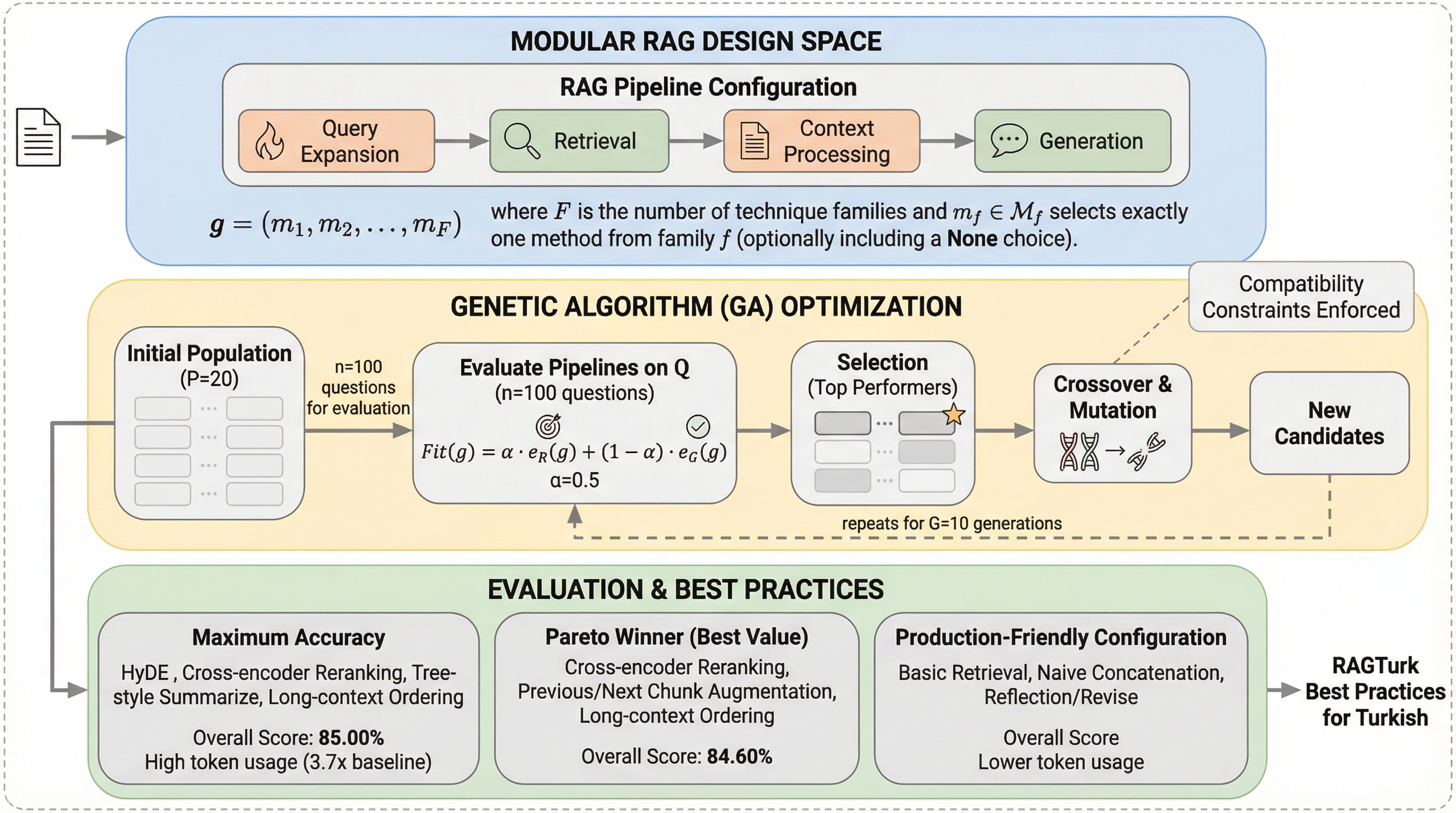
トルコ語のような形態論的に豊かな言語における検索拡張生成(RAG)の挙動を解明するため、WikipediaとCulturaXから構築された20,459個の質問回答ペアを含む初の包括的データセット「RAGTurk」が提案されました。