LEMUR: 学習ベースのマルチベクトル検索フレームワーク
情報検索において高い精度を誇るColBERTなどのマルチベクトルモデルは、MaxSim計算の複雑さゆえに検索遅延が非常に大きいという課題を抱えていました。本研究で提案されたLEMURは、このマルチベクトル検索を教師あり学習による回帰問題として再定義し、最終的に潜在空間上の単一ベクトルによる近似近傍探索へと変換することで、既存の高速な検索ライブラリの活用を可能にしました。 検証の結果、LEMURは従来のマルチベクトル検索手法と比較して1桁(約10倍)以上の高速化を達成しており、最新のテキスト検索モデルや視覚的な文書検索モデルにおいても、高い再現率を維持しながら劇的なパフォーマンス向上を実現することが確認されました。 このフレームワークは、軽量なニューラルネットワークを用いてトークン単位の埋め込みを潜在空間上の単一ベクトルへと集約し、ドキュメントの重み行列との内積計算によって類似度を推定する仕組みを採用しており、大規模なコーパスに対しても効率的なインデックス作成と高速な検索を両立させています。
TL;DR(結論)
情報検索において高い精度を誇るColBERTなどのマルチベクトルモデルは、MaxSim計算の複雑さゆえに検索遅延が非常に大きいという課題を抱えていました。本研究で提案されたLEMURは、このマルチベクトル検索を教師あり学習による回帰問題として再定義し、最終的に潜在空間上の単一ベクトルによる近似近傍探索へと変換することで、既存の高速な検索ライブラリの活用を可能にしました。 検証の結果、LEMURは従来のマルチベクトル検索手法と比較して1桁(約10倍)以上の高速化を達成しており、最新のテキスト検索モデルや視覚的な文書検索モデルにおいても、高い再現率を維持しながら劇的なパフォーマンス向上を実現することが確認されました。 このフレームワークは、軽量なニューラルネットワークを用いてトークン単位の埋め込みを潜在空間上の単一ベクトルへと集約し、ドキュメントの重み行列との内積計算によって類似度を推定する仕組みを採用しており、大規模なコーパスに対しても効率的なインデックス作成と高速な検索を両立させています。
なぜこの問題か
現代の情報検索システムにおいて、深層ニューラルネットワークによって生成された埋め込みベクトルは不可欠な役割を果たしています。従来の単一ベクトル方式では、クエリと文書をそれぞれ一つの点として表現し、その内積やコサイン類似度によって類似度を測定しますが、この手法は計算が非常に効率的である一方で、複雑な意味関係を捉える表現力には限界がありました。これに対し、ColBERTに代表されるマルチベクトルモデルは、トークンごとに個別の埋め込みを生成し、それらの間の最大類似度の総和であるMaxSimを用いることで、より精密で文脈に即した検索精度を実現しています。しかし、この優れた精度は、検索時の膨大な計算コストという大きな代償を伴います。クエリの各トークンと文書の各トークンの組み合わせすべてを考慮して最大値を探索する必要があるため、単一ベクトル方式に比べて検索遅延が著しく増大し、大規模な実用システムへの導入を困難にしていました。 この問題を解決するために、これまでにトークン単位での枝刈りを行う手法や、固定次元のエンコーディングを用いる手法などが提案されてきました。…
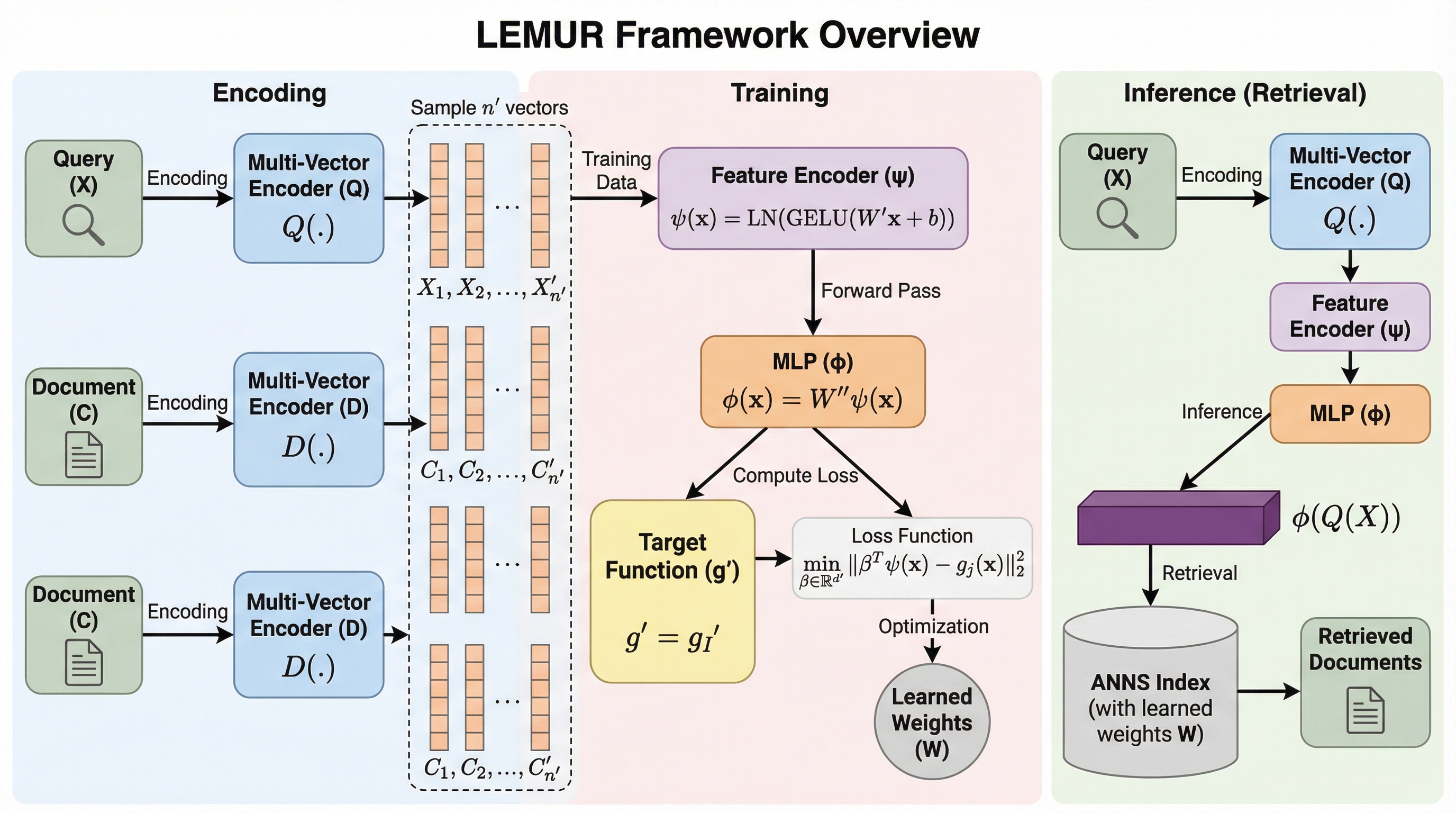
核心:何を提案したのか
本論文では、マルチベクトル検索の効率性を劇的に向上させるためのシンプルかつ強力なフレームワークである「LEMUR(Learned Multi-Vector Retrieval)」を提案しています。LEMURの核心となるアイデアは、マルチベクトル間の類似度計算という複雑な問題を、二段階の連続的な問題変換によって簡略化することにあります。第一の変換では、クエリと各文書の間のMaxSim類似度を直接推定するタスクを、教師あり学習におけるマルチ出力回帰問題として定式化しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related