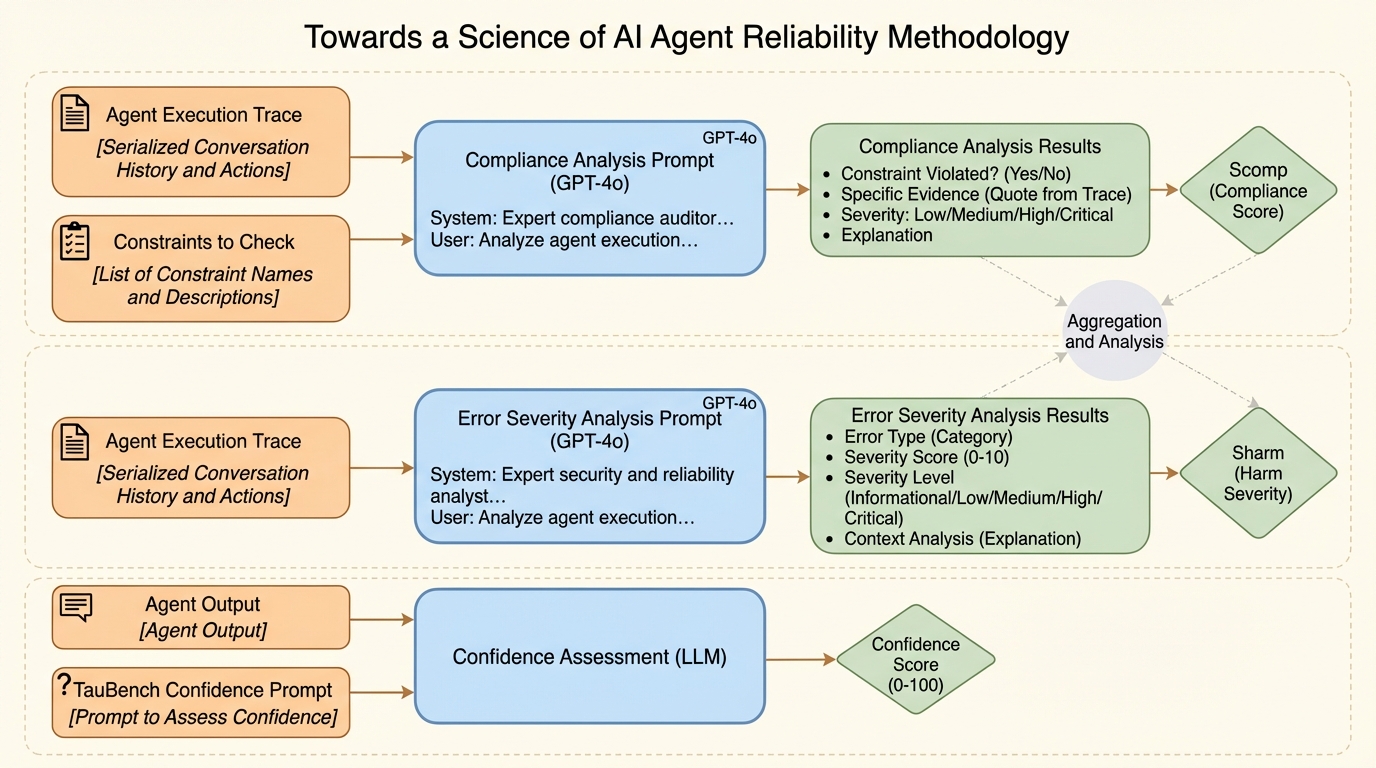
AIエージェントの信頼性を科学する:単一の成功率を超える12の指標で見える「運用上の弱さ」
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。
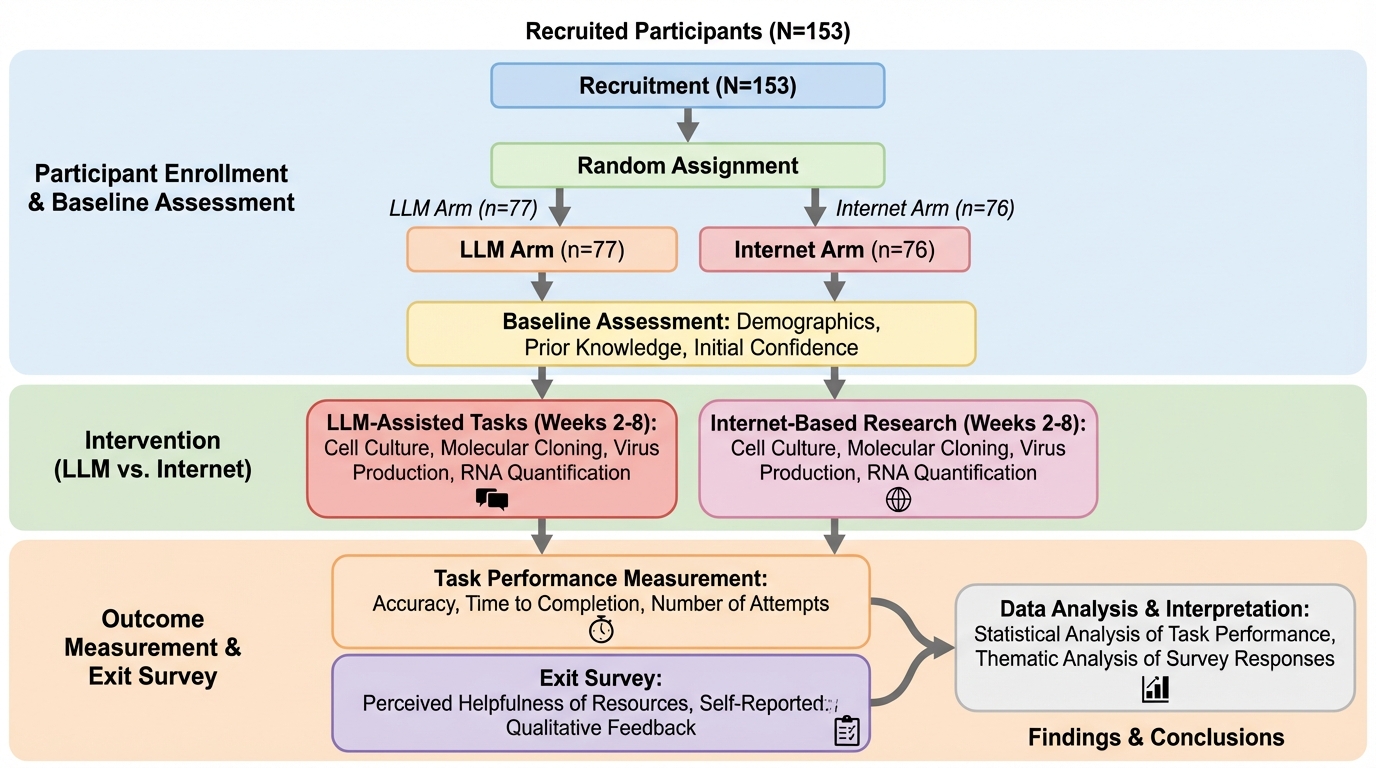
2025年中頃の大規模言語モデルを使える条件でも、初心者が「ウイルスのリバースジェネティクス」を模した一連の中核タスク(細胞培養・分子クローニング・ウイルス産生)を最後まで完了する割合は、インターネットのみの条件と統計的に有意な差が出ませんでした。
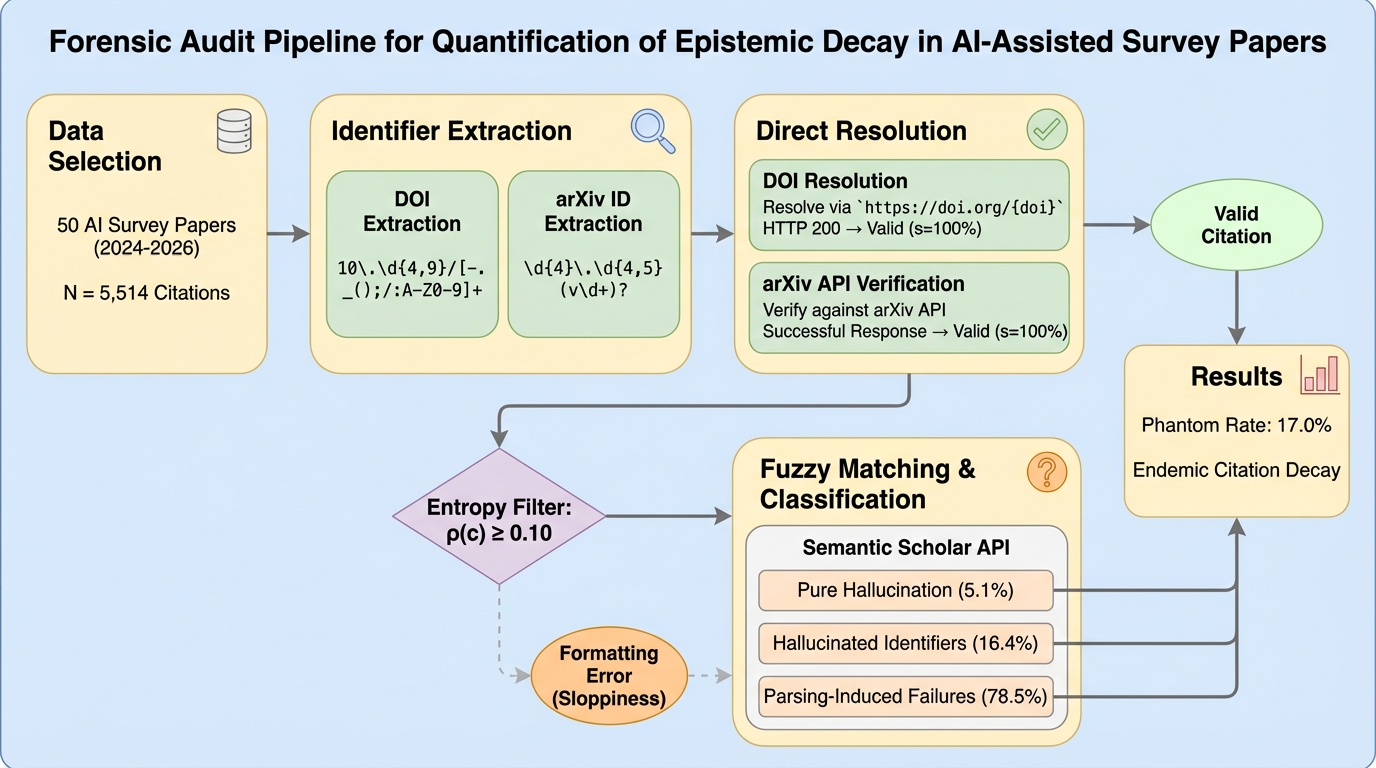
AI分野のサーベイ論文50本(引用総数5,514件)を調査した結果、デジタルオブジェクトとして特定できない「ファントム引用」が17.0%存在し、科学的根拠の連鎖が大規模に損なわれている実態が判明した。 この引用の劣化は、純粋な捏造(5.
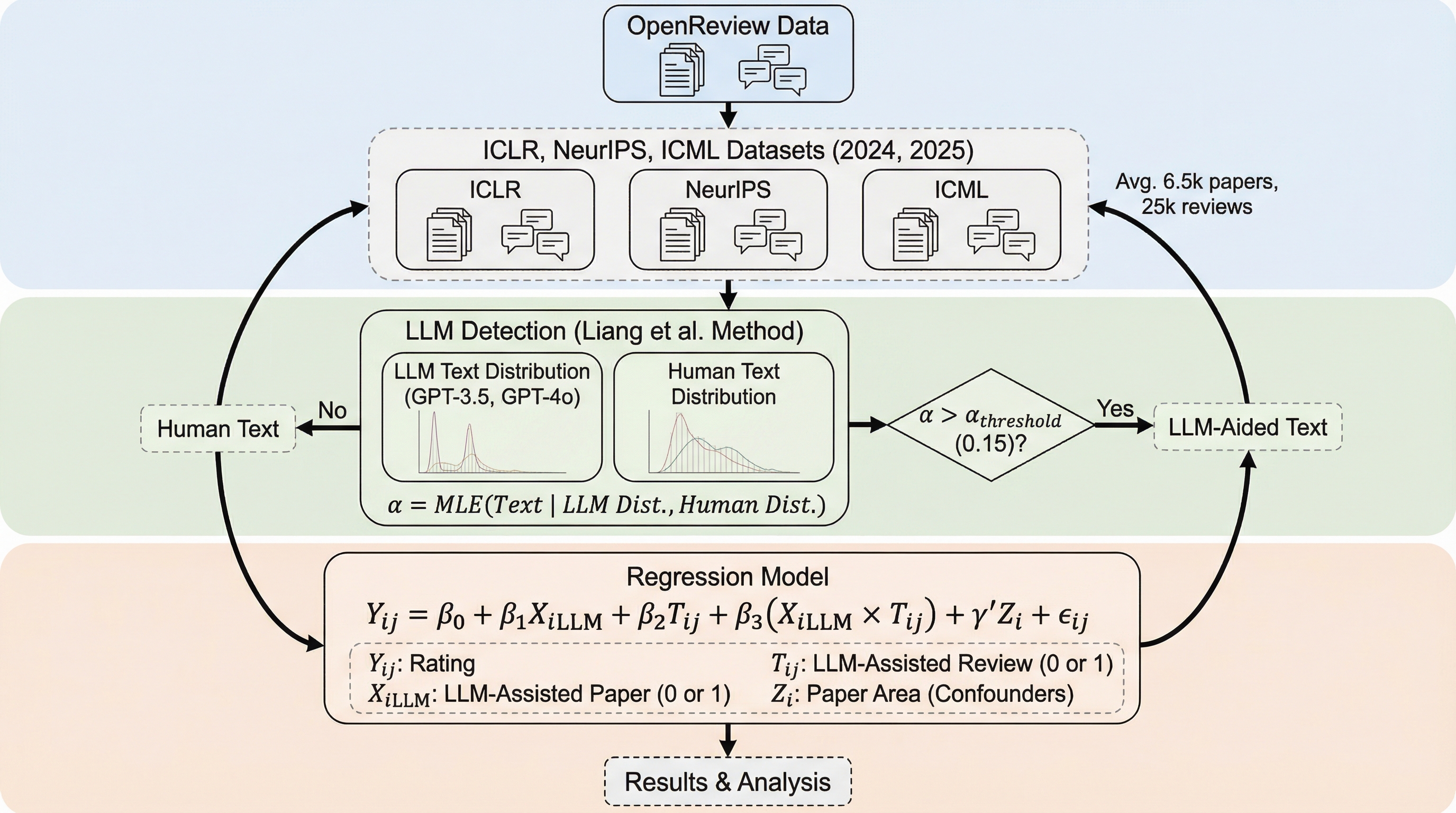
学術会議の査読において、LLMを用いた査読がLLM執筆の論文を不当に高く評価する「相互作用効果」の有無を、12万件以上のデータから検証した結果、初期分析で見られた「優遇」は、LLM査読が低品質な論文全般に対して寛容な評価を下す傾向に起因する見かけ上の現象であることが判明した。
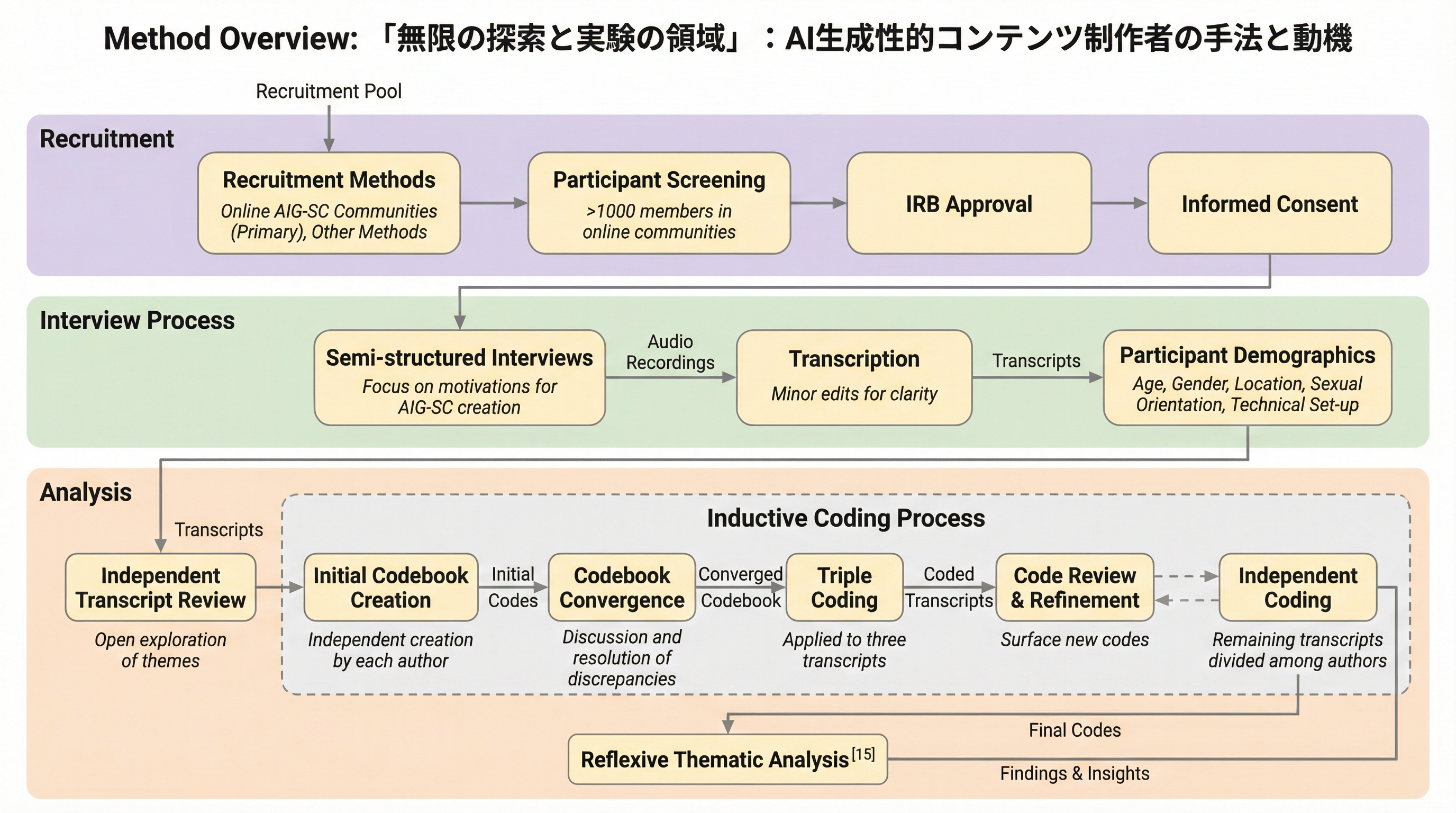
本研究は28名のAI生成性的コンテンツ(AIG-SC)制作者へのインタビューを通じ、彼らの背景、制作手法、および動機を明らかにした。制作者は技術職や芸術職、性産業従事者など多岐にわたり、独自のパイプラインやジェイルブレイクを用いてテキストや画像を生成している。
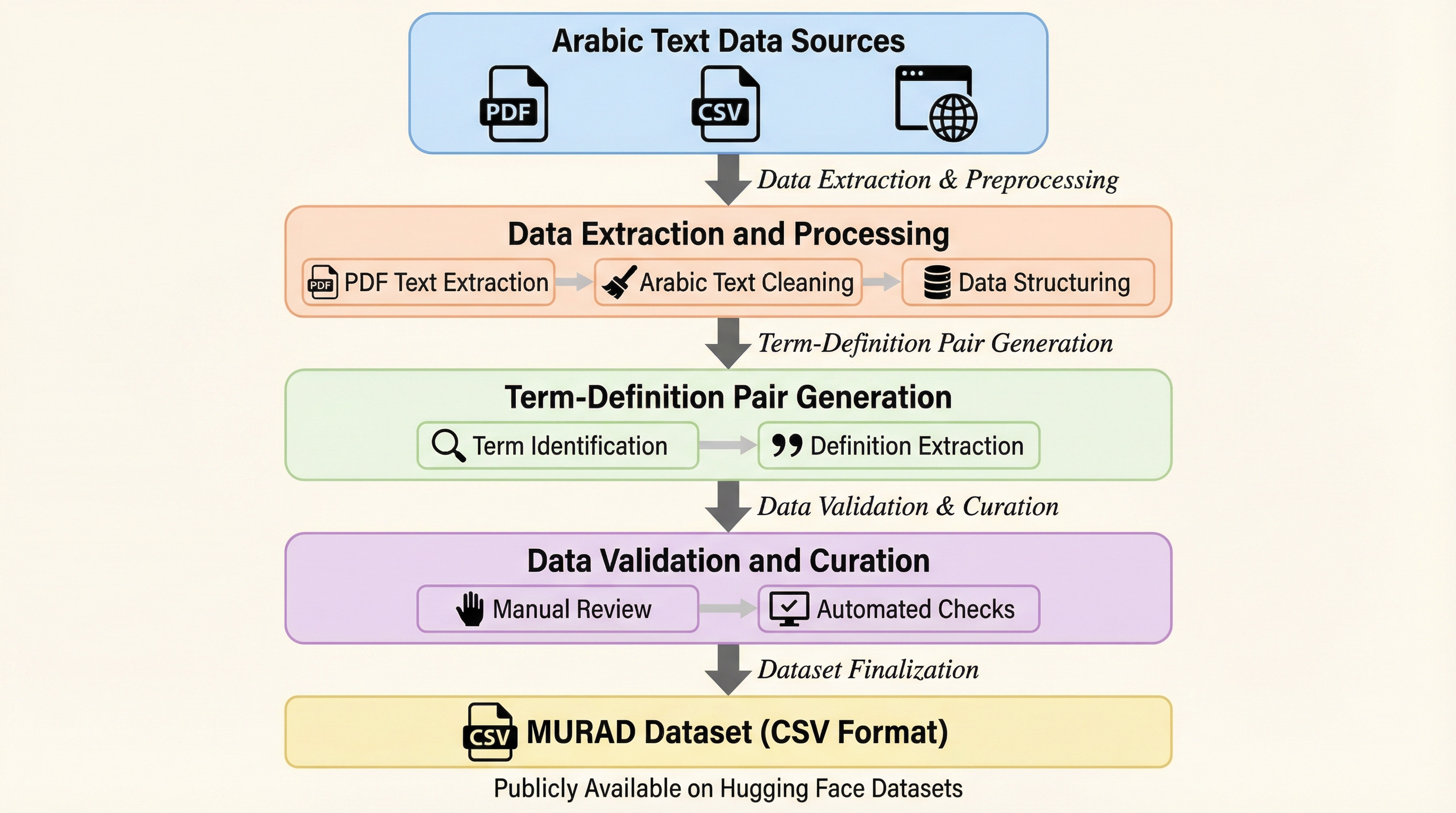
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.
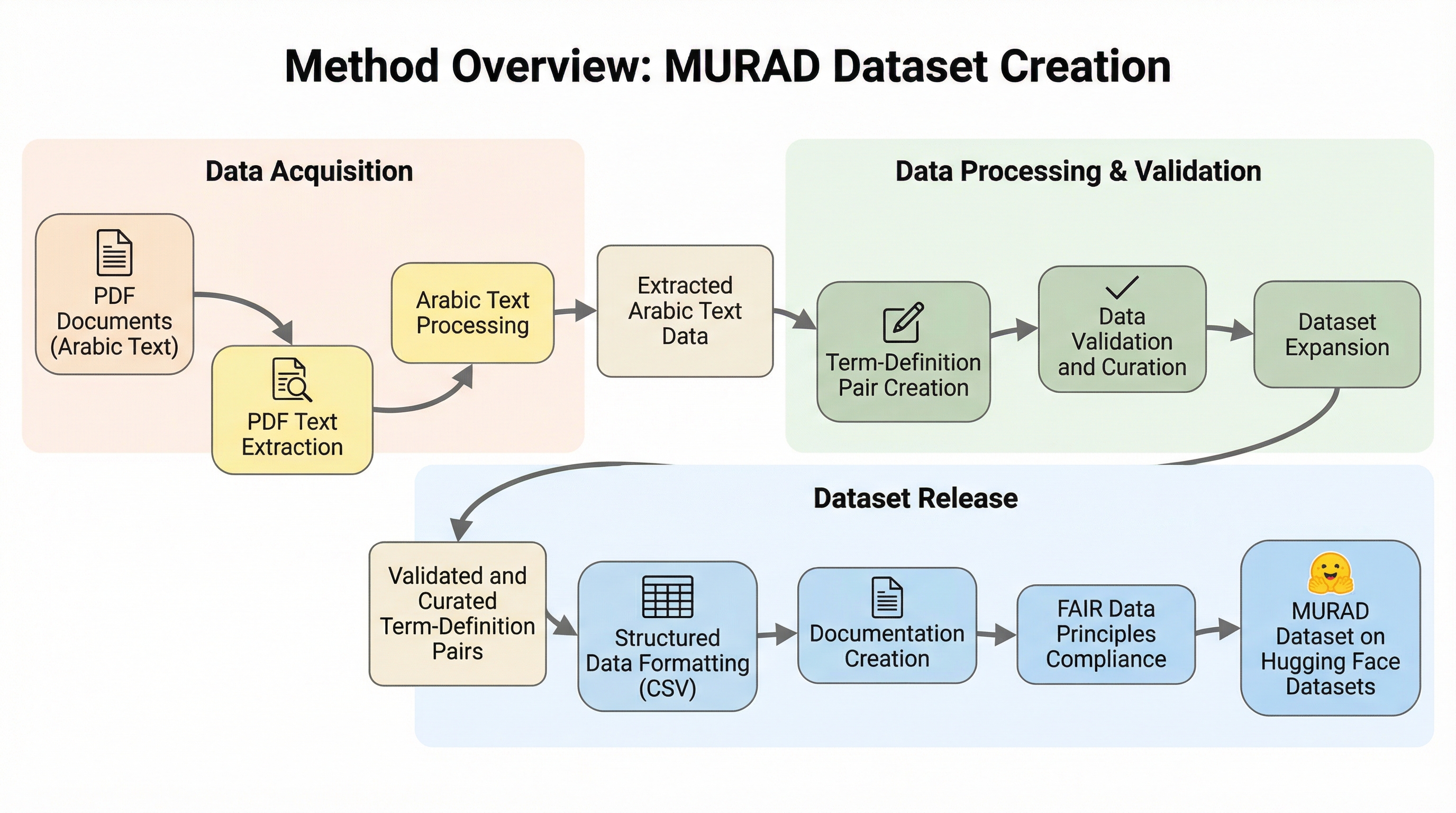
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。
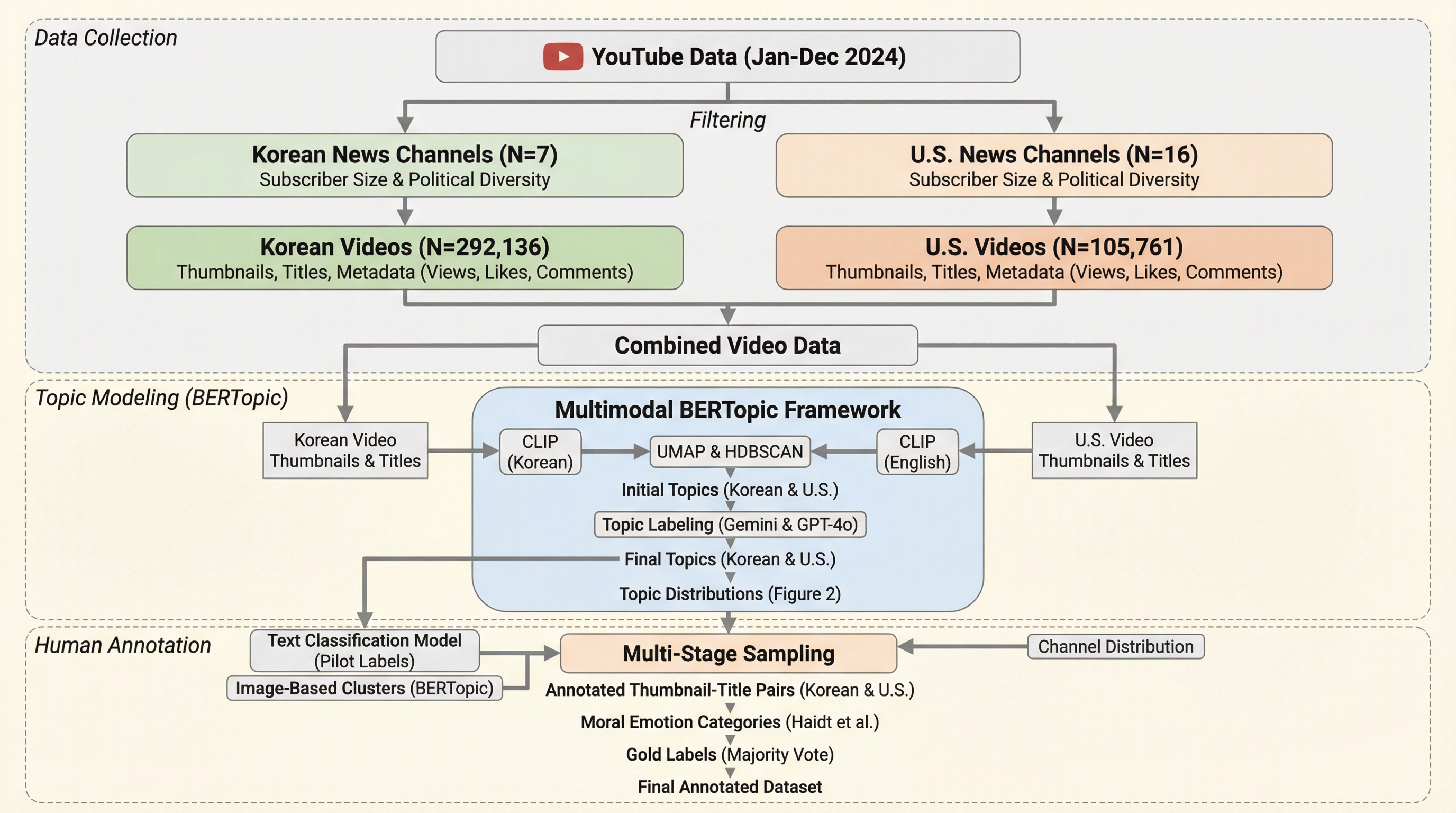
本研究は、YouTubeのニュース動画において、サムネイル画像とタイトルを組み合わせたマルチモーダルな分析を行い、道徳的感情のフレーミングがユーザーの関与に与える影響を韓国と米国の比較を通じて調査した。
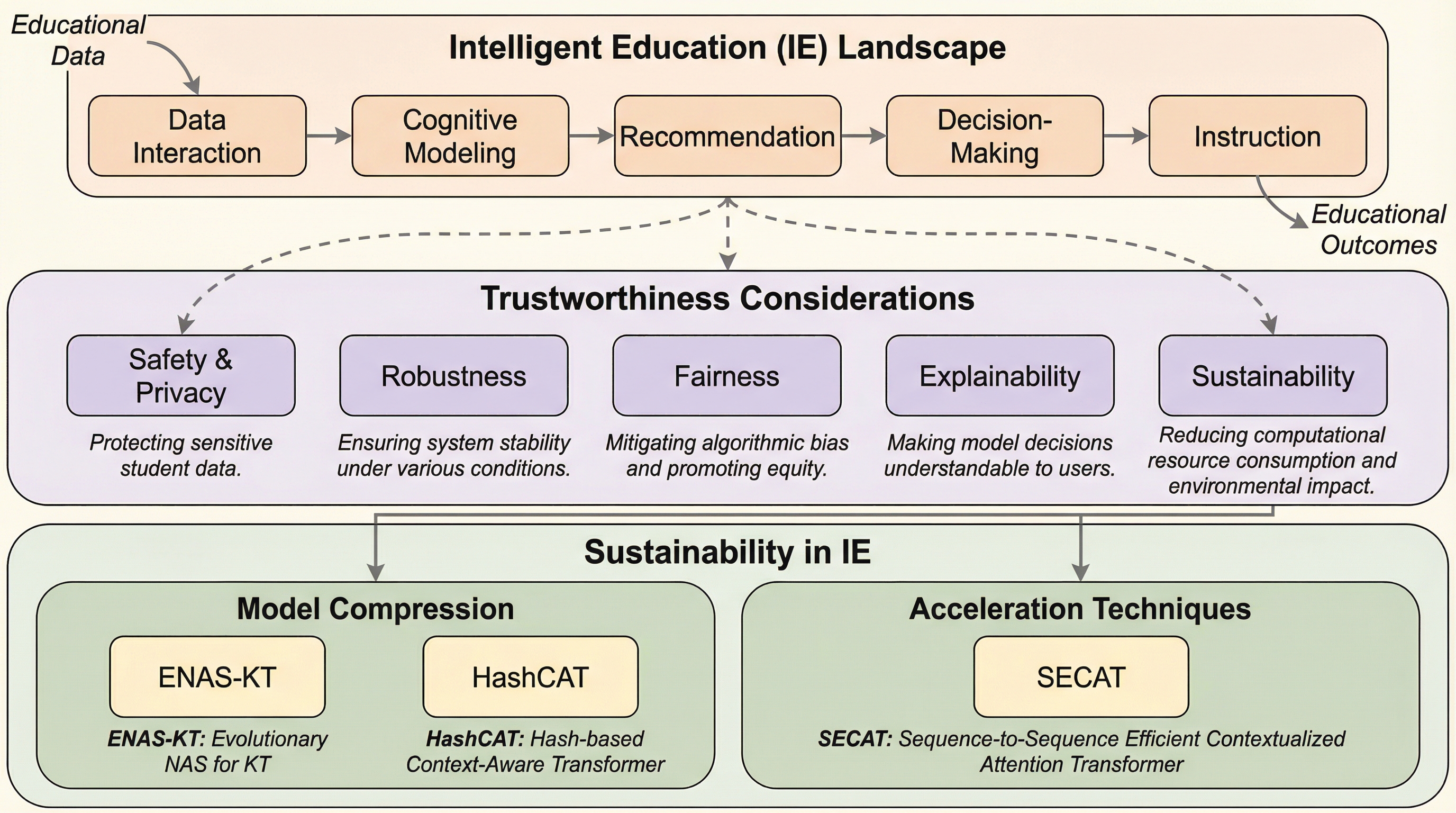
インテリジェント教育は、未成年者や脆弱なグループを含む機密性の高いデータを扱い、学習者の将来に直結する重要な意思決定を行うため、システムの「信頼性」の確保が不可欠な課題となっています。 本論文は、学習者能力評価や学習リソース推奨などの5つの主要タスクと、安全性・プライバシー、堅牢性、公平性、説明責任、持続可能性という5つの信頼性の観点を組み合わせた体系的なレビューを提供します。 既存研究の断片化を解消するための包括的な参照フレームワークを提示し、マルチモーダルな信頼性や大規模言語モデルを活用した教育支援など、将来の研究に向けた具体的なロードマップを明らかにしました。
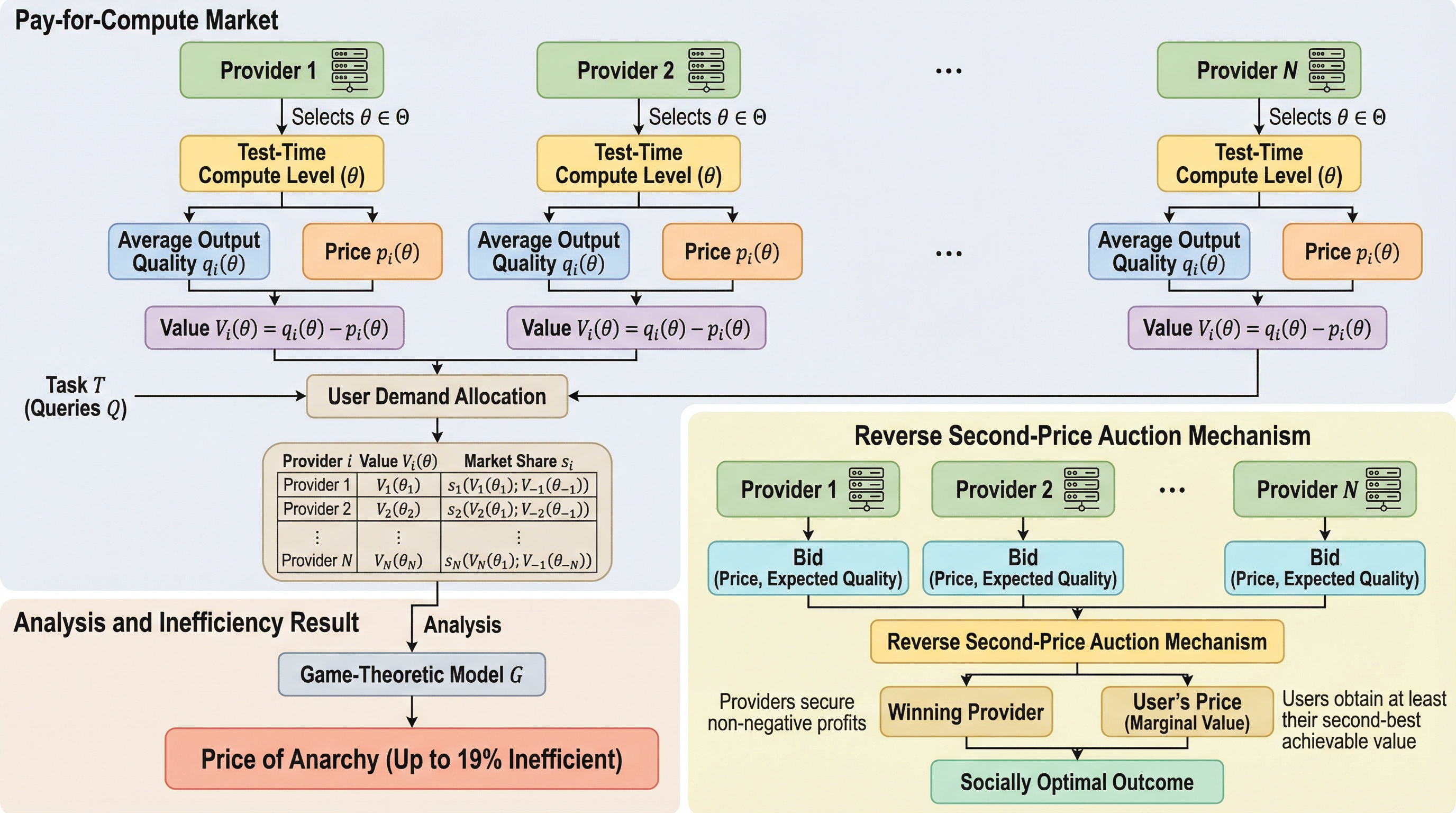
現在のLLM-as-a-service市場では、プロバイダーが利益を最大化するために、回答品質の向上にほとんど寄与しない場合でもテスト時計算量(TTC)を戦略的に増加させる経済的インセンティブが存在しており、これが社会的な非効率性を招いていることが明らかになった。