LLMはLLMを優遇するか?査読における相互作用効果の定量化
学術会議の査読において、LLMを用いた査読がLLM執筆の論文を不当に高く評価する「相互作用効果」の有無を、12万件以上のデータから検証した結果、初期分析で見られた「優遇」は、LLM査読が低品質な論文全般に対して寛容な評価を下す傾向に起因する見かけ上の現象であることが判明した。
TL;DR(結論)
学術会議の査読において、LLMを用いた査読がLLM執筆の論文を不当に高く評価する「相互作用効果」の有無を、12万件以上のデータから検証した結果、初期分析で見られた「優遇」は、LLM査読が低品質な論文全般に対して寛容な評価を下す傾向に起因する見かけ上の現象であることが判明した。 人間が介在しない完全に自動生成された査読は、論文の質を識別できず評価が中央に集中する「レーティング圧縮」を引き起こすが、人間がLLMを補助的に使用する場合にはこの傾向が抑制されており、人間による監督が査読の質を維持する重要な役割を果たしていることが実証された。 メタ査読においてもLLMの活用は最終決定に影響を与えており、同じ査読スコアであってもLLM補助がある場合は採択率が高まる傾向にある一方で、完全に自動生成されたメタ査読は逆に厳しい判断を下すという、AIと人間の複雑な相互作用の実態が浮き彫りになった。
なぜこの問題か
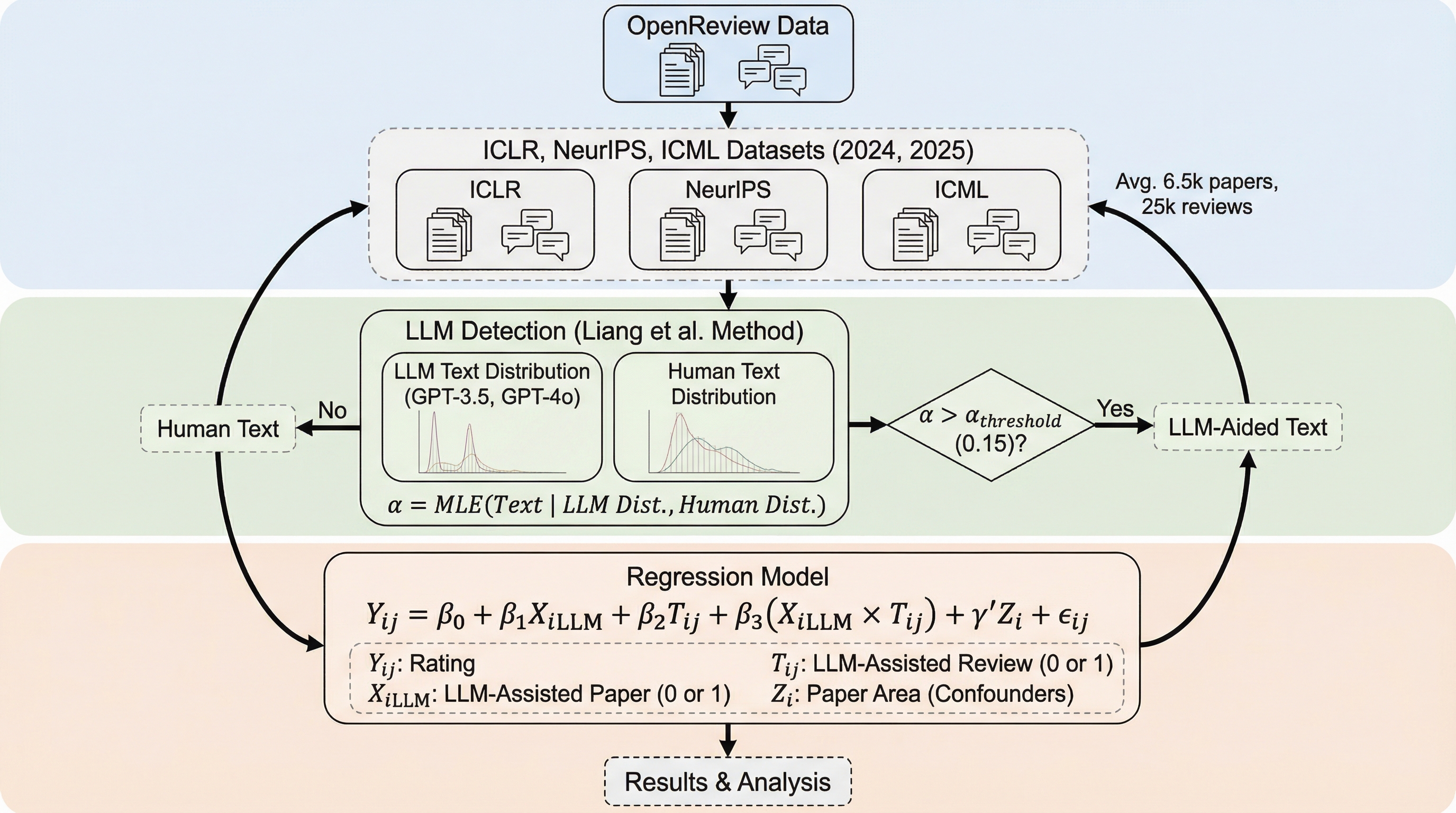
ChatGPTの登場以降、学術研究のワークフローにおいてLLM(大規模言語モデル)の導入が急速に進んでおり、現在では研究者の約81%が何らかの形でこれらのツールを業務に取り入れている。特に機械学習分野の主要な国際会議であるICLR、NeurIPS、ICMLにおいては、論文の執筆だけでなく査読プロセスにおいてもLLMの使用が疑われるケースが顕著に増加している。最新の統計データによれば、ICLRにおける査読文の約26.65%にLLMによる修正の痕跡が見られ、その割合はわずか1年でほぼ倍増するという急激な変化を遂げている。このような状況下で、研究コミュニティ内ではLLMが作成した査読の信頼性に対する懸念や、LLMが自身の出力特性に似た文章を好意的に評価する「自己強化バイアス」あるいは「自己愛的な偏り」への疑念が強まっている。 もしLLMを用いた査読がLLMを用いて書かれた論文を組織的に優遇するならば、学術的な公平性が根本から損なわれるだけでなく、著者が高い評価を得るためにLLMを悪用して文章を操作するという、評価システムのハッキングを助長するリスクも生じる。…
核心:何を提案したのか
本研究は、査読プロセスの全段階におけるLLMの使用を包括的に分析するための新しい定量的枠組みを提案し、12万5000件を超える論文と査読のペアを対象とした大規模な調査を実施した。この研究の核心は、単なる統計的な相関関係の提示ではなく、論文の分野や本来の質といった複雑な交絡因子を排除し、LLMの使用が評価に与える純粋な影響を分離して抽出した点にある。具体的には、論文のテキスト、メタデータ、査読スコア、および最終的な採否を決定するメタ査読のデータを統合し、執筆者と査読者の双方がLLMを使用している状況を「人間対人間」「人間対LLM」「LLM対人間」「LLM対LLM」という4つの象限に分類して詳細に比較した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related