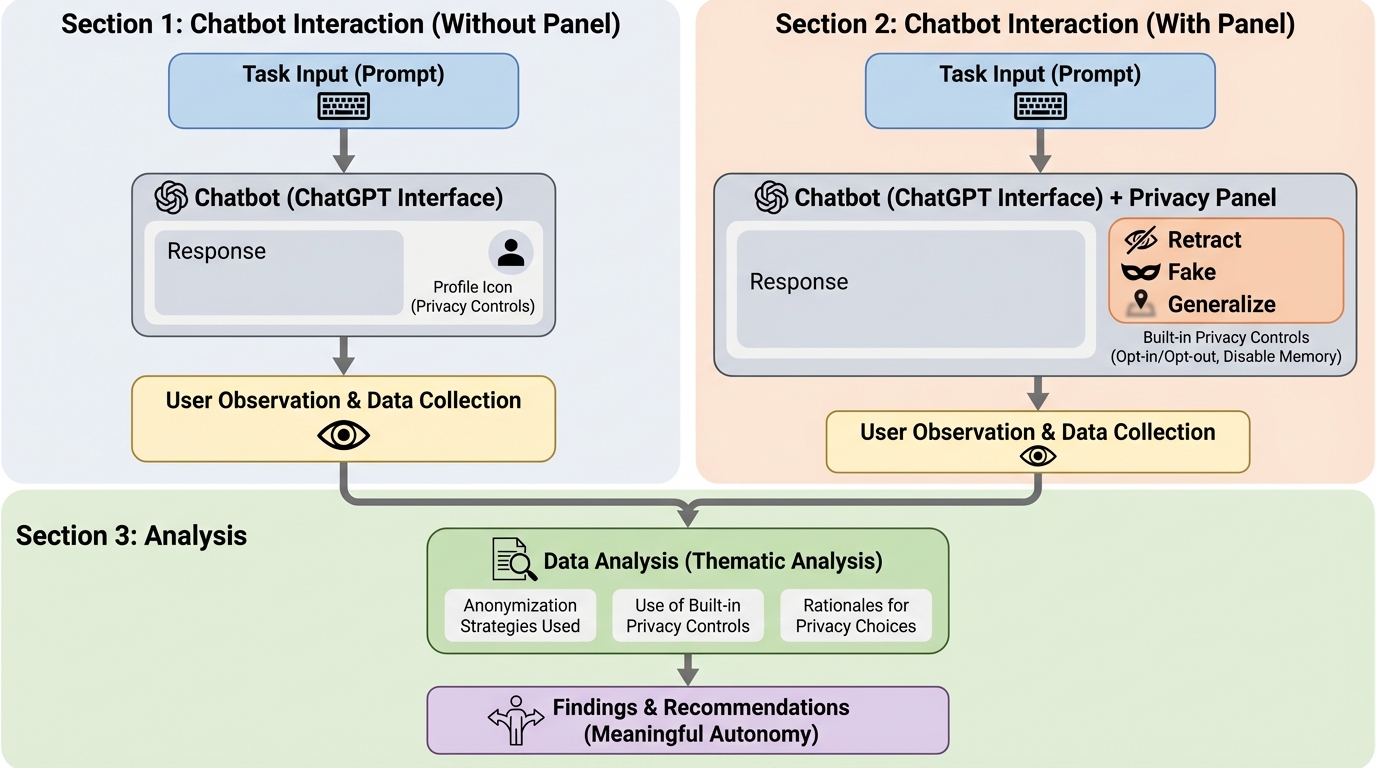
チャットボット利用時におけるユーザーのプライバシーに関する推論と行動の理解:プライバシーにおける有意義な主体性の支援に向けて
チャットボット利用時における機密情報の開示行動と保護行動を詳細に調査し、ユーザーが通常はタスクの効率性や利便性を優先してプライバシーを軽視しがちであること、およびその背後にある複雑で文脈依存的な意思決定のプロセスを明らかにした。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
チャットボット利用時における機密情報の開示行動と保護行動を詳細に調査し、ユーザーが通常はタスクの効率性や利便性を優先してプライバシーを軽視しがちであること、およびその背後にある複雑で文脈依存的な意思決定のプロセスを明らかにした。
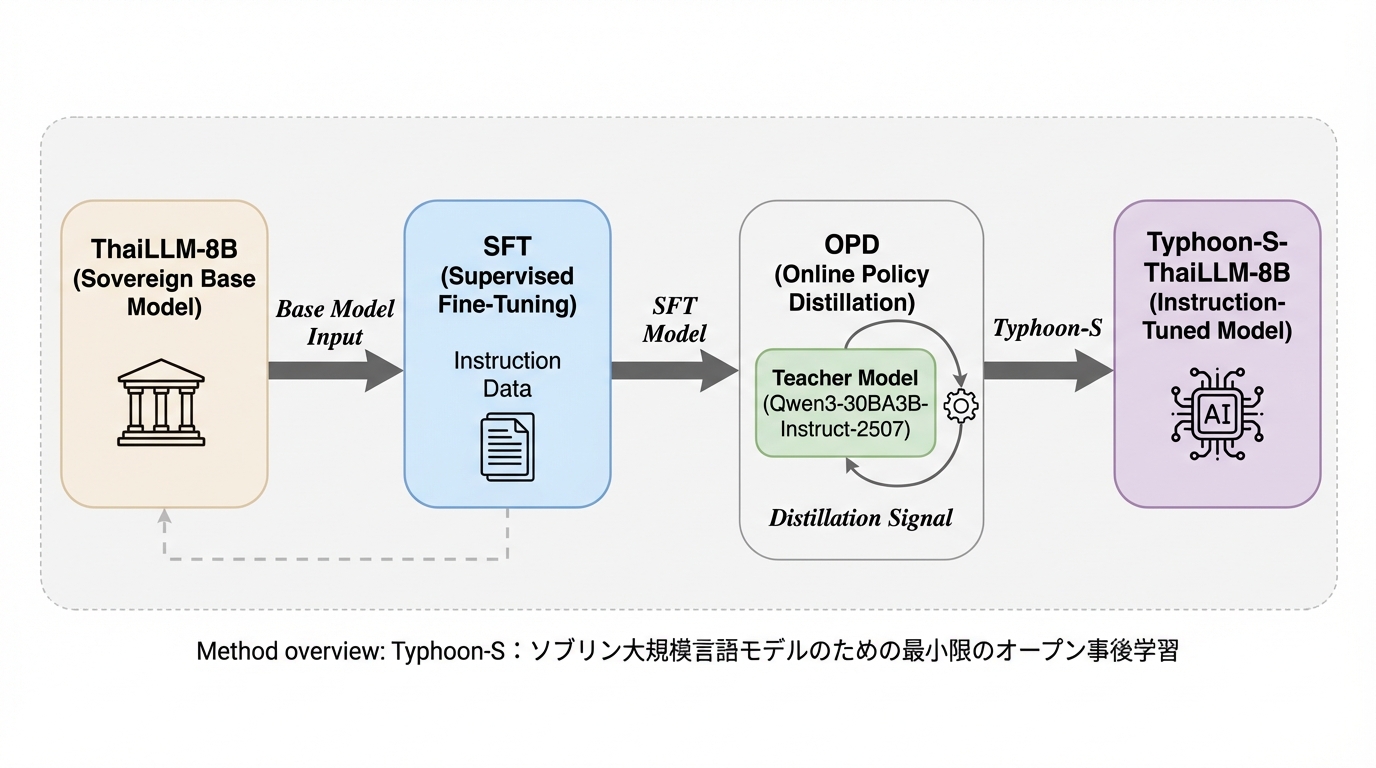
現在の大規模言語モデル開発は膨大な計算資源とデータを持つ一部の組織に集中しており、特定の地域や国が独自のデータ管理や制御を維持しつつモデルを構築する「ソブリン設定」において、リソースの制約が大きな障壁となっています。
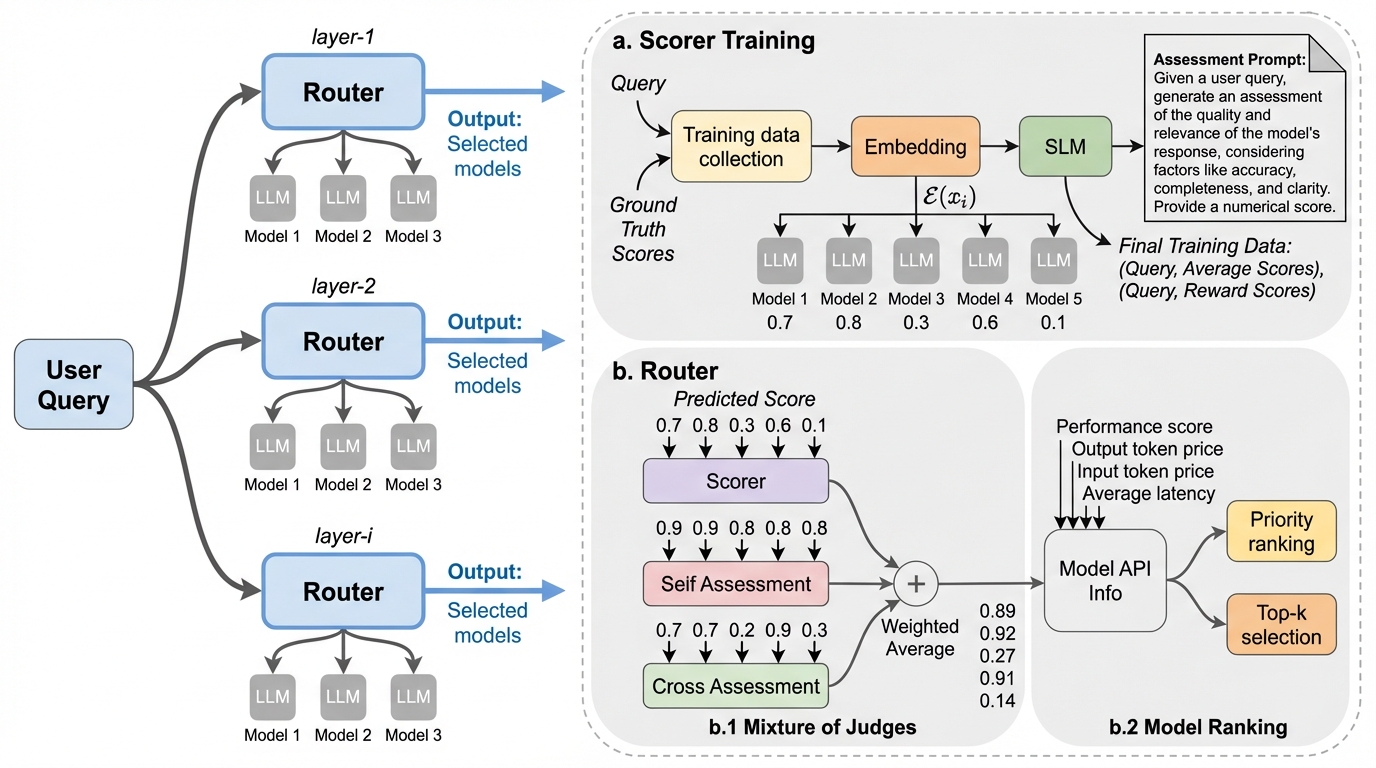
従来のMixture-of-Agents(MoA)は、全モデルを推論させてから統合するため計算コストと遅延が膨大でしたが、本研究は事前推論を行わずに最適なモデルを動的に選択する「RouteMoA」を提案しました。
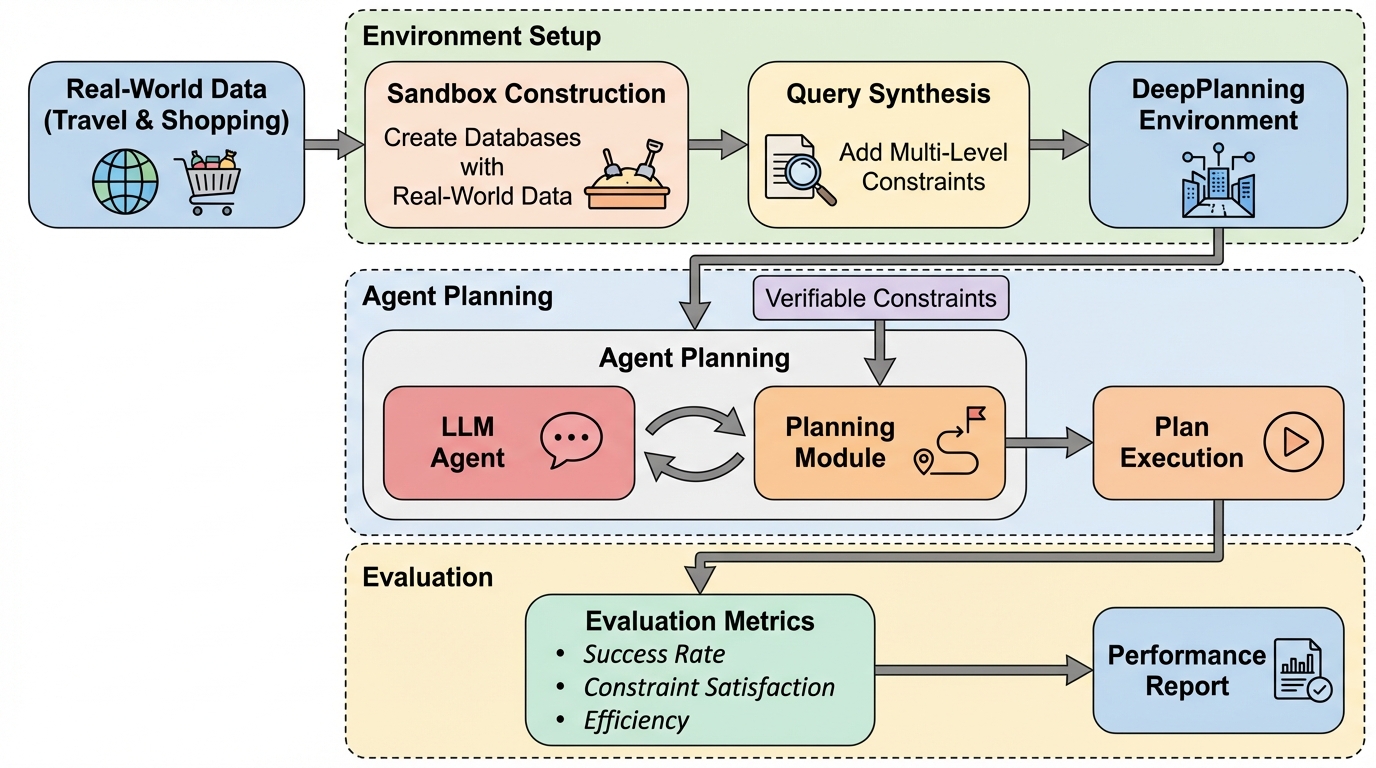
DeepPlanningは、大規模言語モデル(LLM)エージェントが持つ長期的な計画能力を多角的に評価するために開発された新しいベンチマークであり、従来の評価手法が重視していた局所的なステップ単位の推論を超えて、予算や時間といった全体的なリソース制約を最適化する真の計画能力を厳格に測定することを目的としている。
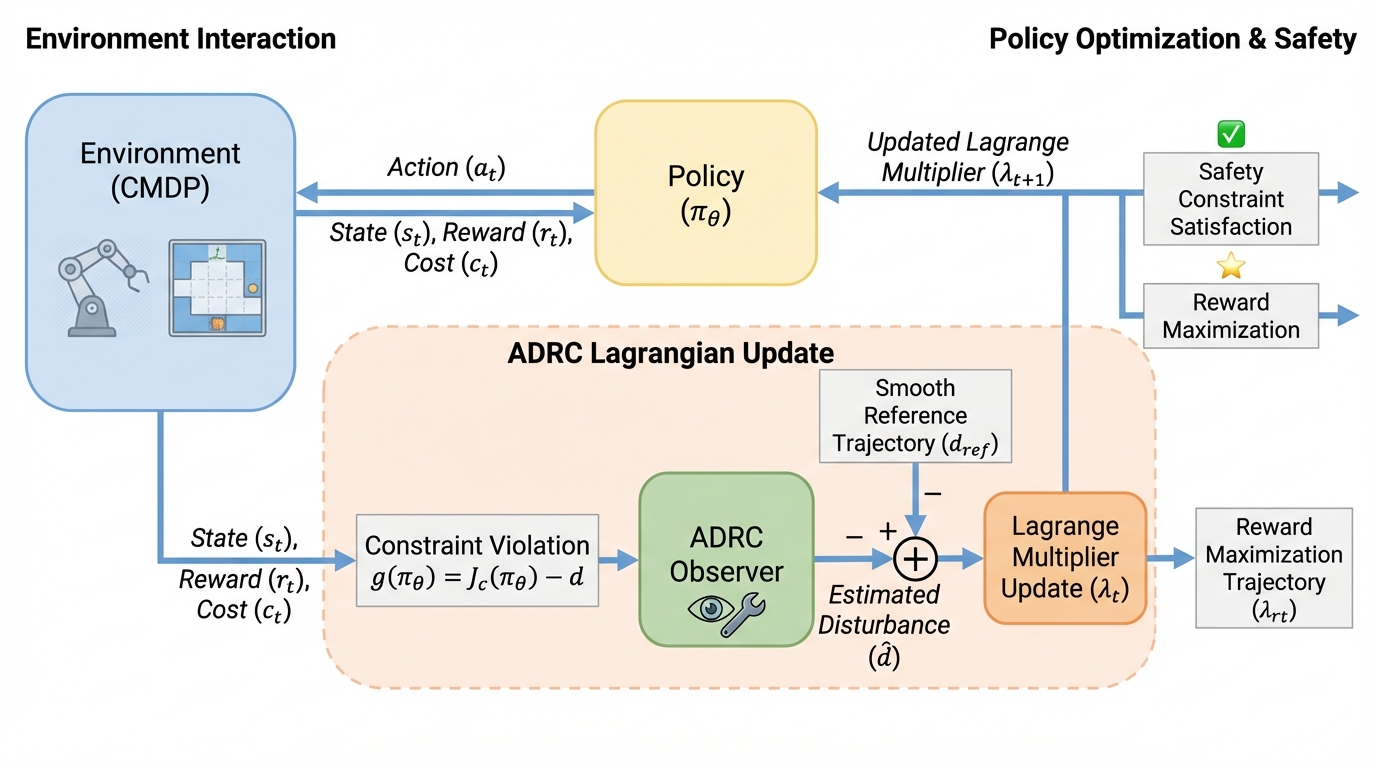
強化学習の安全性確保において、従来のラグランジュ法やPID法は学習の非定常性やノイズに起因する激しい振動と頻繁な制約違反という課題を抱えていたが、本研究は制御工学の能動的外乱抑圧制御(ADRC)を導入することで、学習中の不確実性を一括外乱としてリアルタイムに推定・相殺し、これを根本的に解決した。
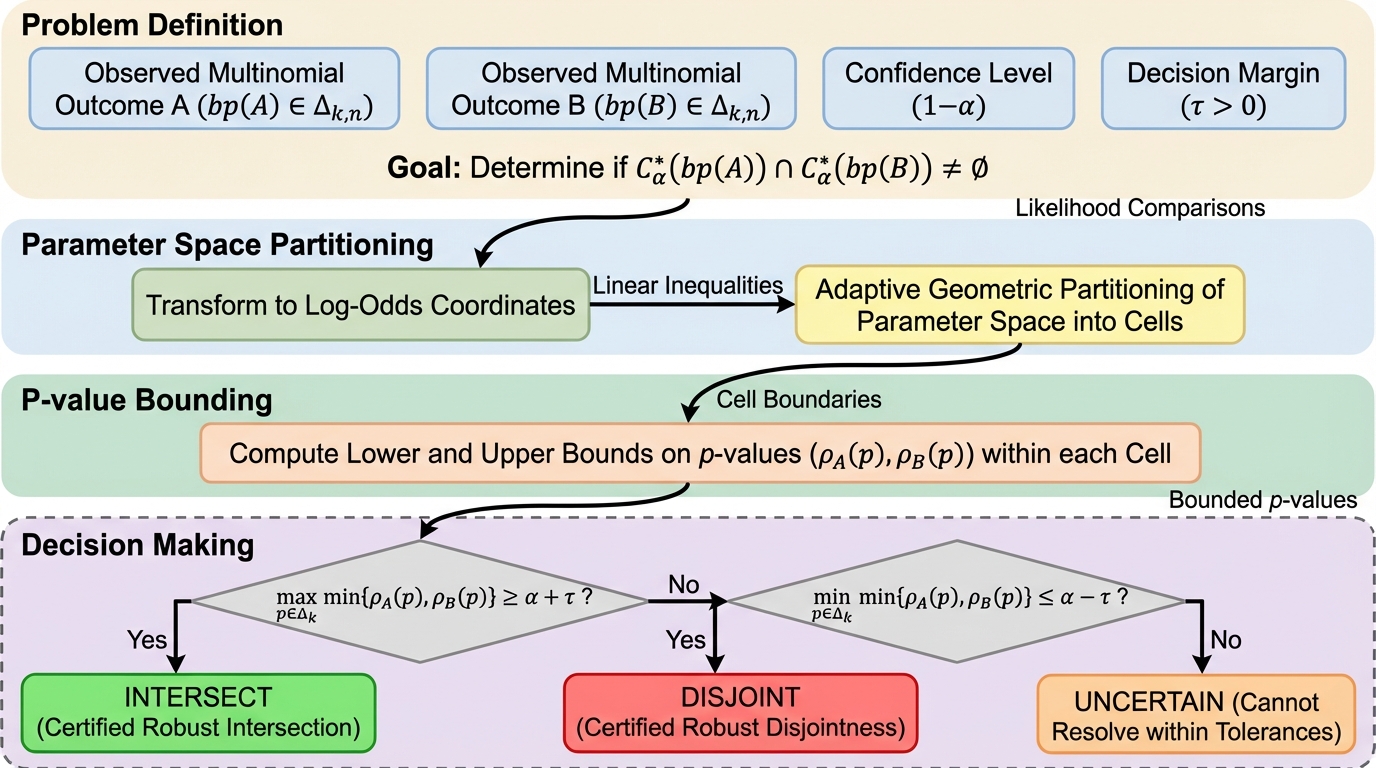
多項分布のパラメータ推定において、統計的に最適な最小体積信頼集合(MVC)は、その幾何学的形状が複雑で不連続であるため、実用的な計算が困難という課題がありました。 本研究は、対数オッズ座標系を用いることで尤度の順序関係を半空間の制約として捉え、適応的な幾何学的分割によって二つの観測結果の信頼集合が交差するかを厳密に判定するアルゴリズムを提案しました。 この手法は、従来の漸近近似では誤った結論を導きやすい小標本環境においても、交差、分離、または判定不能のいずれかを保証付きで出力し、A/Bテストや強化学習の精度向上に寄与します。
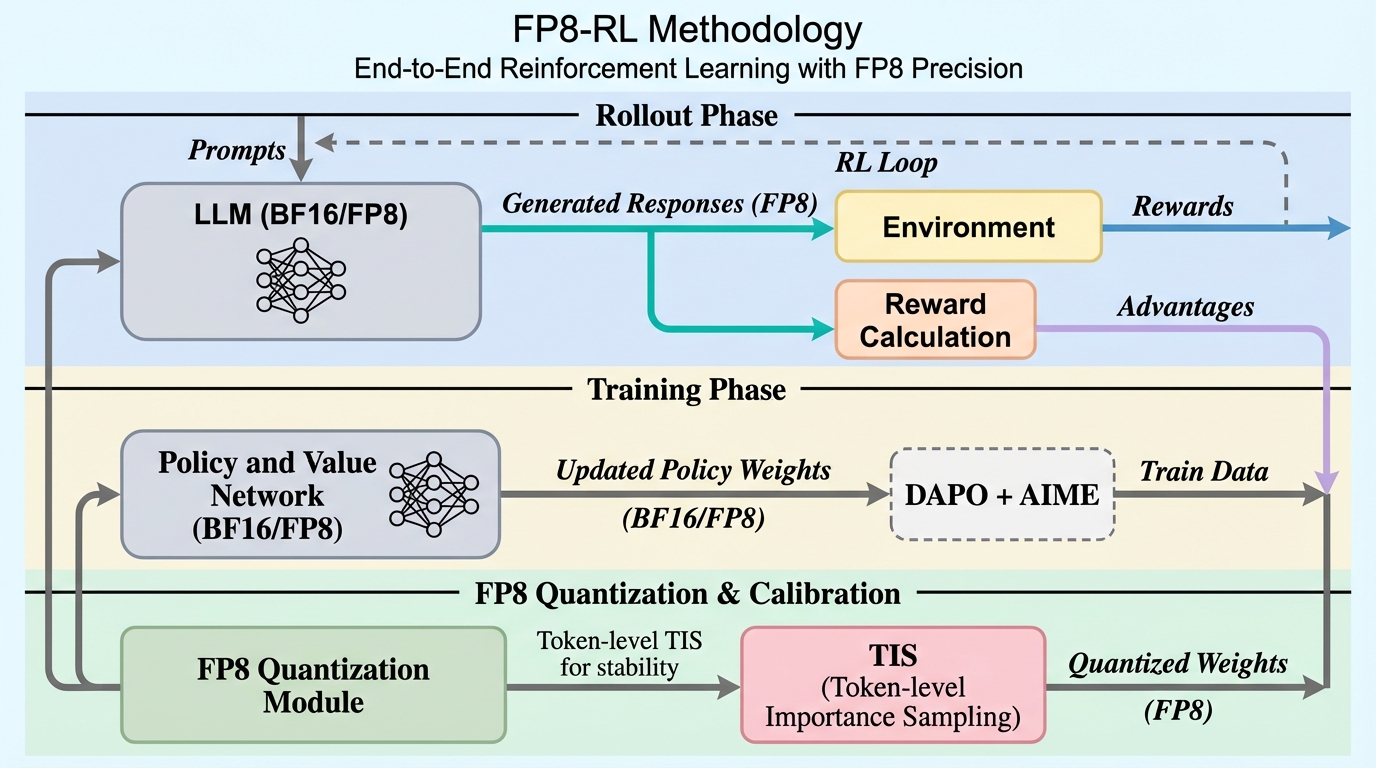
大規模言語モデルの強化学習において、実行時間の約8割を占めるロールアウト(生成)フェーズのボトルネックを解消するため、FP8精度を全面的に活用した計算スタック「FP8-RL」を提案しました。 ステップごとに更新されるポリシー重みの動的な量子化同期、KVキャッシュのFP8化、および重要度サンプリング(TIS/MIS)による不一致補正を導入することで、低精度化に伴う学習の不安定性を克服しています。 高密度モデルと混合専門家(MoE)モデルの両方で検証を行い、BF16と同等の学習性能を維持しながらロールアウトのスループットを最大44%向上させ、長文脈生成における計算効率を大幅に改善することに成功しました。
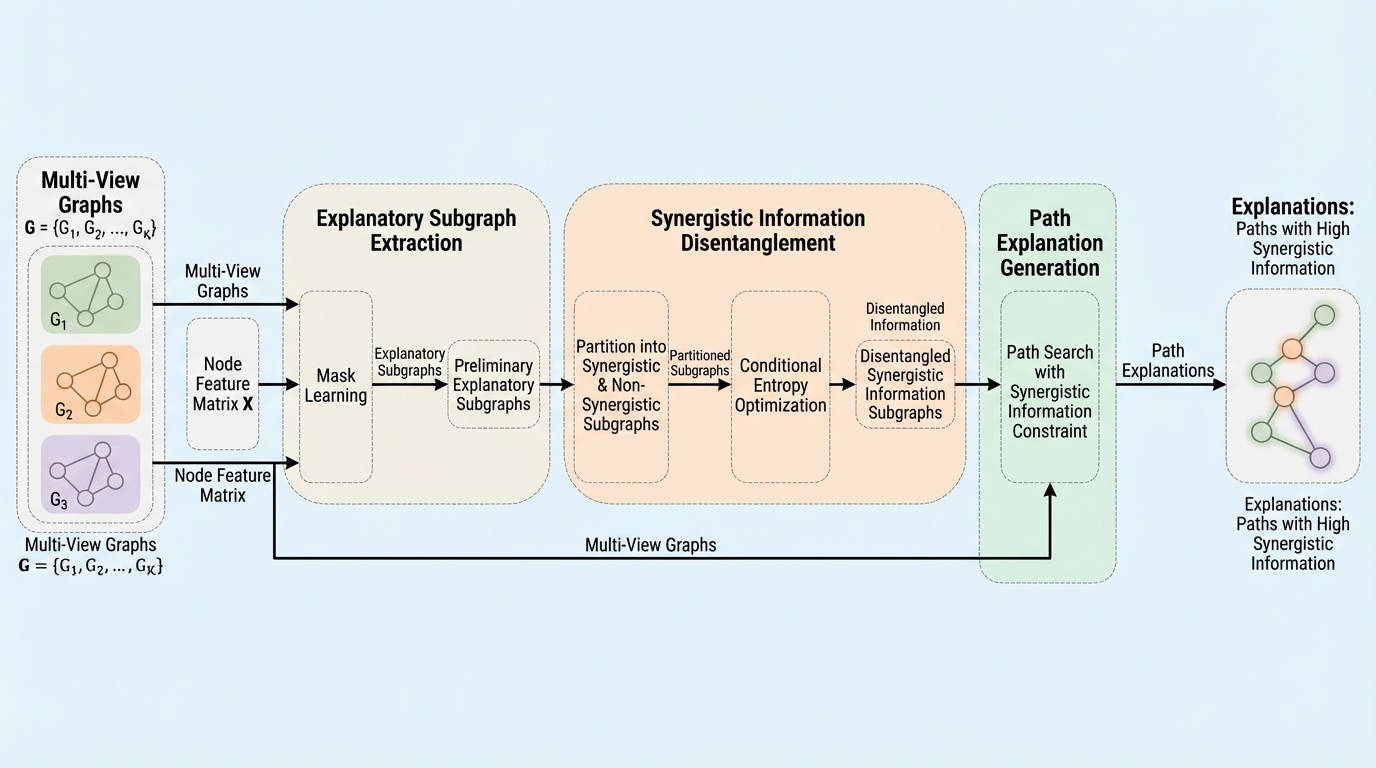
ソーシャルレコメンデーションにおいて、複数のネットワーク間に生じる相乗効果は、推薦精度を向上させる重要な要素でありながら、その非線形性と不透明さゆえに「なぜその推薦がなされたか」という根拠をユーザーが理解することを妨げるブラックボックスとなっていました。
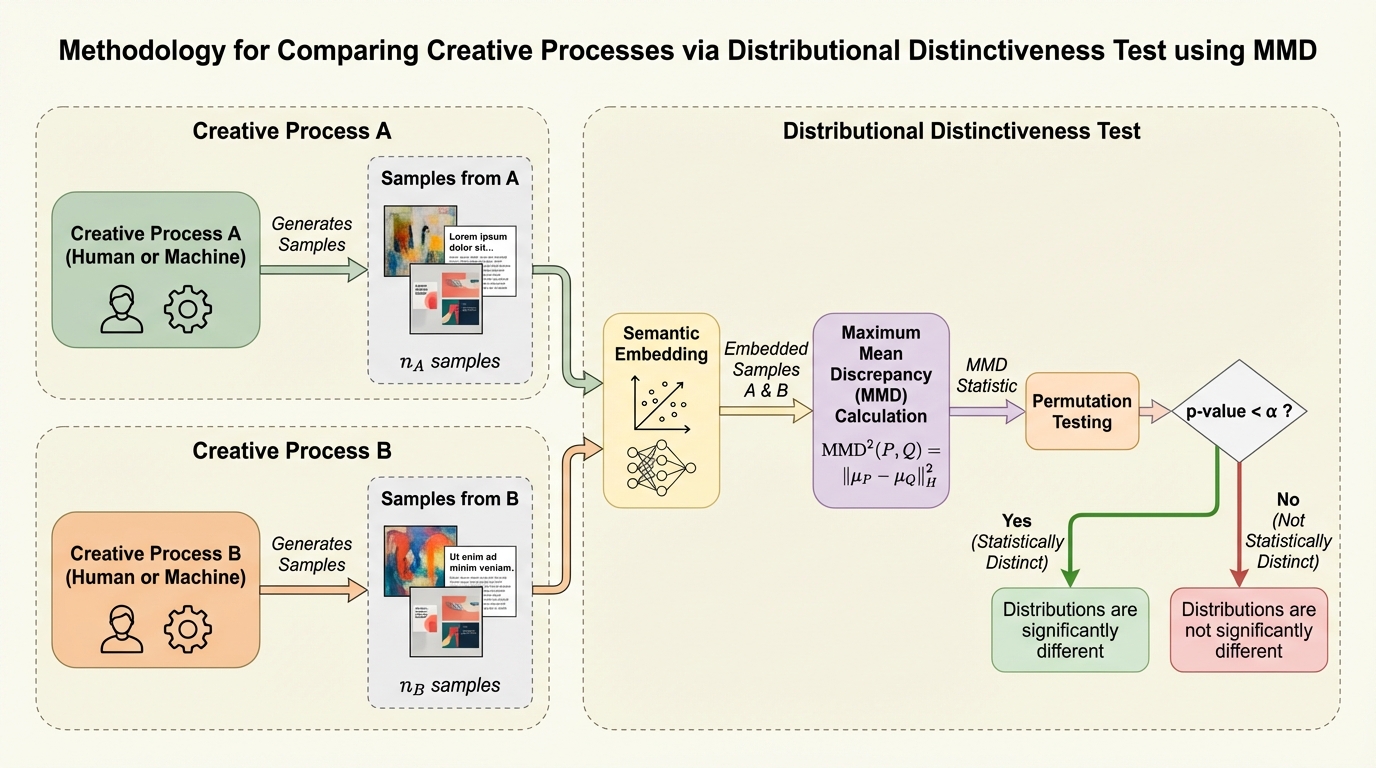
知的財産法における新規性や独創性の判断は、従来は個別の作品同士を比較する手法に頼ってきましたが、無限の出力を生成するAIモデルに対しては、個別の比較だけでは不十分であり、生成プロセス全体の分布を評価する新しい統計的手法が必要です。
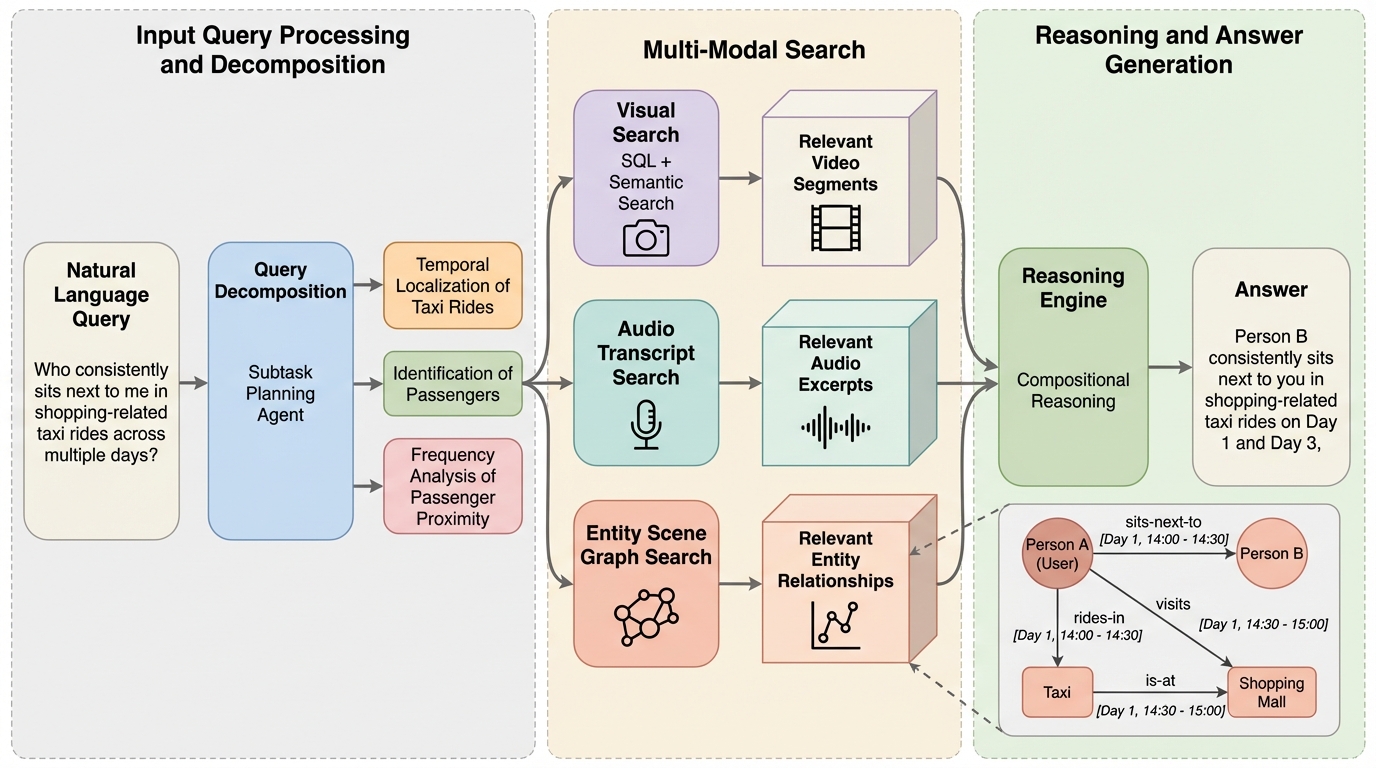
スマートグラス等のウェアラブルデバイスが記録する数日間にわたる膨大な一人称視点動画を理解するため、人物・物体・場所とその関係性を時間情報と共に構造化した「エンティティ・シーングラフ(ESG)」を活用する新フレームワーク「EGAgent」が提案されました。