エージェントによる超長時間動画理解
スマートグラス等のウェアラブルデバイスが記録する数日間にわたる膨大な一人称視点動画を理解するため、人物・物体・場所とその関係性を時間情報と共に構造化した「エンティティ・シーングラフ(ESG)」を活用する新フレームワーク「EGAgent」が提案されました。
TL;DR(結論)
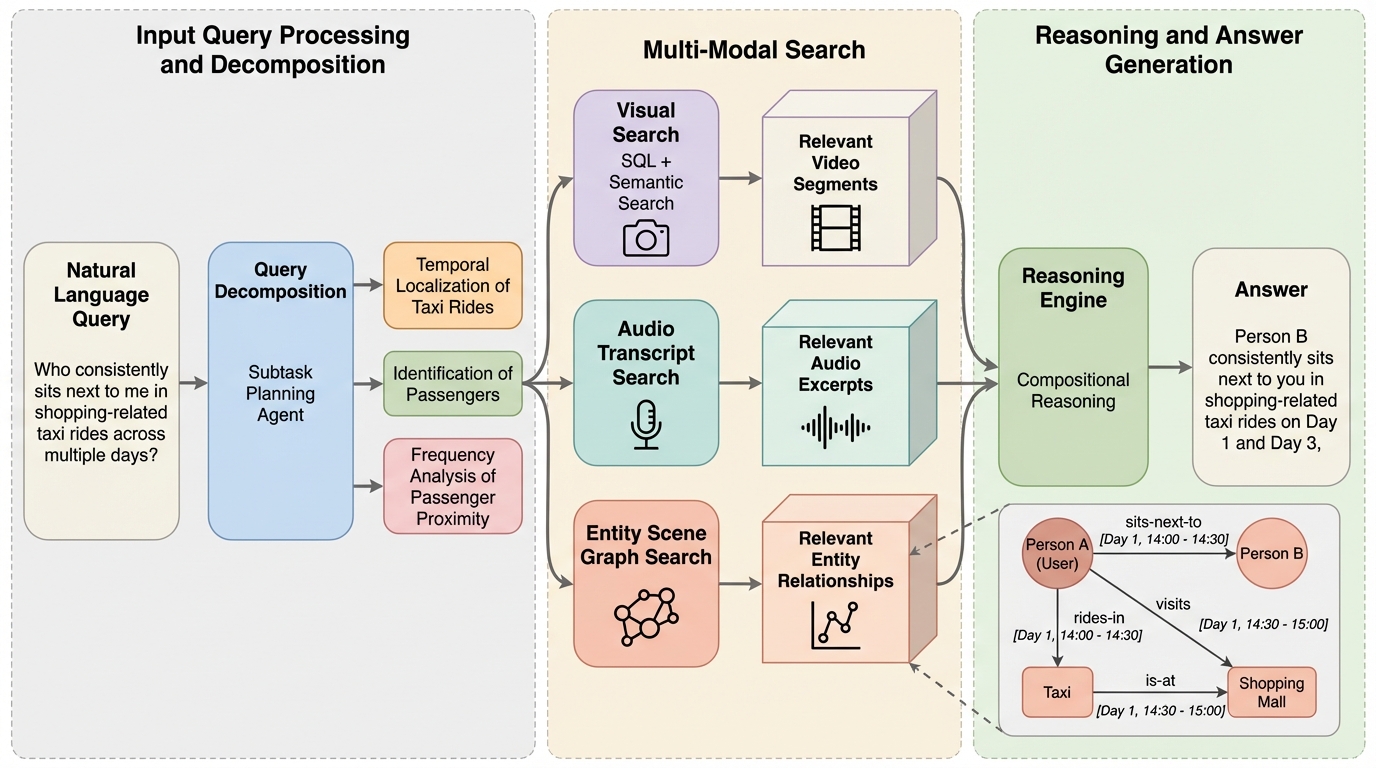
スマートグラス等のウェアラブルデバイスが記録する数日間にわたる膨大な一人称視点動画を理解するため、人物・物体・場所とその関係性を時間情報と共に構造化した「エンティティ・シーングラフ(ESG)」を活用する新フレームワーク「EGAgent」が提案されました。 プランニングエージェントがSQL検索や視覚・音声検索ツールを駆使して複雑な問いをサブタスクに分解・実行することで、従来の言語モデルや検索拡張生成(RAG)では困難だった多段階の論理推論や、数日を跨ぐ長期的な文脈の把握を可能にしています。 50時間に及ぶ動画データセット「EgoLifeQA」を用いた検証では、従来手法を20.6%上回る57.5%の精度を達成し、特に人間関係の把握(RelationMap)や複雑なタスクの理解(TaskMaster)において劇的な性能向上を実現し、計算効率も大幅に改善しました。
なぜこの問題か
現代のAI技術において、スマートグラスのような常にオン状態にあるウェアラブルデバイスの普及は、AIアシスタントに新しいレベルの文脈理解を要求しています。これまでのAIは、数秒から数分程度の独立した短いイベントを処理することには長けていましたが、ユーザーの日常生活を数日間、あるいは数週間にわたって連続的に記録した「一人称視点のロング動画(Longitudinal Video)」を解釈し、記憶することは極めて困難でした。従来の動画理解ベンチマークであるMSR-VTTやDiDeMoでは、動画の長さはせいぜい1分程度であり、最近の進展でも数分から1時間程度が限界とされてきました。しかし、現実の生活をサポートするAIには、50時間を超えるような「超長時間」の地平が必要となります。 既存の大型言語モデル(LLM)は、一度に処理できる情報の量、いわゆるコンテキストウィンドウに物理的な制約があるため、これほど膨大なデータを直接読み込むことはできません。…
核心:何を提案したのか
本研究の核心は、超長時間動画の内容を「エンティティ・シーングラフ(Entity Scene Graph, ESG)」という構造化された形式で表現し、それを自律的なエージェントが操作する新しいフレームワーク「EGAgent」を開発した点にあります。このエンティティ・シーングラフは、動画内に登場する人物、場所、物体を「ノード(点)」とし、それらの間の相互作用(例:話す、使用する、相互作用する、言及する)を「エッジ(線)」で結んだネットワーク構造を持っています。このグラフの最大の特徴は、各エッジに対してその関係が成立していた具体的な「時間間隔」が注釈として付与されていることです。これにより、システムは単なる情報の断片を保持するのではなく、時間の流れに沿った構造的な知識ベースを持つことが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related