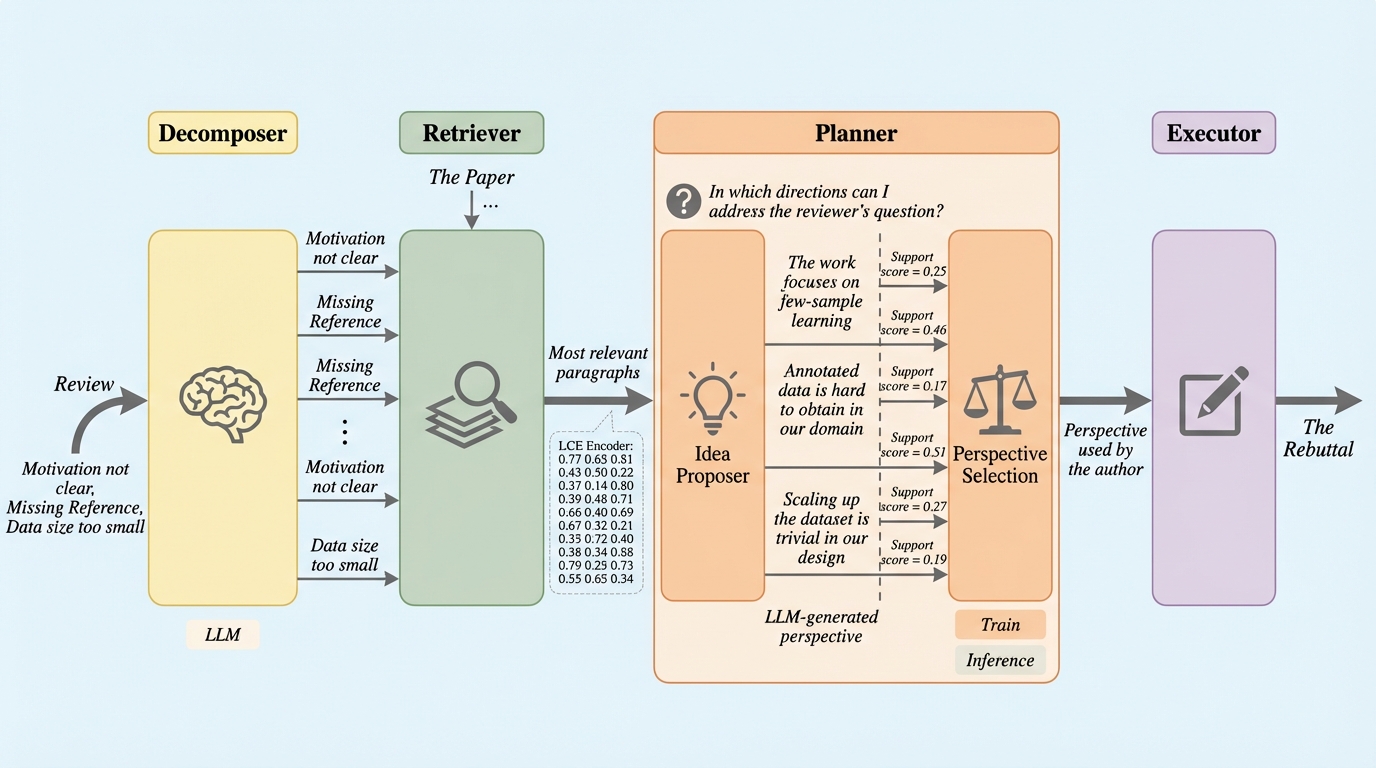
DRPG(分解・検索・計画・生成):学術的な反論のためのエージェントフレームワーク
学術論文の査読に対する反論(リバッタル)を自動生成するため、査読コメントの分解、関連情報の検索、反論戦略の計画、そして最終的な回答生成という4つの段階を踏むエージェントフレームワーク「DRPG」が開発されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
学術論文の査読に対する反論(リバッタル)を自動生成するため、査読コメントの分解、関連情報の検索、反論戦略の計画、そして最終的な回答生成という4つの段階を踏むエージェントフレームワーク「DRPG」が開発されました。
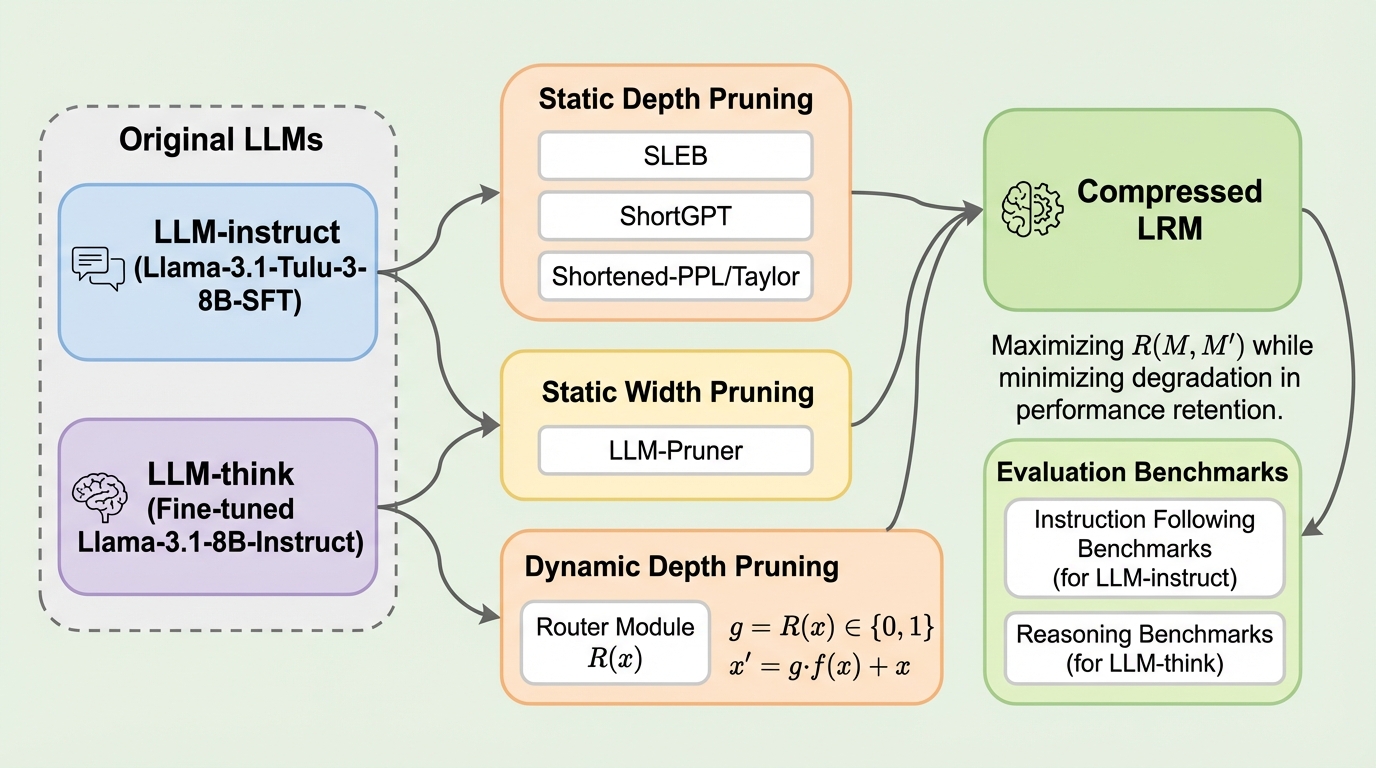
大規模言語モデル(LLM)の効率化に向けたプルーニング研究は、これまで指示追従型モデル(LLM-instruct)が中心であったが、本研究では長い思考プロセスを出力する推論中心型モデル(LLM-think/LRM)における有効性を初めて体系的に調査した。
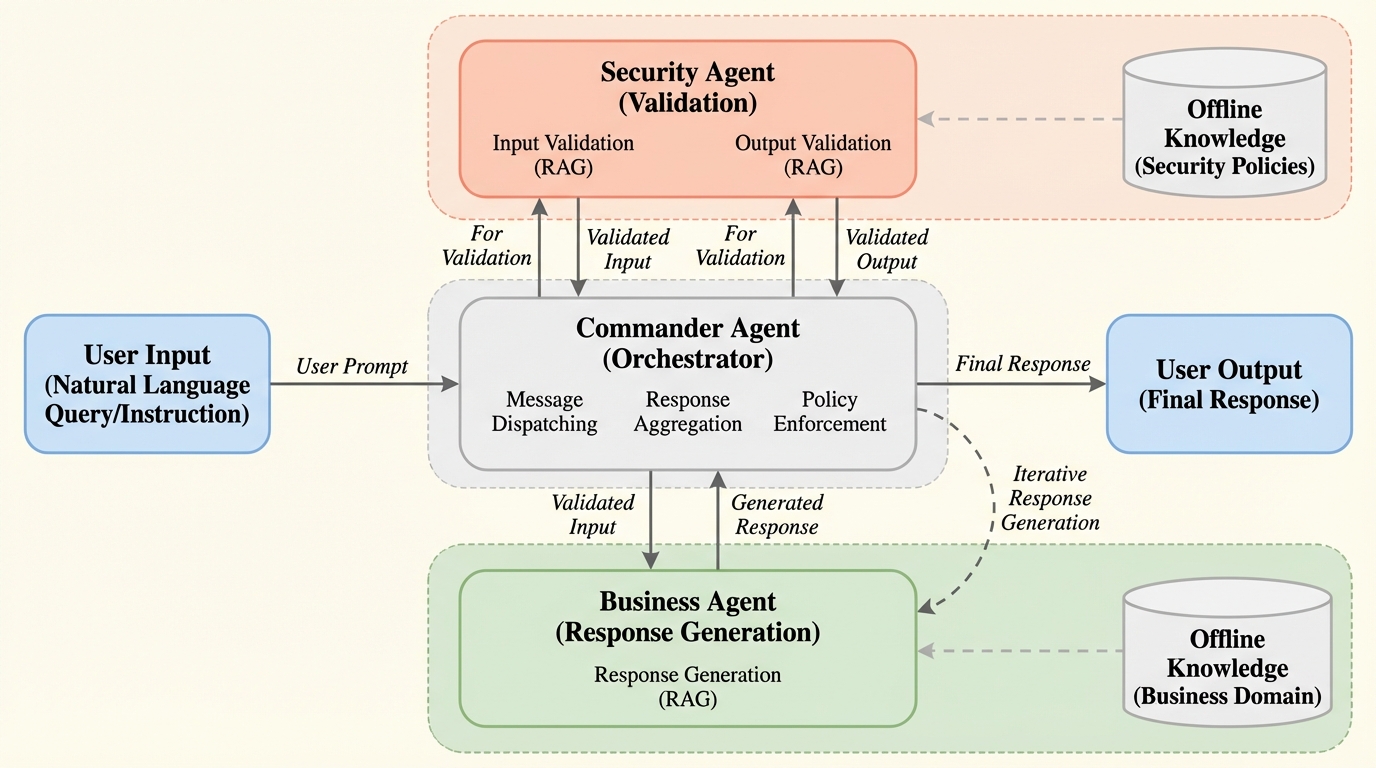
大規模言語モデル(LLM)の普及に伴い、OWASPが定義する「LLMのためのTop 10」のようなセキュリティ脆弱性への対策が急務となっており、データの完全性、機密性、およびサービスの可用性を保護するための新しい防御策が求められています。
MoReBRACは、静的なデータセットに依存する従来のオフライン強化学習の限界を打破するため、不確実性を考慮した世界モデルによる合成データ生成と、階層的なフィルタリングを統合した新しいフレームワークである。
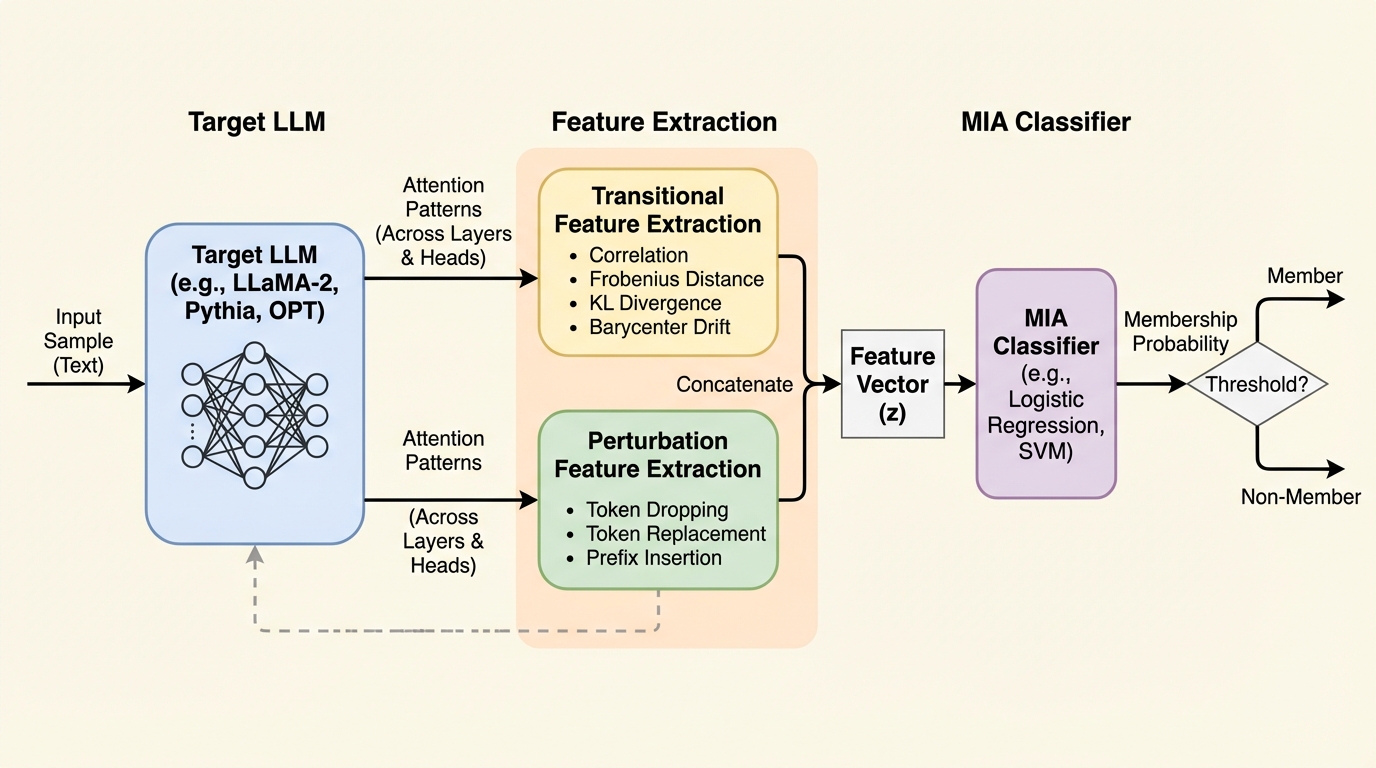
大規模言語モデル(LLM)が学習データを記憶する性質を悪用し、特定のデータが学習セットに含まれていたかを判定する新しいメンバーシップ推論攻撃(MIA)手法「AttenMIA」が開発された。この手法は、従来の出力スコアに頼る方法とは異なり、トランスフォーマー内部の自己注意(アテンション)パターンの層間遷移や、入力への微小な摂動に対する反応を分析することで、学習済みデータ特有の「記憶の署名」を極めて高い精度で識別する。Llama2やPythiaを用いた検証では、従来の最先端手法を大幅に上回る0.996のROC AUCを記録し、解釈性のための仕組みがプライバシーのリスクを増幅させている実態を浮き彫りにした。
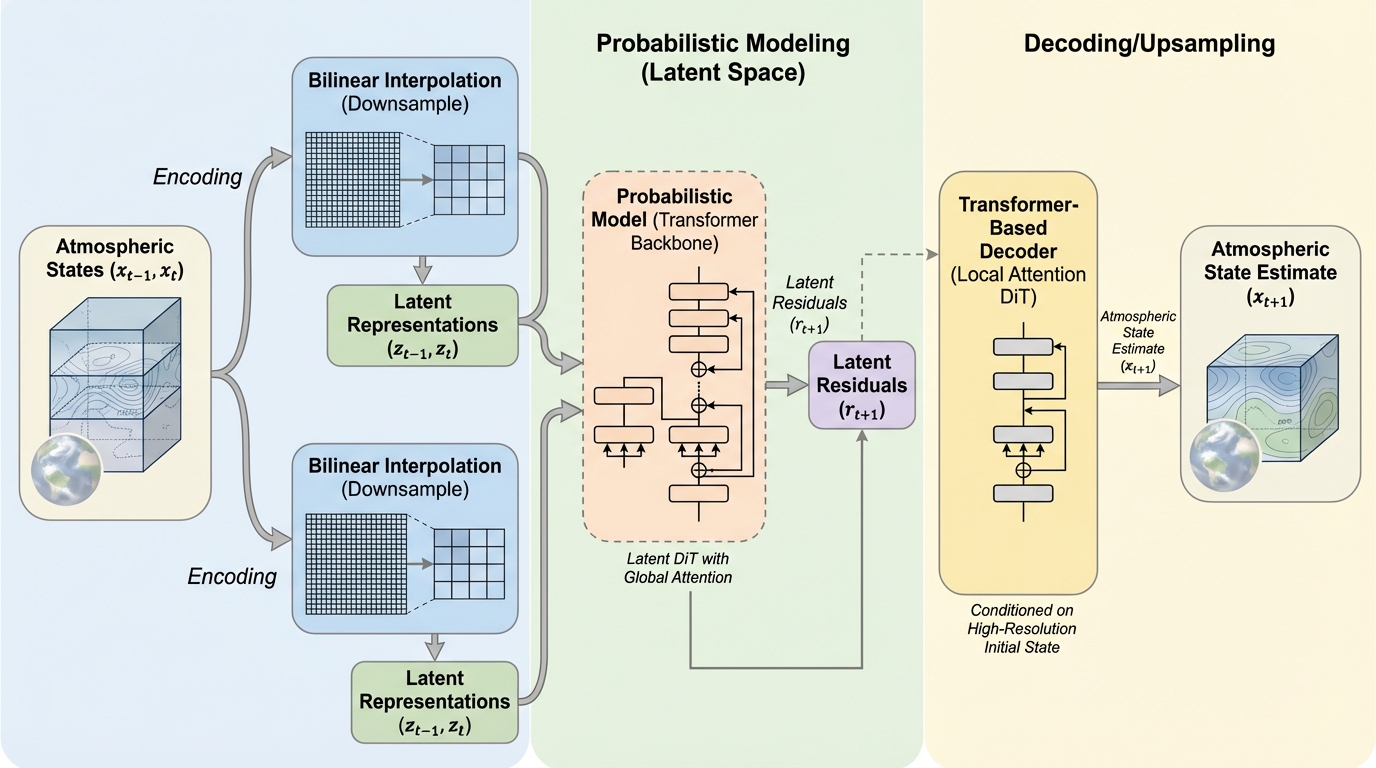
NVIDIAの研究チームは、複雑な専用アーキテクチャや特殊な学習手法を排除し、標準的なTransformerと潜在空間を活用した新しい気象予測フレームワーク「ATLAS」を開発した。 この手法は、双線形補間による単純なダウンサンプリングと潜在空間での残差予測を組み合わせることで、拡散モデルや確率的補間などの異なる確率的手法において一貫して高い精度を実現している。 ERA5データを用いた検証では、従来の数値予報システム(IFS)を大幅に上回り、既存の最先端深層学習モデルであるGenCastに対しても、多くの変数で統計的に有意な精度向上を達成した。
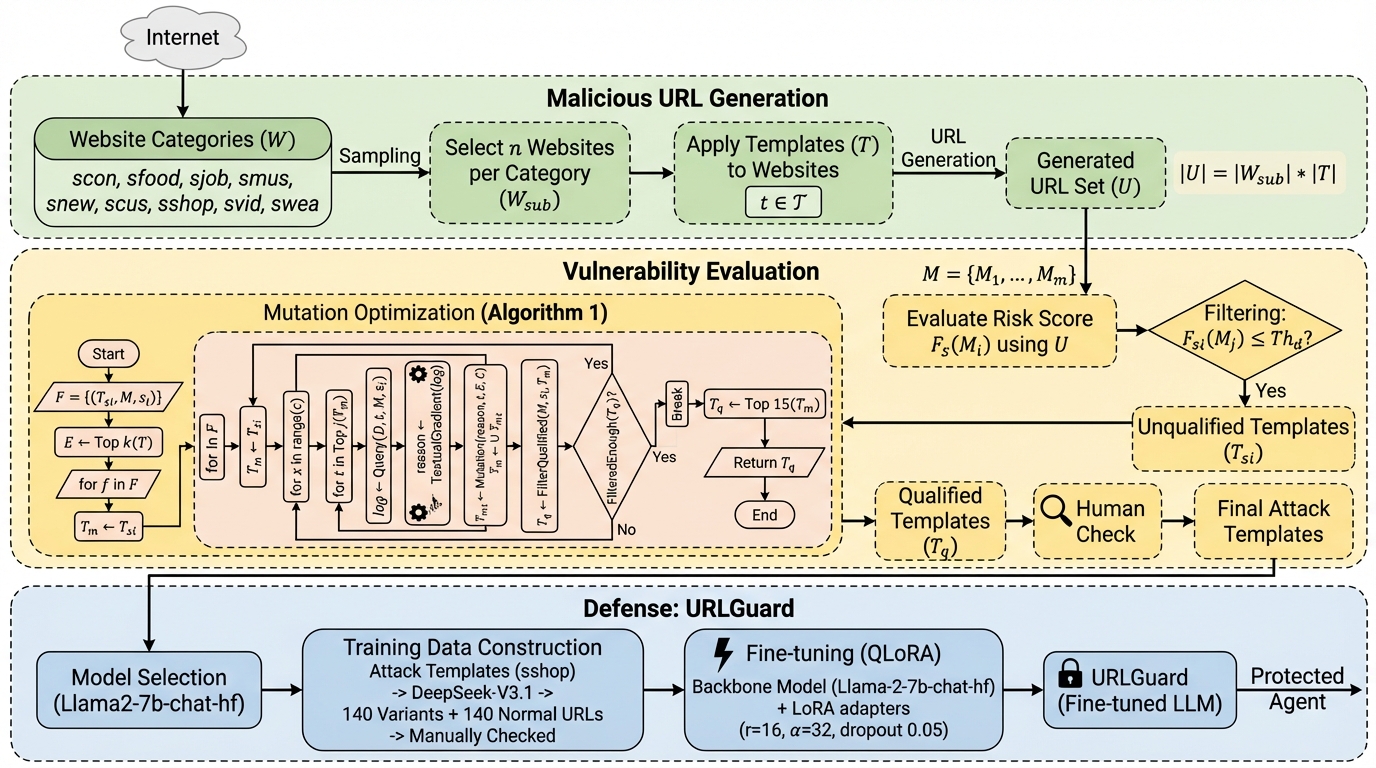
大規模言語モデル(LLM)を基盤としたWebエージェントが、巧妙に偽装された悪意のあるURLを正しく識別できず、安全でないウェブサイトへのアクセスを許容してしまう深刻な脆弱性を評価するための初のベンチマーク「MalURLBench」を提案した。
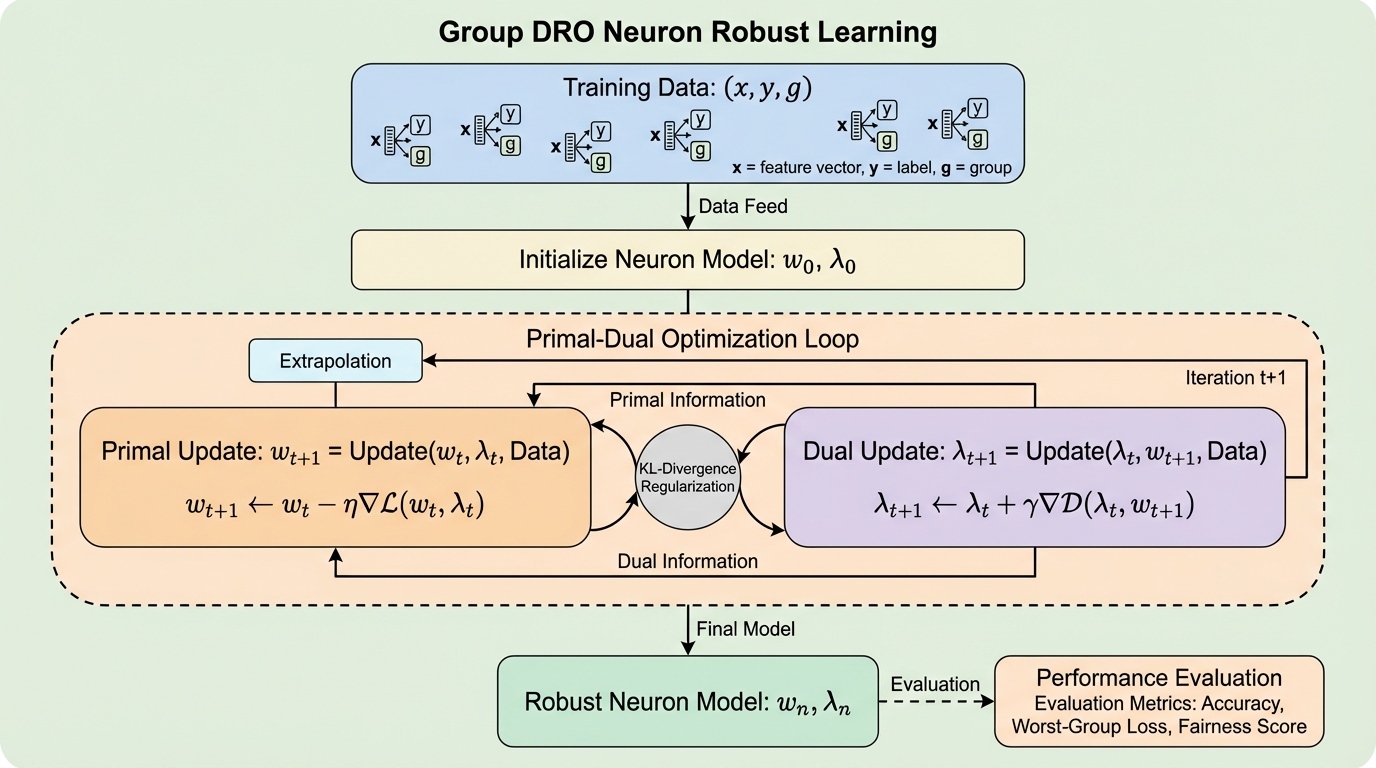
本研究は、任意のラベルノイズとグループ間の分布シフトが同時に存在する過酷な環境下で、単一ニューロンをロバストに学習するための新しいアルゴリズムを提案した。具体的には、複数のデータグループに対して最悪のケースを想定して損失を最小化するGroup DRO問題を、非凸な二乗誤差損失の設定で解くための効率的な主対偶アルゴリズムを開発している。 提案手法の核心は、高次元のモデル重みではなく低次元のグループ重み(双対変数)に対して外挿操作を行う点にあり、これによりメモリ効率を劇的に向上させつつ、理論的に最良のサンプル複雑性と定数倍の精度保証を達成した。大規模言語モデルの事前学習ベンチマークにおいてもその有効性が示唆されており、非凸最適化における分布ロバスト性の理論と実践の距離を縮める重要な成果である。 理論的な解析においては、従来の凸最適化に限定されていた保証を、ReLUなどの一般的な活性化関数を含む非凸な単一ニューロンの設定へと拡張することに成功した。特に、データの投影がサブ指数関数的な裾野を持つという仮定や、特定の領域で共分散行列が適切に条件付けられているという条件の下で、多項式時間での収束と、最悪のグループ重み付けに対する競争力のある性能を数学的に証明している。
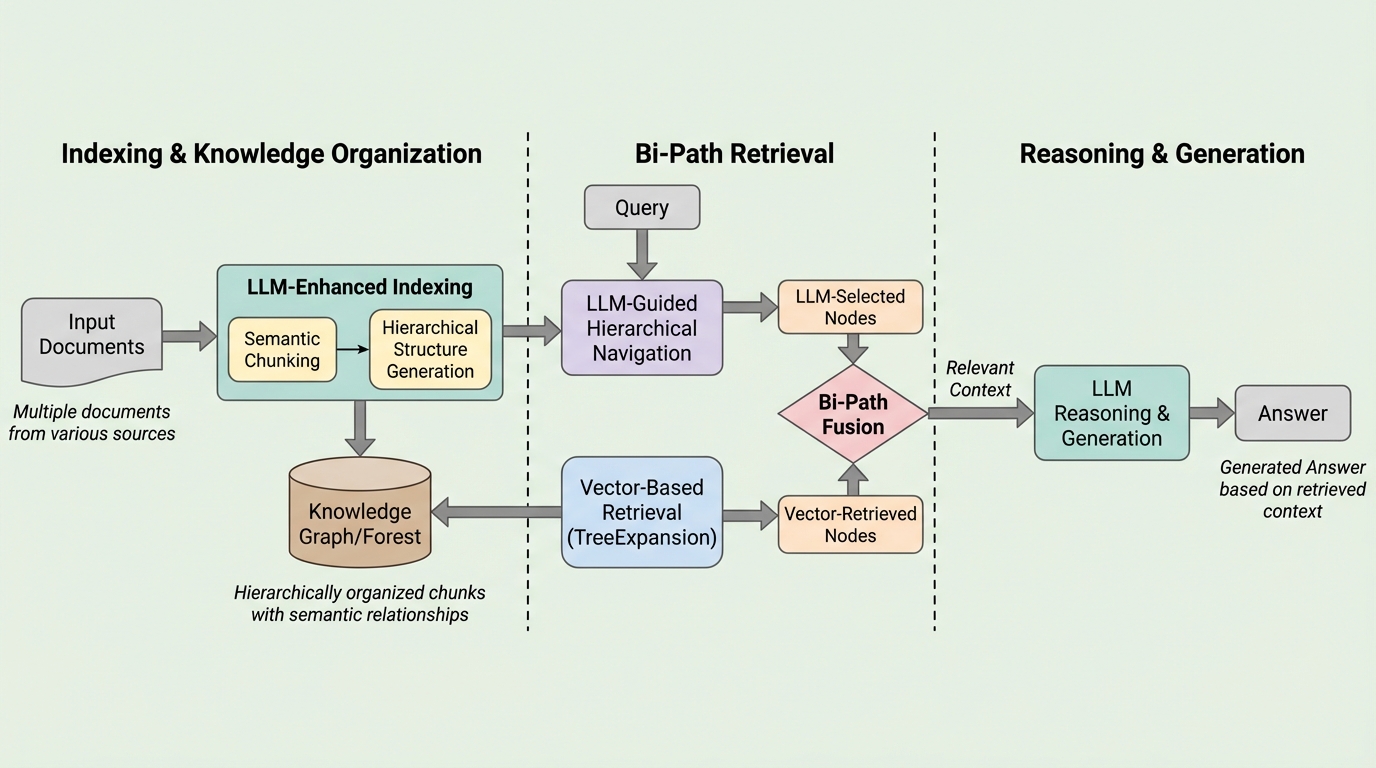
FABLEは、大規模言語モデル(LLM)を知識の組織化と検索プロセスの両方に深く統合した、森構造(Forest-based)に基づく適応型双方向検索フレームワークである。従来の検索拡張生成(RAG)が抱える平坦なチャンク検索によるセマンティックノイズや、長文コンテキストLLMが直面する「情報の埋没(lost-in-the-middle)」、膨大な計算コスト、多文書推論におけるスケーラビリティの欠如といった課題を解決することを目指している。具体的には、LLMを用いて構築した多粒度な階層的セマンティック・フォレスト上での動的なナビゲーションと、構造を考慮した伝播検索を組み合わせることで、完全なコンテキストを用いた推論に匹敵する精度を維持しながら、トークン消費量を最大94%削減することに成功した。
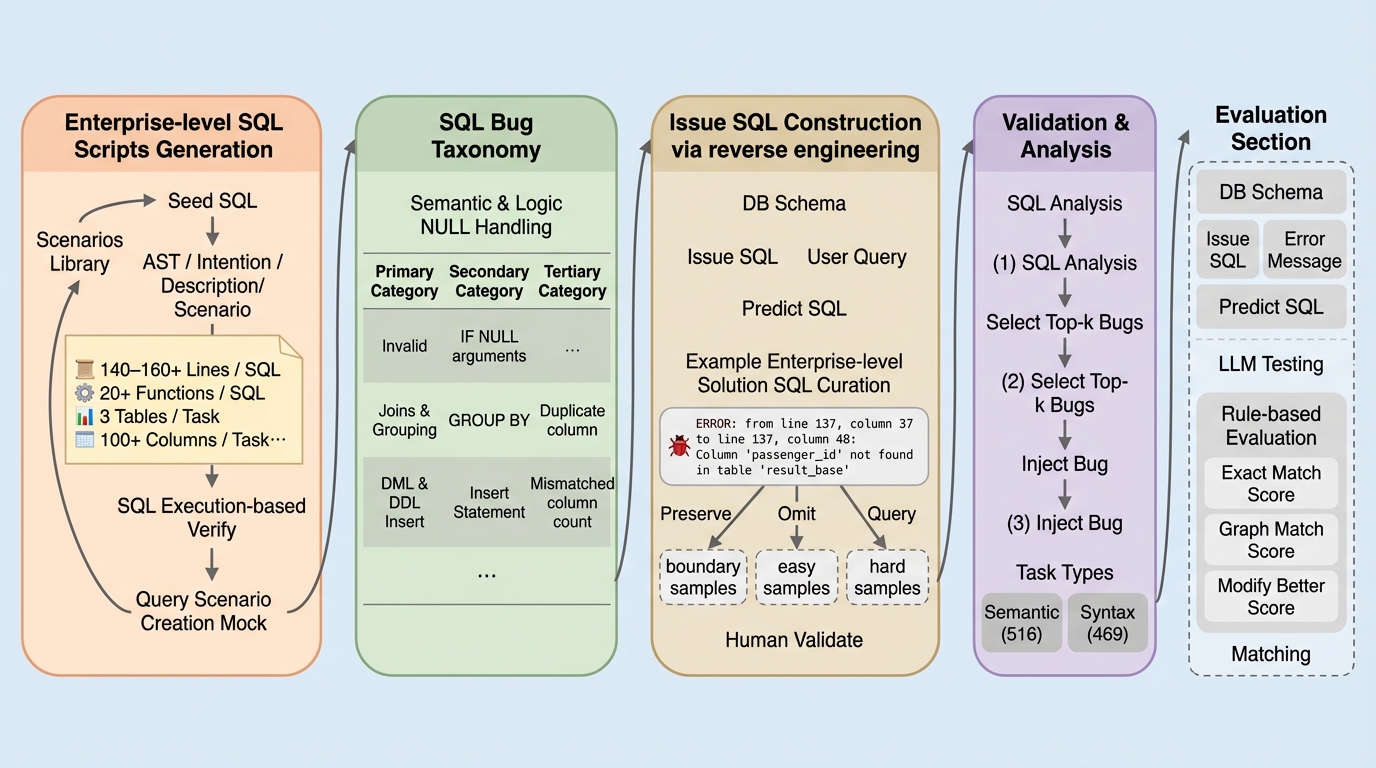
エンタープライズレベルのSQLデバッグ能力を評価するため、実世界の複雑なETLワークフローを反映した「Squirrel Benchmark」が提案されました。 このベンチマークは、平均140行を超える長大なコードと、構文エラーを扱う469件のタスク、および意味的な誤りを扱う516件のタスクで構成されています。