FABLE:多文書推論のための森構造に基づく適応型双方向LLM強化検索
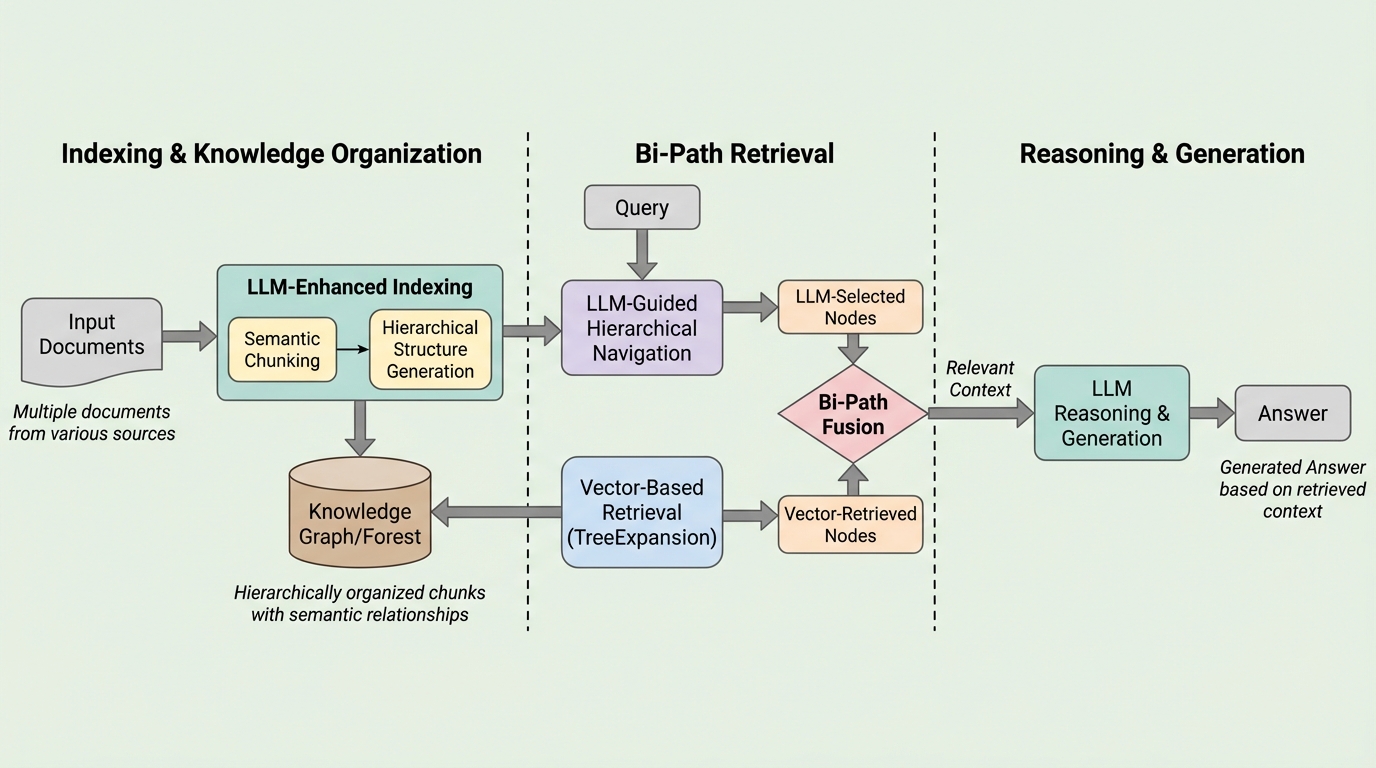
FABLEは、大規模言語モデル(LLM)を知識の組織化と検索プロセスの両方に深く統合した、森構造(Forest-based)に基づく適応型双方向検索フレームワークである。従来の検索拡張生成(RAG)が抱える平坦なチャンク検索によるセマンティックノイズや、長文コンテキストLLMが直面する「情報の埋没(lost-in-the-middle)」、膨大な計算コスト、多文書推論におけるスケーラビリティの欠如といった課題を解決することを目指している。具体的には、LLMを用いて構築した多粒度な階層的セマンティック・フォレスト上での動的なナビゲーションと、構造を考慮した伝播検索を組み合わせることで、完全なコンテキストを用いた推論に匹敵する精度を維持しながら、トークン消費量を最大94%削減することに成功した。
TL;DR(結論)
FABLEは、大規模言語モデル(LLM)を知識の組織化と検索プロセスの両方に深く統合した、森構造(Forest-based)に基づく適応型双方向検索フレームワークである。従来の検索拡張生成(RAG)が抱える平坦なチャンク検索によるセマンティックノイズや、長文コンテキストLLMが直面する「情報の埋没(lost-in-the-middle)」、膨大な計算コスト、多文書推論におけるスケーラビリティの欠如といった課題を解決することを目指している。具体的には、LLMを用いて構築した多粒度な階層的セマンティック・フォレスト上での動的なナビゲーションと、構造を考慮した伝播検索を組み合わせることで、完全なコンテキストを用いた推論に匹敵する精度を維持しながら、トークン消費量を最大94%削減することに成功した。
なぜこの問題か
近年、LLMのコンテキストウィンドウが飛躍的に拡大したことで、RAGはもはや不要になるのではないかという議論が巻き起こっている。しかし、実際の調査によれば、長文コンテキストの推論には依然として深刻な限界が存在する。第一に、関連情報が長い入力の中間に位置する場合にモデルがそれを見落とす「lost-in-the-middle」現象が確認されており、情報の配置によって性能が大きく左右される。第二に、アテンション・メカニズムの計算量は入力長の二乗で増加するため、大規模な文書群をそのまま処理することはコスト面で極めて高価であり、実用的な展開を困難にしている。第三に、数百もの文書にまたがる情報を統合する必要がある場合、現在のLLMの容量では不十分である。 一方で、従来のRAGシステムはスケーラビリティには優れているものの、平坦なチャンク単位の検索に依存しているという欠点がある。これは、クエリと表面的な意味の類似性があるだけの無関係なパッセージを抽出してしまう「セマンティックノイズ」を引き起こし、深い回答の関連性を捉えきれないことが多い。…
核心:何を提案したのか
本論文が提案する「FABLE(Forest-Based Adaptive Bi-Path LLM-Enhanced Retrieval)」は、検索と推論の関係を根本から再考した統一フレームワークである。検索を単なる「抽出」の段階として扱うのではなく、LLMが構築したセマンティックな階層構造の上で、クエリの要求に応じて動的にナビゲーションを行うプロセスとして定義している。FABLEの核心的な洞察は二点に集約される。第一に、LLMは単に検索された情報を消費するだけでなく、インデックス作成時に多粒度な意味的階層構造を能動的に構築すべきであるということ。第二に、検索は一律のロジックに従うのではなく、クエリの特性に基づいて異なる探索戦略を適応的に採用すべきであるということである。 FABLEは、このビジョンを三つの主要な革新によって実現している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related