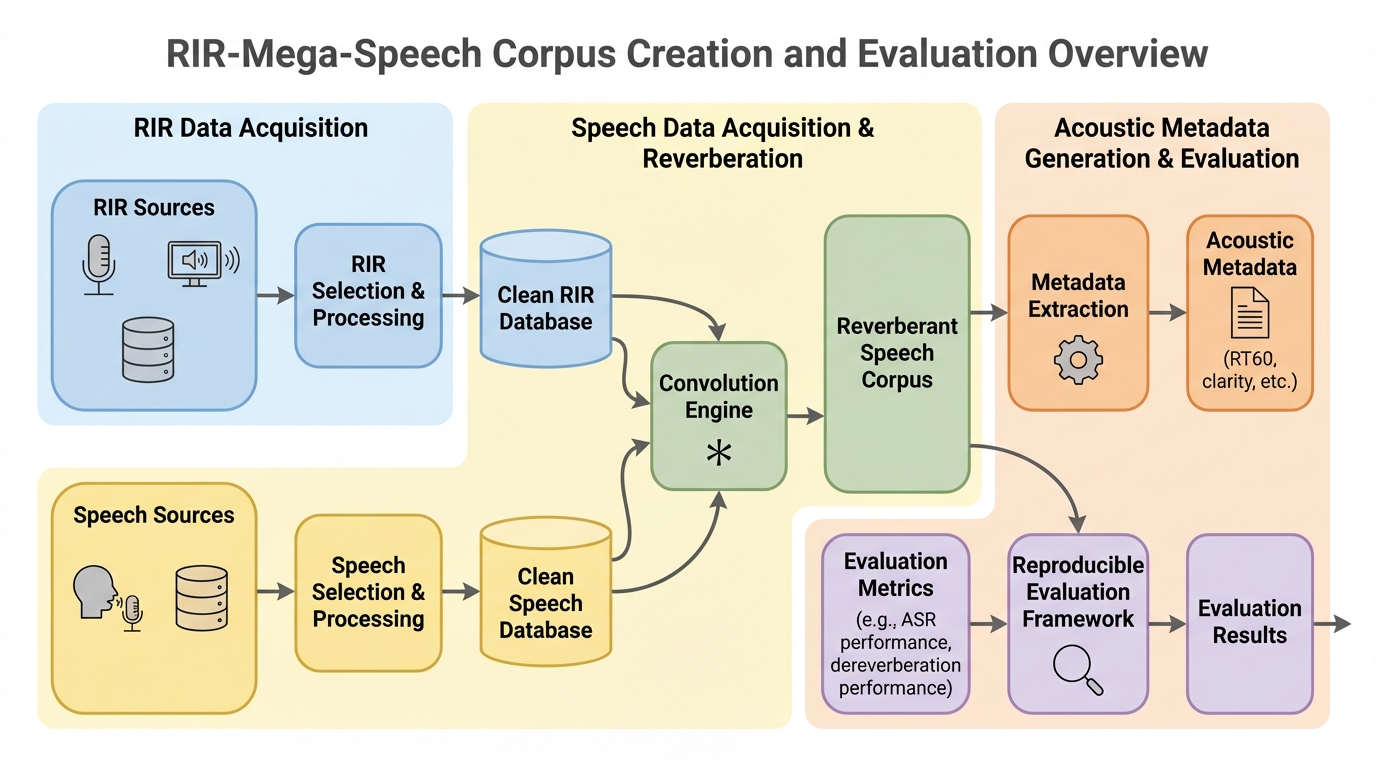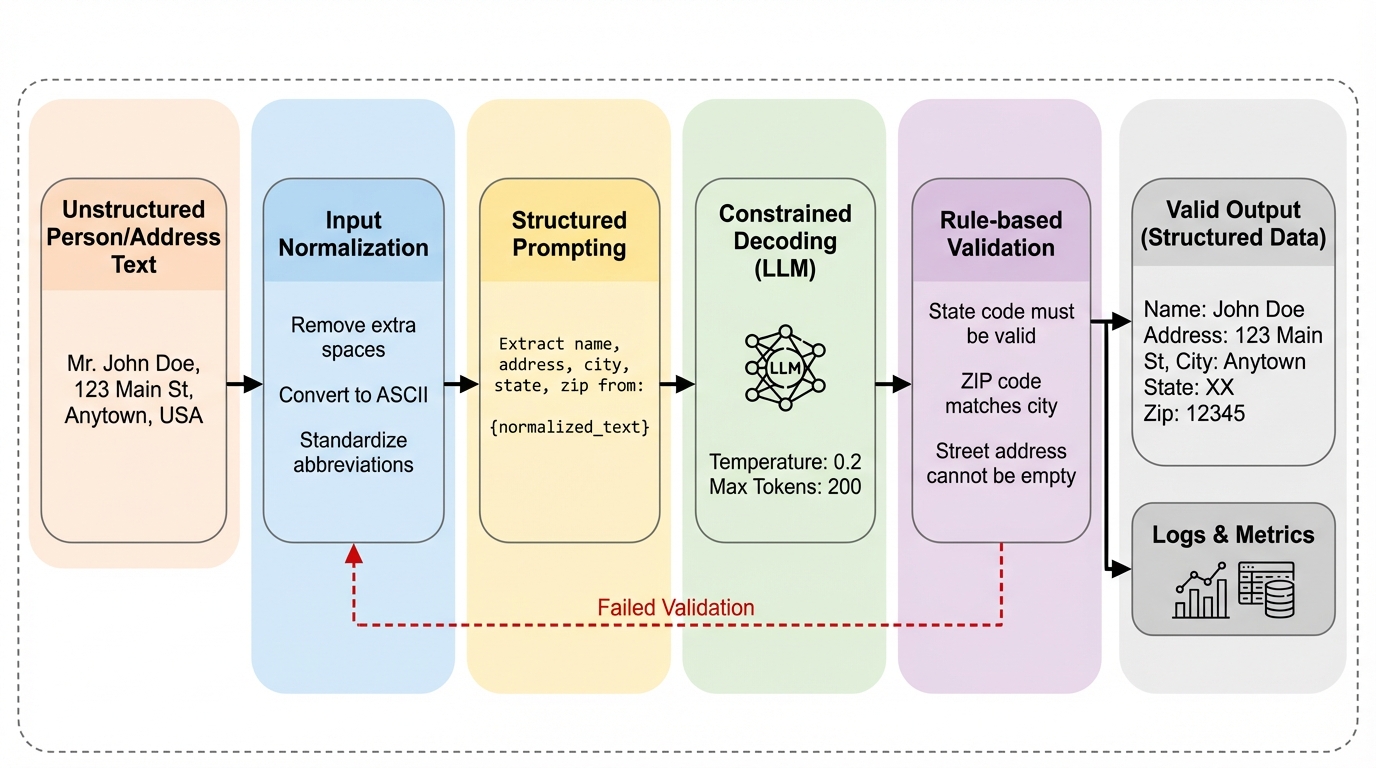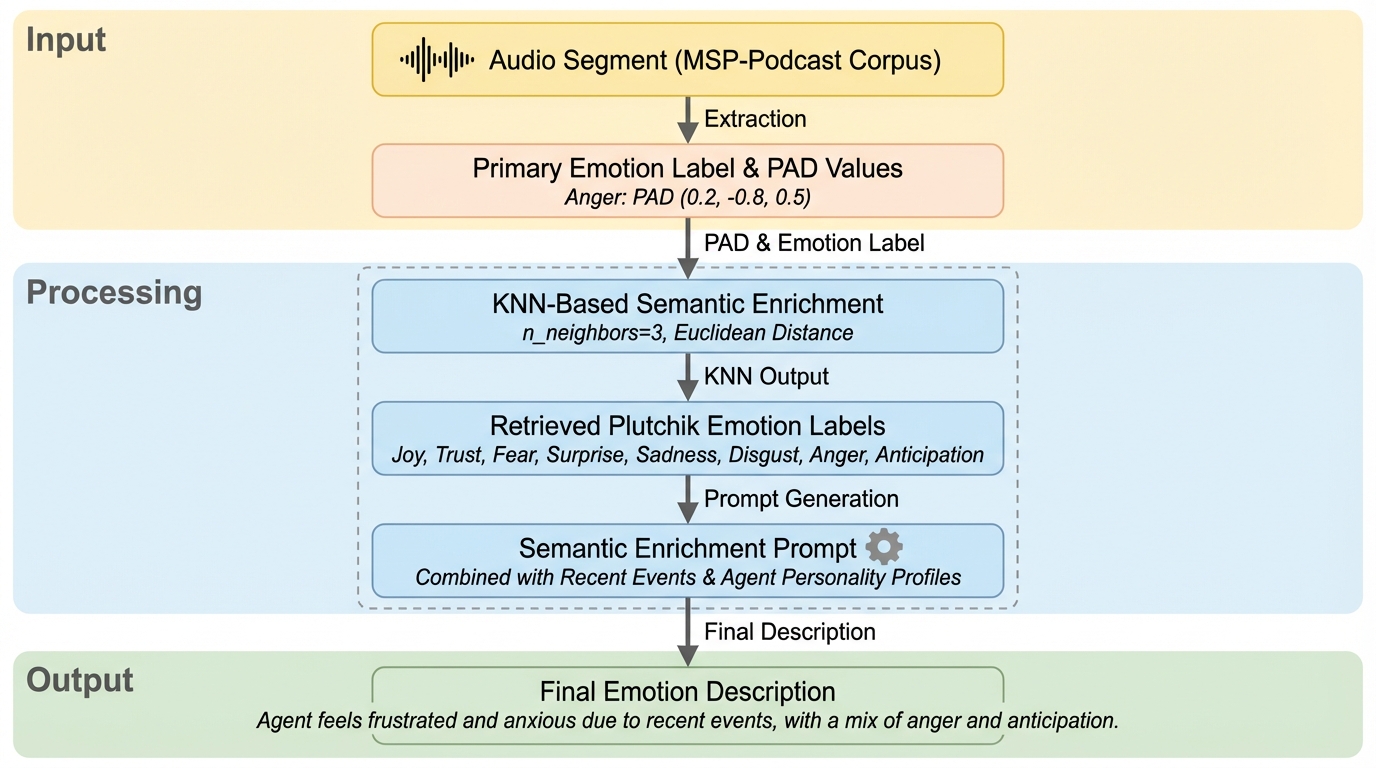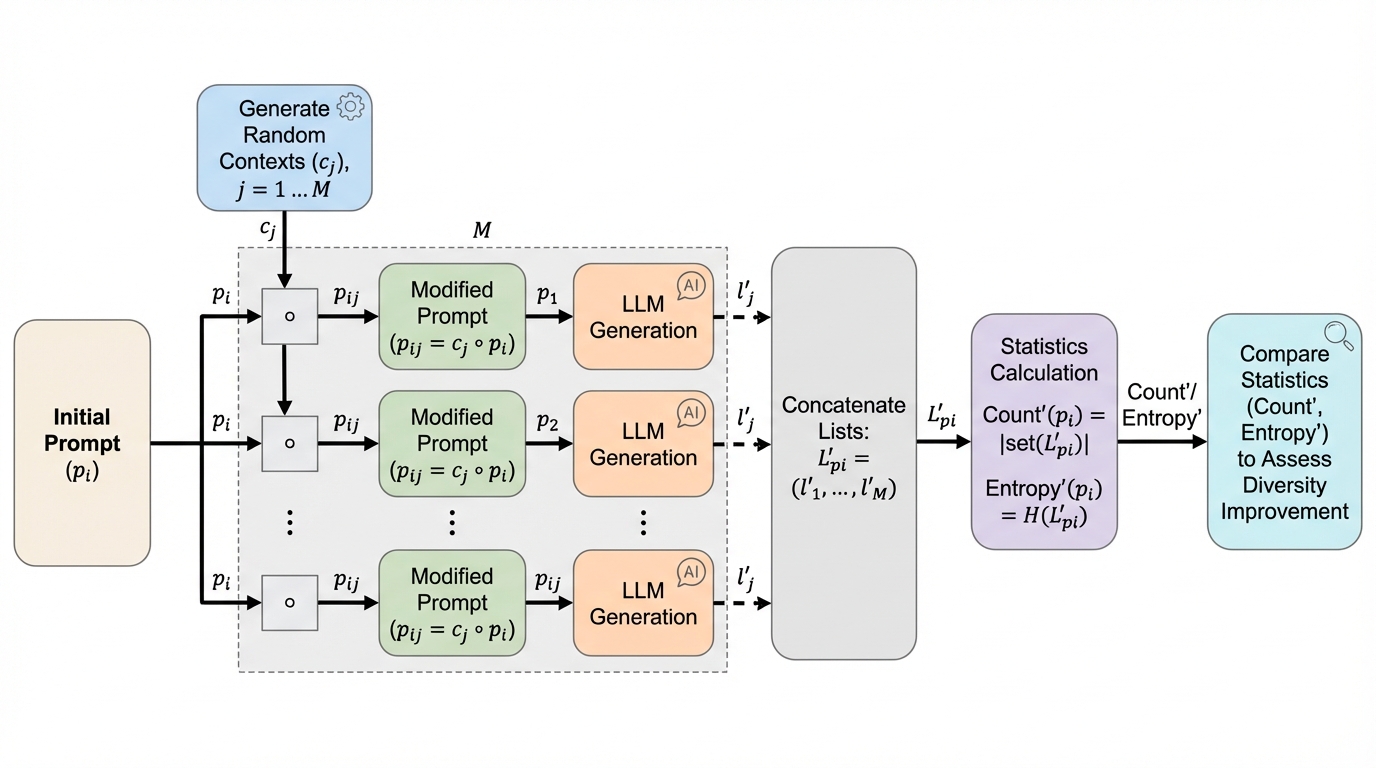
給与システムのための大規模言語モデルにおける意味論的および構文論的理解の評価
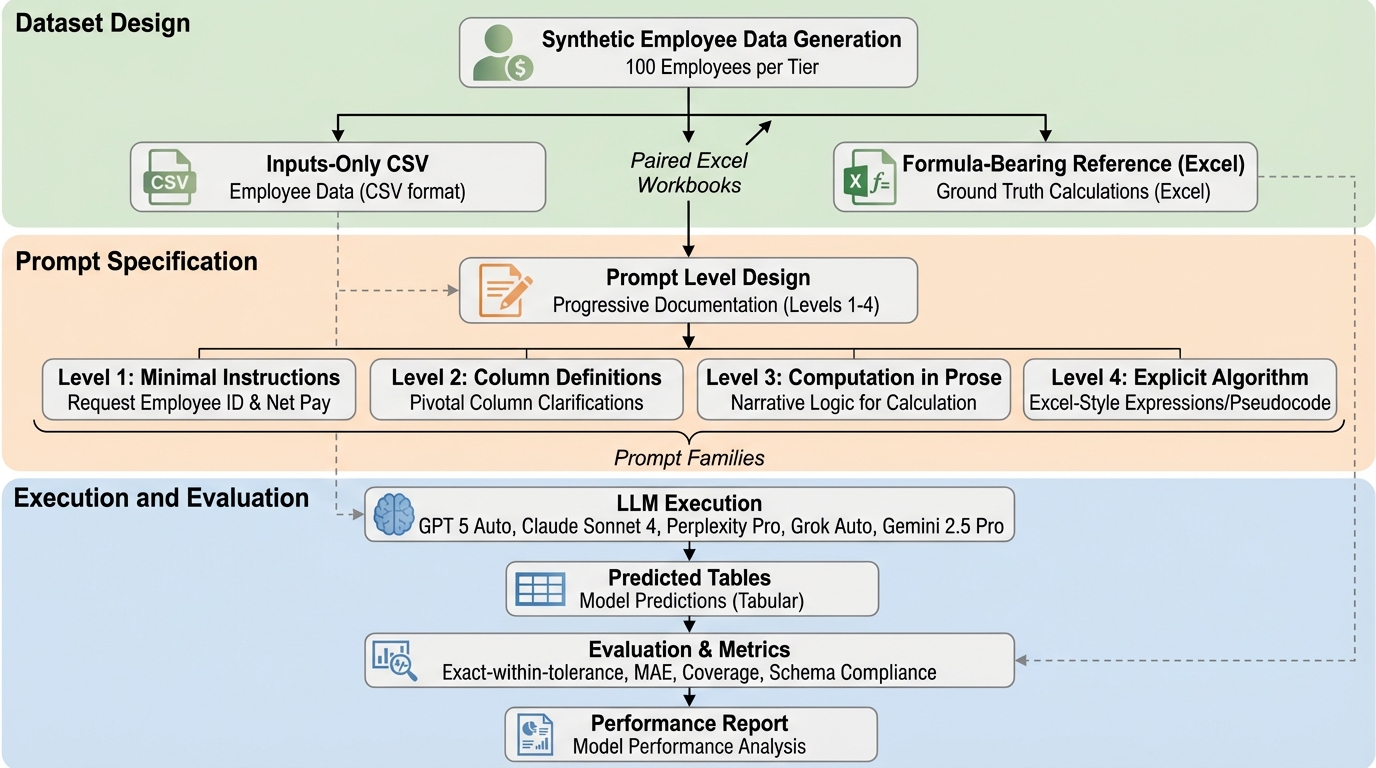
給与計算は、わずか数セントの誤差が法令遵守に影響を与えるため、大規模言語モデル(LLM)にとって極めて高い精度と監査可能性が求められる過酷なテストケースとなります。現在のLLMは文章作成や分析において優れた能力を示していますが、厳密な数値計算や、複雑なビジネスルールを正しい順序で適用する能力については依然として不確実性が残っており、本研究ではその限界と可能性を検証しました。 研究では、GPT 5 Auto、Claude Sonnet 4、Perplexity Pro、Grok Auto、Gemini 2.5 Proといった主要なモデルを対象に、5段階の難易度を持つデータセットと4段階のプロンプト手法を用いて、給与計算スキーマの意味理解と計算精度を評価しました。検証の結果、単純な計算では多くのモデルが100%の精度を達成したものの、複雑なシナリオではプロンプトの詳細度が精度に大きく影響し、特に明示的な数式を提供したレベル4においてPerplexity Proが最も高い信頼性を示しました。 実験データによれば、単純な乗算を超えた複雑なタスクにおいて、LLMが単独で正確な結果を出すには限界があり、明示的なアルゴリズムの提示や外部ツールの活用が不可欠であることが明らかになりました。特に、多州にまたがる税金の按分や為替変換を含む高度なシナリオでは、モデル間で性能の差が顕著に現れており、実務への導入には慎重なプロンプト設計と検証プロセスの構築が求められるという結論に至っています。