協調的推論のきらめき:戦略的な花火エージェントとしてのLLM
大規模言語モデル(LLM)を対象に、不完全情報下での高度な協調が必要なカードゲーム「花火(Hanabi)」を用いた過去最大規模の評価を実施し、最新の推論モデルが25点満点中平均15点から18点という高いスコアを記録することを明らかにした。
TL;DR(結論)
大規模言語モデル(LLM)を対象に、不完全情報下での高度な協調が必要なカードゲーム「花火(Hanabi)」を用いた過去最大規模の評価を実施し、最新の推論モデルが25点満点中平均15点から18点という高いスコアを記録することを明らかにした。 外部からの演繹的補助を与える「Sherlock」設定や、モデル自身が作業記憶を保持して状態を追跡する「Mycroft」設定を通じて、LLMが他者の意図を推測し、長期的な戦略を維持する高度な協調的推論能力を備えていることが示された。 新たに公開された「HanabiLogs」および「HanabiRewards」データセットを用いて40億パラメータのモデルを微調整した結果、性能が最大156%向上し、その能力が数学的推論や指示追従といった他の複雑なタスクへも汎用化されることが確認された。
なぜこの問題か
大規模言語モデルは、数学の問題解決やコード生成といった単一のエージェントによる推論タスクにおいて、国際数学オリンピック級の成績を収めるなど目覚ましい成功を遂げている。しかし、現実世界における人工知能の活用を考えると、複数のエージェントが互いに協力し、共通の目標を達成するために思考を同期させる「協調的推論」の能力が極めて重要となる。例えば、交差点における自動運転車同士の調整や、工場のフロアで人間と共に働く協調ロボットの運用には、他者の意図を察し、不確実な状況下で意思決定を行うスキルが不可欠である。こうしたスキルは、単一のエージェントによる問題解決能力を超えた、社会的な文脈の理解や「心の理論」を必要とするものである。 既存のベンチマークの多くは、単一エージェントの意思決定や競争的な力学に焦点を当てており、協力の本質的な難しさを評価するには不十分であった。そこで本研究では、協調的推論と心の理論を測定するための理想的な環境として、カードゲームの「花火」に注目した。花火は、プレイヤーが自分の手札を見ることができず、他のプレイヤーからの限られたヒントと、他者の行動から推測される意図のみを頼りに進めるゲームである。…
核心:何を提案したのか
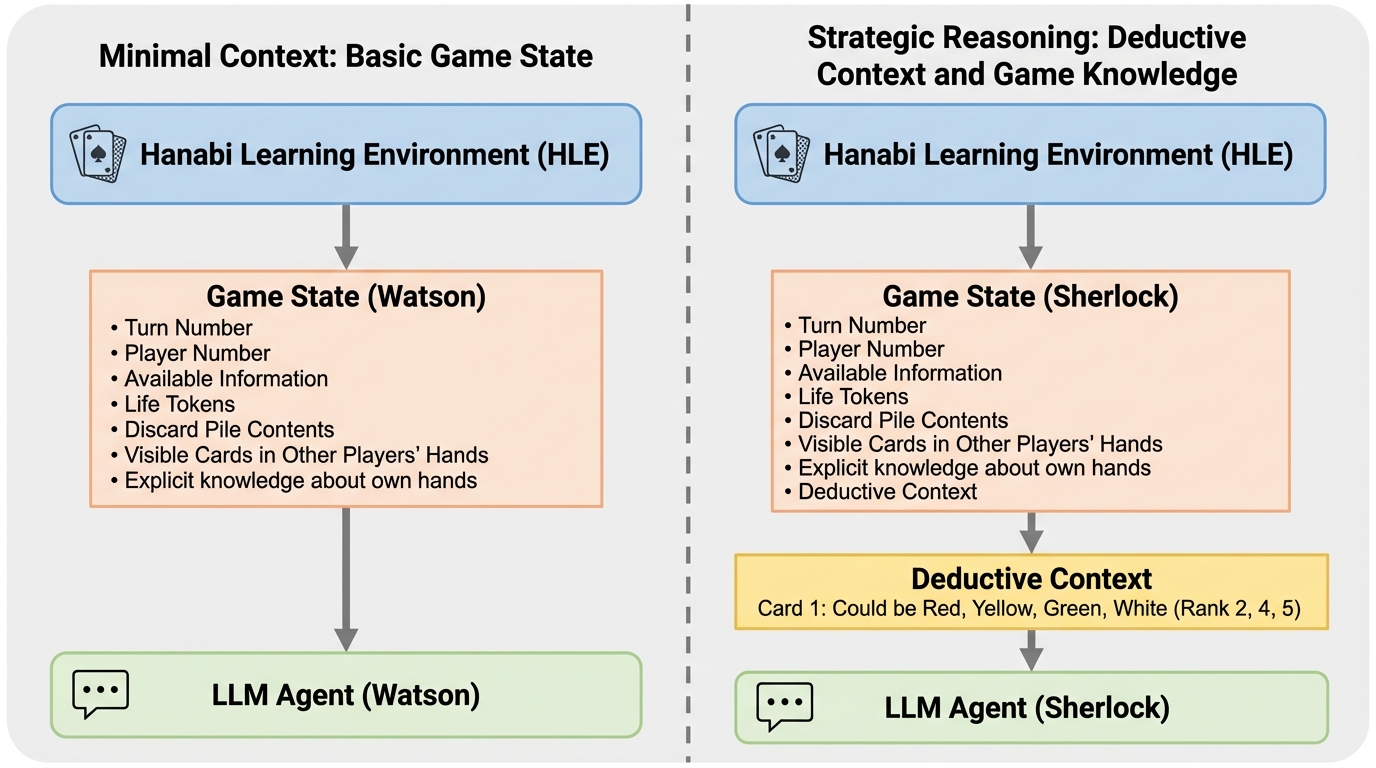
本研究の核心は、17種類の最新LLMを対象とした史上最大規模の「花火」エージェント評価スイートを構築し、透明性と再現性の高いベンチマークを確立したことにある。評価対象には、o3、o4-mini、DeepSeek-R1、Grok-3-mini、Gemini 2.5 Pro、GPT-4.1、Claude 3.7 Sonnetなど、業界をリードする多様なモデルが含まれている。これらのモデルに対し、情報の与え方を変えた3つのプロンプト設定(Watson、Sherlock、Mycroft)を導入することで、モデルの協調能力の限界と、外部補助に対する堅牢性を詳細に調査した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related