ランダムな概念の注入によるLLMの多様性への対処
大規模言語モデル(LLM)が特定の一般的な回答ばかりを生成してしまう「ロングテール問題(モード崩壊)」に対し、プロンプトの先頭に無関係なランダムな単語や文章を付加するだけで、出力の多様性が統計的に有意に向上することを明らかにしました。
TL;DR(結論)
大規模言語モデル(LLM)が特定の一般的な回答ばかりを生成してしまう「ロングテール問題(モード崩壊)」に対し、プロンプトの先頭に無関係なランダムな単語や文章を付加するだけで、出力の多様性が統計的に有意に向上することを明らかにしました。 この手法は、モデルの内部的な条件付き確率分布を変化させることで、通常は選ばれにくい「ロングテール」に位置する回答の選択確率を押し上げ、生成されるユニークな回答数とエントロピー(分布の複雑さ)を効果的に増加させます。 Gemma3やClaude 3.5 Sonnetなど、モデルの規模や開発元を問わず有効であり、温度設定などの既存のサンプリング手法とは独立して機能するため、計算コストを抑えつつAIの創造性を引き出す軽量なアプローチとして期待されます。
なぜこの問題か
大規模言語モデルは、インターネット上の膨大なテキストデータから学習を行い、次に続く単語を予測する能力を磨くことで、チャットやコーディング、執筆などの多様なタスクで驚異的な性能を発揮しています。しかし、これらのモデルには「多様性の欠如」という深刻な課題が存在します。モデルは学習データの中で頻出するパターンを優先的に学習するため、同じ質問を繰り返すと、常に一般的で典型的な回答ばかりを生成する傾向があります。例えば「ハリウッド俳優を10人挙げてください」という質問に対し、モデルは何度繰り返しても同じ有名な俳優のリストを提示し、あまり有名ではないが条件に合致する他の俳優を無視してしまうことがあります。 このような現象は、生成される回答の頻度分布において、ごく一部の回答が高い頻度を占め、それ以外の多くの候補が全く選ばれない「ロングテール問題」あるいは「モード崩壊」と呼ばれています。特定の事実を正確に答えるタスクでは一般的な回答が望ましいこともありますが、短編小説の執筆、ユーモアの生成、斬新なアイデア出しといった創造性が求められる場面では、出力のバリエーションが乏しいことは致命的な欠点となります。…
核心:何を提案したのか
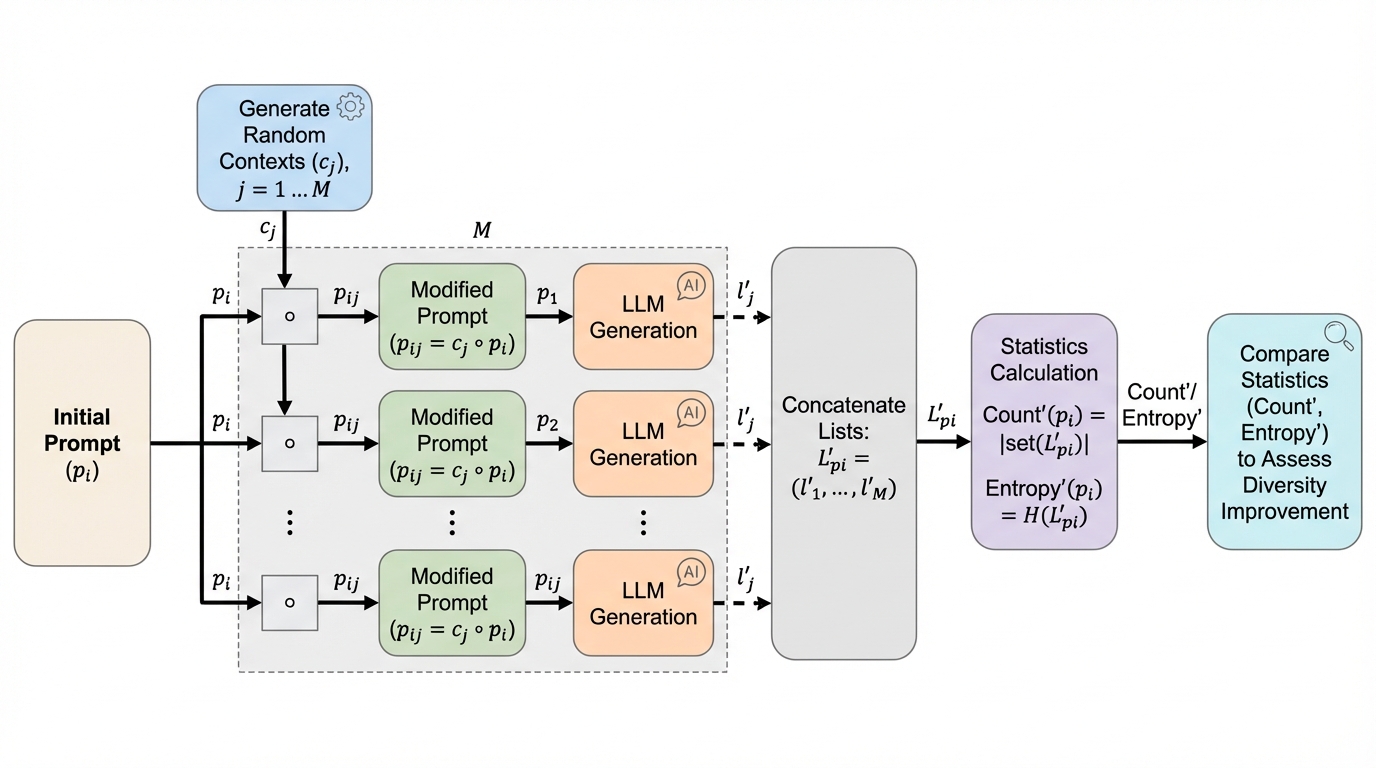
本研究が提案するのは、プロンプトの冒頭に「ランダムな概念」を注入するという、極めてシンプルかつ軽量な手法です。具体的には、ユーザーが本来入力したいプロンプトの直前に、その内容とは全く無関係なランダムな単語や文章を結合してモデルに与えます。例えば「アフリカの国を10個挙げてください」という質問の前に、「笑う」「複雑な」「危険な」といった無関係な単語を置く、あるいは「その謎が視覚疲労を休止させる」といった意味不明な文章を置くという方法です。 この手法の最大の特徴は、既存の多様性向上テクニックとは「直交する(独立している)」点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related