大規模言語モデルを用いた氏名・住所解析システム
非構造化された氏名や住所のテキストを、大規模言語モデルと決定論的な検証レイヤーを組み合わせることで、17項目の詳細なスキーマに変換する新しいフレームワークを提案しました。 追加のファインチューニングを一切行わず、入力の正規化、構造化されたプロンプト、制約付きデコード、そして厳格なルールベースの検証を統合することで、99.8%という極めて高い解析精度を達成しています。 このシステムは、多言語対応や誤字脱字への耐性を持ちながら、郵便番号と州の整合性チェックなどの実世界の制約を強制することで、大規模な情報システムにおける信頼性と再現性の高いデータ抽出を低コストで実現します。
TL;DR(結論)
非構造化された氏名や住所のテキストを、大規模言語モデルと決定論的な検証レイヤーを組み合わせることで、17項目の詳細なスキーマに変換する新しいフレームワークを提案しました。 追加のファインチューニングを一切行わず、入力の正規化、構造化されたプロンプト、制約付きデコード、そして厳格なルールベースの検証を統合することで、99.8%という極めて高い解析精度を達成しています。 このシステムは、多言語対応や誤字脱字への耐性を持ちながら、郵便番号と州の整合性チェックなどの実世界の制約を強制することで、大規模な情報システムにおける信頼性と再現性の高いデータ抽出を低コストで実現します。
なぜこの問題か
非構造化された人物名や住所のテキストを、信頼性の高い構造化データに変換することは、現代の大規模な情報システムにおいて極めて重要な課題となっています。郵便配達、顧客のオンボーディング、本人確認、データの統合といった多岐にわたるアプリケーションは、すべて機械が読み取り可能な形式に正確に変換された記録に依存しています。しかし、現実世界の住所データは非常に一貫性が低く、ユーザーがカンマや区切り文字を省略したり、複数の言語を混ぜたり、略語を使用したりすることが頻繁に発生します。また、タイポグラフィの誤りやフォーマットの不備も多く、これらの不整合は後続の処理に伝播し、マッチングやジオコーディング、レコードのリンク精度の低下を招く直接的な原因となります。 これまでの研究では、主にルールベースのアプローチや確率的なモデルが用いられてきました。初期の確率的手法では、隠れマルコフモデルを大規模な住所データセットに適用し、シーケンスモデリングを通じてセグメンテーションと正規化を行っていました。また、非ラテン文字、特に複雑な中国語の住所文字列に対しては、潜在構造ネットワークを用いたニューラルモデルも探索されてきました。…
核心:何を提案したのか
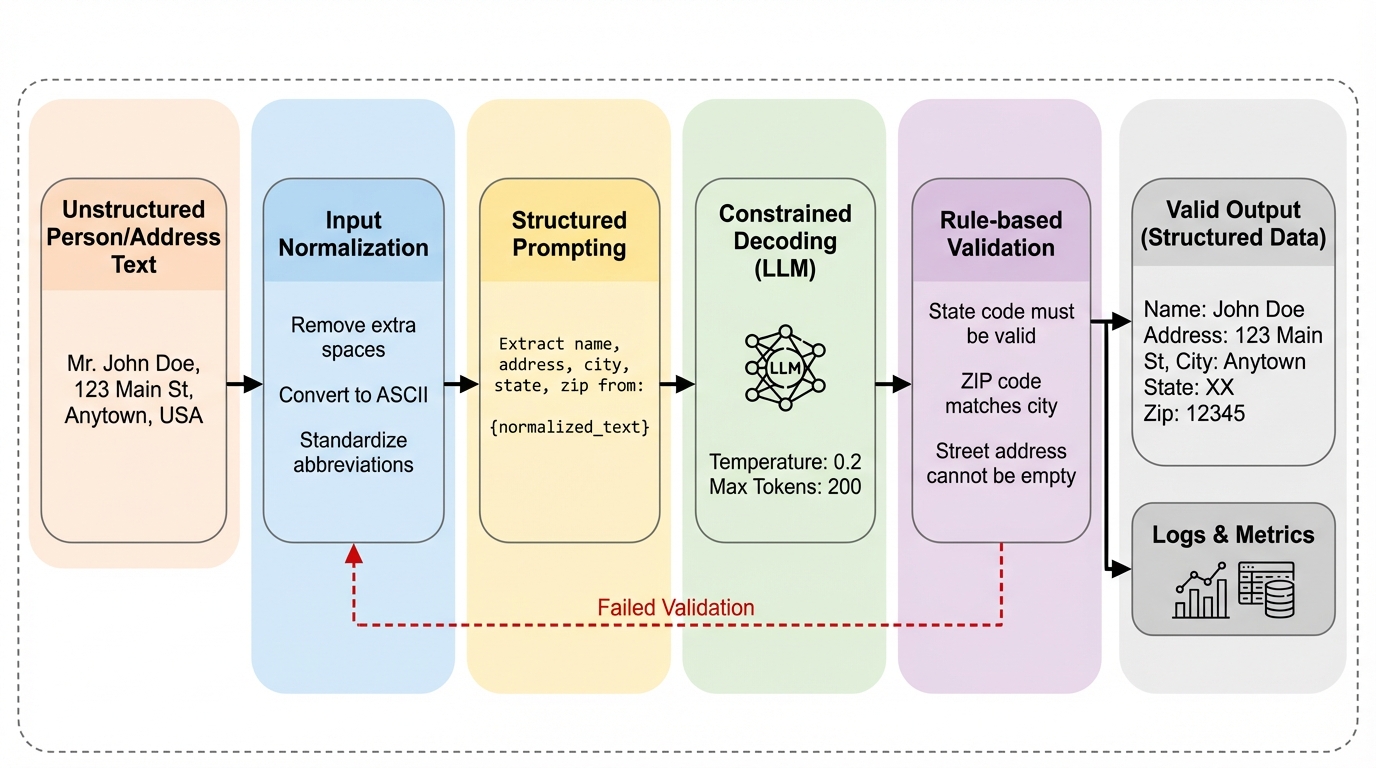
本研究が提案する核心的な手法は、モデルのファインチューニングを一切行わずに、プロンプト駆動型のパイプラインと決定論的な検証レイヤーを統合したフレームワークです。このシステムは、非構造化されたテキストを17の特定のフィールドからなるスキーマへと変換するように設計されています。具体的には、入力の正規化、プロンプトの組み立て、制約付きの推論、そして厳格な検証という4つの段階で構成されるパイプラインを採用しています。この設計の主な目的は、異種混合の入力に対応しつつ、遅延やコストを抑え、高い再現性を確保することにあります。 システムの中心となるのは、AWS Bedrockを介してアクセスされるClaude 4.0 Sonnetモデルです。このモデルは、温度設定やデコードパラメータを固定したプロダクション構成で運用され、各推論コールはステートレスなAPIクライアントを通じて実行されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related