RIR-Mega-Speech:網羅的な音響メタデータと再現可能な評価を備えた残響音声コーパス
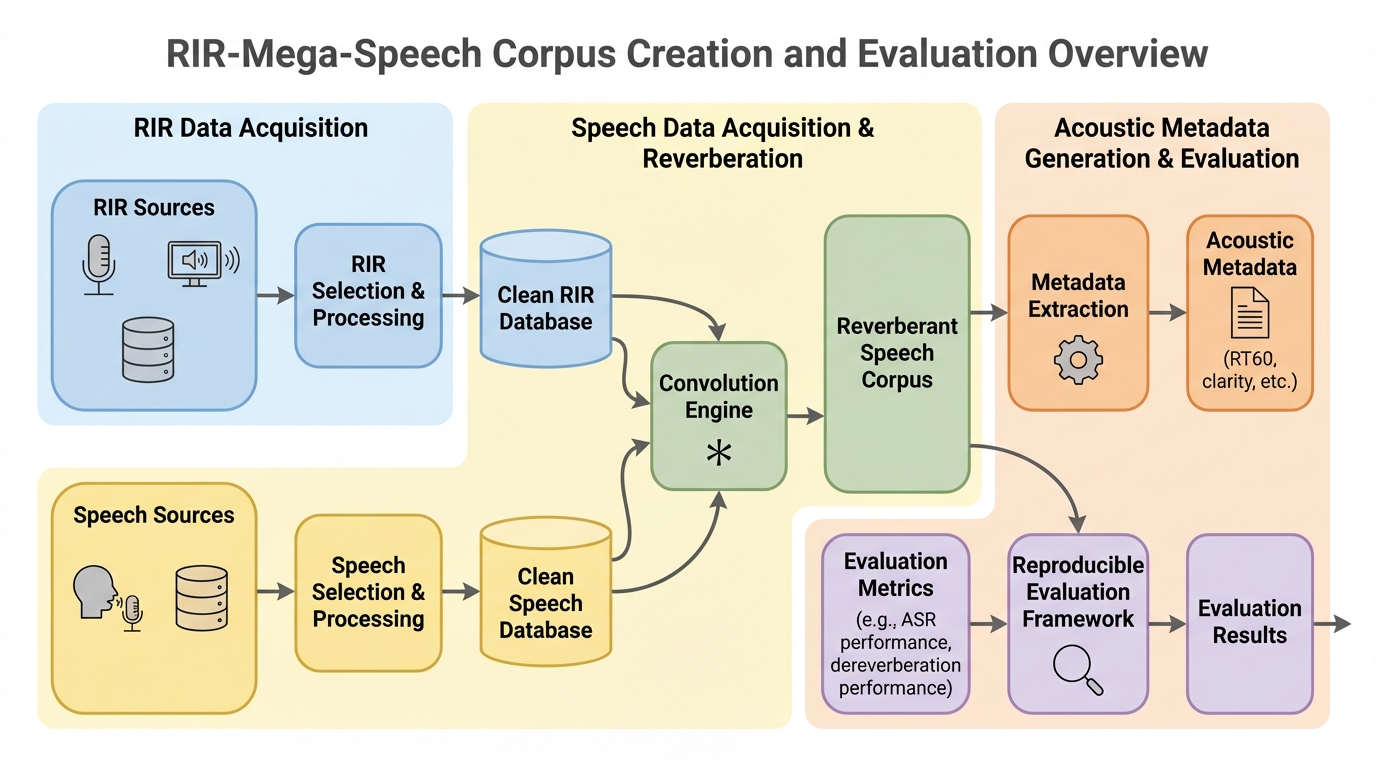
RIR-Mega-Speechは、LibriSpeechの音声と約5,000のシミュレーションされた部屋インパルス応答(RIR)を組み合わせた、約117.5時間の新しい残響音声コーパスである。最大の特徴は、全ファイルに対してRT60、直接音対残響音比(DRR)、明瞭度指数(C50)といった詳細な音響メタデータが付与されている点にあり、WindowsおよびLinux環境でデータセットの再構築や評価結果の再現が可能なスクリプトが提供されている。Whisper smallモデルを用いた検証では、残響によって単語誤り率(WER)が5.20%から7.70%へと相対的に48%悪化することが示され、RT60の増加やDRRの低下に伴って認識精度が単調に低下する物理的特性と一致する傾向が確認された。
TL;DR(結論)
RIR-Mega-Speechは、LibriSpeechの音声と約5,000のシミュレーションされた部屋インパルス応答(RIR)を組み合わせた、約117.5時間の新しい残響音声コーパスである。最大の特徴は、全ファイルに対してRT60、直接音対残響音比(DRR)、明瞭度指数(C50)といった詳細な音響メタデータが付与されている点にあり、WindowsおよびLinux環境でデータセットの再構築や評価結果の再現が可能なスクリプトが提供されている。Whisper smallモデルを用いた検証では、残響によって単語誤り率(WER)が5.20%から7.70%へと相対的に48%悪化することが示され、RT60の増加やDRRの低下に伴って認識精度が単調に低下する物理的特性と一致する傾向が確認された。
なぜこの問題か
残響音声に関する研究は数十年にわたり行われてきたが、異なる手法を公平に比較することは依然として困難な課題である。その主な理由は、既存の多くの残響コーパスにおいて、ファイルごとの詳細な音響アノテーションが不足していることや、再現のためのドキュメントが限定的であることにある。例えば、広く利用されているREVERB Challengeでは、ペアとなるクリーン音声と残響音声、および評価スクリプトは提供されているものの、ファイル単位の音響メタデータが含まれていないため、特定の音響条件に基づいた詳細な分析が制限されている。また、CHiMEシリーズやAISHELL-4といったコーパスは、現実的な環境での録音を含んでいるが、RT60(残響時間)やDRRといったパラメータが系統的にアノテーションされていない。 現実の環境において、残響は自動音声認識(ASR)の性能を著しく低下させる要因となる。後方反射が音の微細な時間構造を乱し、音素の明瞭性を損なうためである。近年の自己学習型モデルはチャネル効果に対して一定の堅牢性を示しているが、減衰時間が長い部屋や直接音の経路が弱い環境では依然としてエラーが発生しやすい。…
核心:何を提案したのか
本研究では、約117.5時間の規模を持つ残響音声コーパス「RIR-Mega-Speech」を提案した。このコーパスは、高品質な書き起こしデータを持つLibriSpeechの音声と、物理ベースの音響シミュレーションによって生成されたRIR-Megaコレクションのインパルス応答を畳み込み演算することで作成されている。最大の特徴は、全ての残響ファイルに対して、RT60、DRR、およびC50という3つの主要な音響指標が計算され、メタデータとして付与されている点である。これにより、研究者は特定の残響時間や直接音比率の条件下でモデルがどのように振る舞うかを詳細に分析することが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related