接地された具体性:視覚言語モデルにおける人間のような具体性への感受性
視覚と言語を統合して学習したモデル(VLM)が、テキストのみのモデル(LLM)と比較して、言葉の「具体性」に対して人間により近い感受性を持つかを、Llamaシリーズを用いた制御された比較実験によって検証した。
TL;DR(結論)
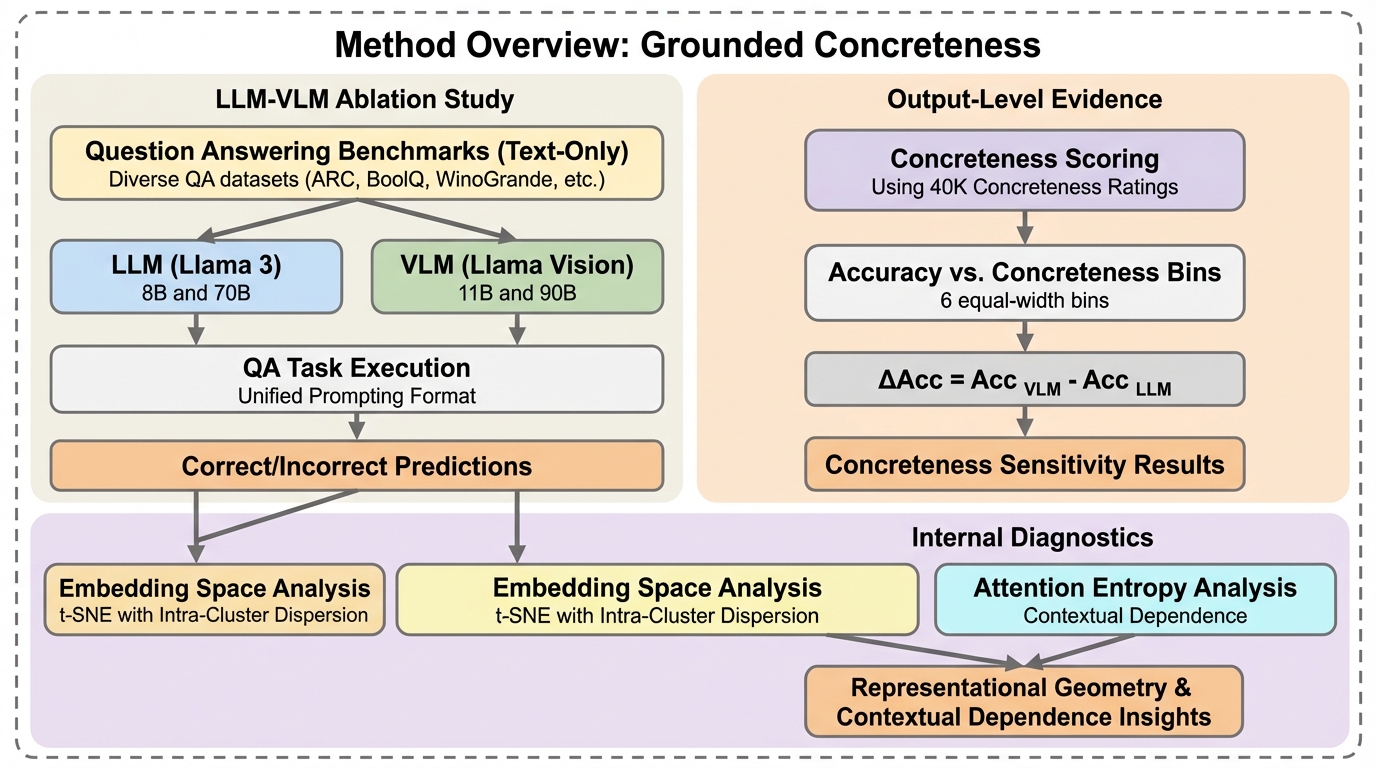
視覚と言語を統合して学習したモデル(VLM)が、テキストのみのモデル(LLM)と比較して、言葉の「具体性」に対して人間により近い感受性を持つかを、Llamaシリーズを用いた制御された比較実験によって検証した。VLMは具体的な概念を含む質問に対して高い回答精度を示すだけでなく、内部の埋め込み表現においても具体的な単語が明確にクラスター化されるなど、視覚的な接地が言語理解の構造を質的に変化させることが明らかになった。注意機構の解析では、抽象的な言葉ほど周囲の文脈に依存し、具体的な言葉は焦点が絞られるという人間の認知特性に近い挙動が確認され、画像を入力しないテキストのみの推論時でも視覚学習の恩恵が維持されることが示された。これにより、記号接地問題に対する新たな知見が提供された。
なぜこの問題か
人間の言語理解において、すべての言葉が同じように処理されるわけではない。リンゴや走るといった知覚や行動に直接結びついた具体的な概念がある一方で、正義や完全といった関係性や文脈に強く依存する抽象的な概念が存在する。認知科学の長い伝統において、具体性は概念表現の段階的な次元として扱われており、具体的な言葉は豊かな感覚コードの恩恵を受け、抽象的な言葉よりも記憶や理解において頑健な行動上の利点を示すことが知られている。しかし、現代の巨大言語モデル(LLM)の多くはテキストデータのみから学習しており、知覚的な経験を欠いた状態で「意味」を真に獲得できるのかという記号接地問題が大きな議論の対象となっている。分布学習によって多くの意味的な規則性を捉えることは可能だが、知覚経験の欠如は特に具体性の処理において決定的な影響を及ぼす可能性がある。人間の場合、具体的な概念は感覚運動のシミュレーションやイメージのようなコードによって支えられているからである。視覚と言語を同時に学習する視覚言語モデル(VLM)は、この議論を検証するための理想的な環境を提供するが、これまでの研究では視覚の効果を厳密に分離して評価することが困難であった。…
核心:何を提案したのか
本研究は、視覚と言語のマルチモーダルな事前学習が、推論時に画像を与えないテキストのみの条件下であっても、モデルの具体性に対する感受性を向上させるという仮説を提案し、それを実証した。具体的には、MetaのLlama 3.1(テキスト専用)とLlama 3.2(視覚対応)という、モデルスケールとバックボーンが一致したペアを用いて、視覚情報の有無が言語処理に与える影響を「アブレーション(切除)実験」として評価した。分析は、出力挙動、埋め込み表現の幾何学的構造、注意機構のダイナミクスの3つの相補的なレベルで行われた。第一に、質問応答(QA)の精度と質問文の具体性の相関を調べ、さらにモデル自身に単語の具体性を評価させて人間の基準値との一致度を測定した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related