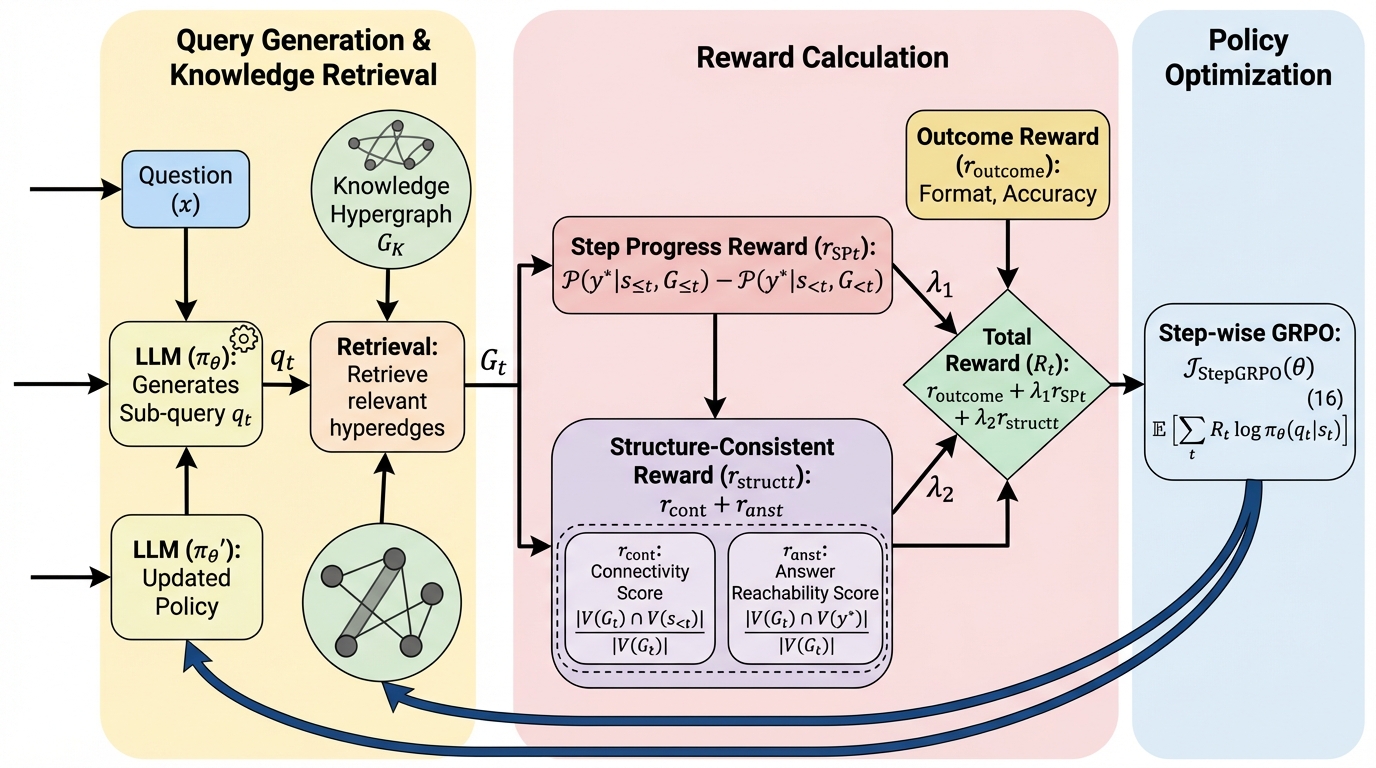
ProGraph-R1:グラフ検索拡張生成のための進捗を考慮した強化学習
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、グラフ構造のつながりと推論の進捗状況を同時に考慮する新しい強化学習フレームワーク「ProGraph-R1」が開発されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、グラフ構造のつながりと推論の進捗状況を同時に考慮する新しい強化学習フレームワーク「ProGraph-R1」が開発されました。
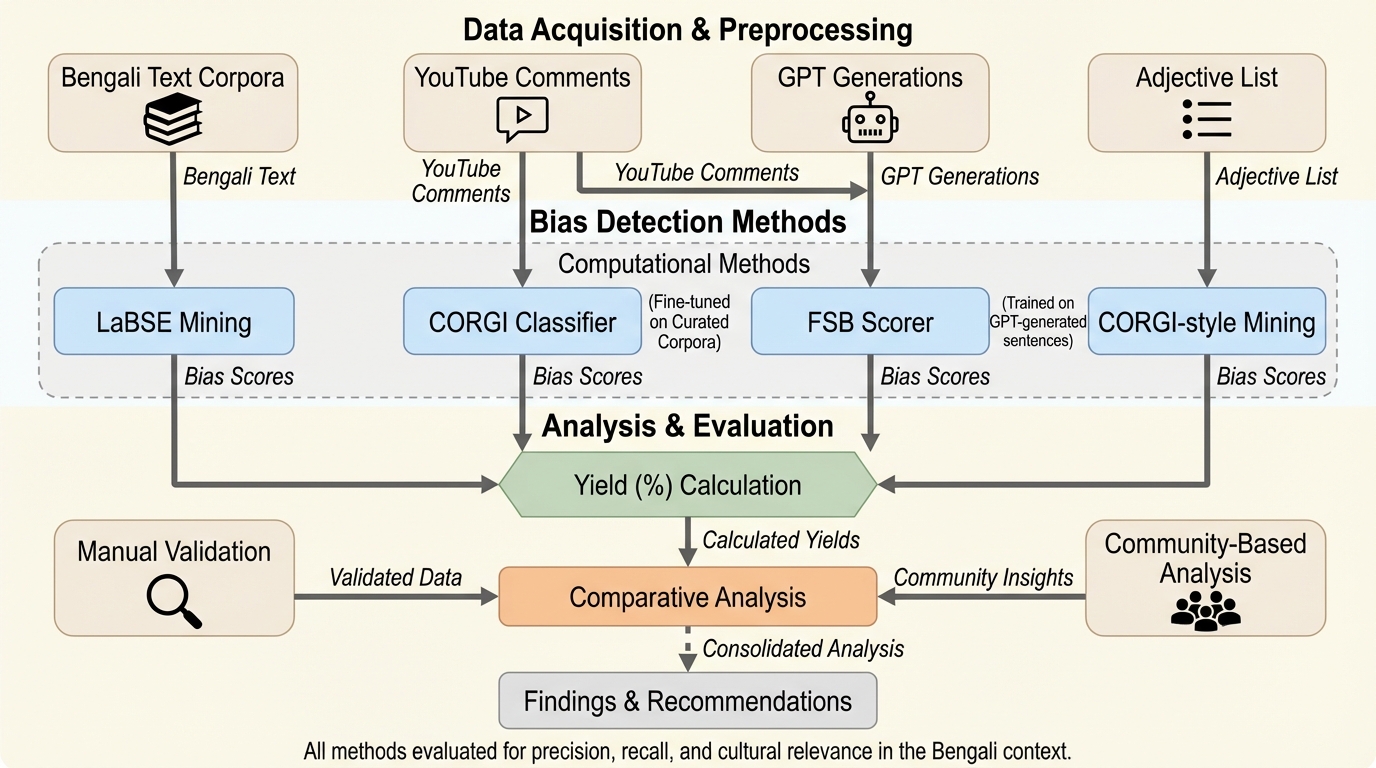
大規模言語モデル(LLM)におけるジェンダーバイアスの研究は英語に偏っており、ベンガル語のような低リソース言語かつ独自の文化背景を持つ言語での実態は十分に解明されていませんでした。 本研究では、翻訳、分類器、GPTによる生成、辞書ベースのマイニングなど多角的な手法を用いてベンガル語のバイアスを検証し、英語中心の検出枠組みをそのまま適用することの限界を明らかにしました。 農村部でのフィールド調査を含むコミュニティ主導のアプローチを導入することで、自動化システムでは捉えきれない文化特有のバイアスを特定し、より公平な自然言語処理システムの構築に向けた基盤を提示しました。
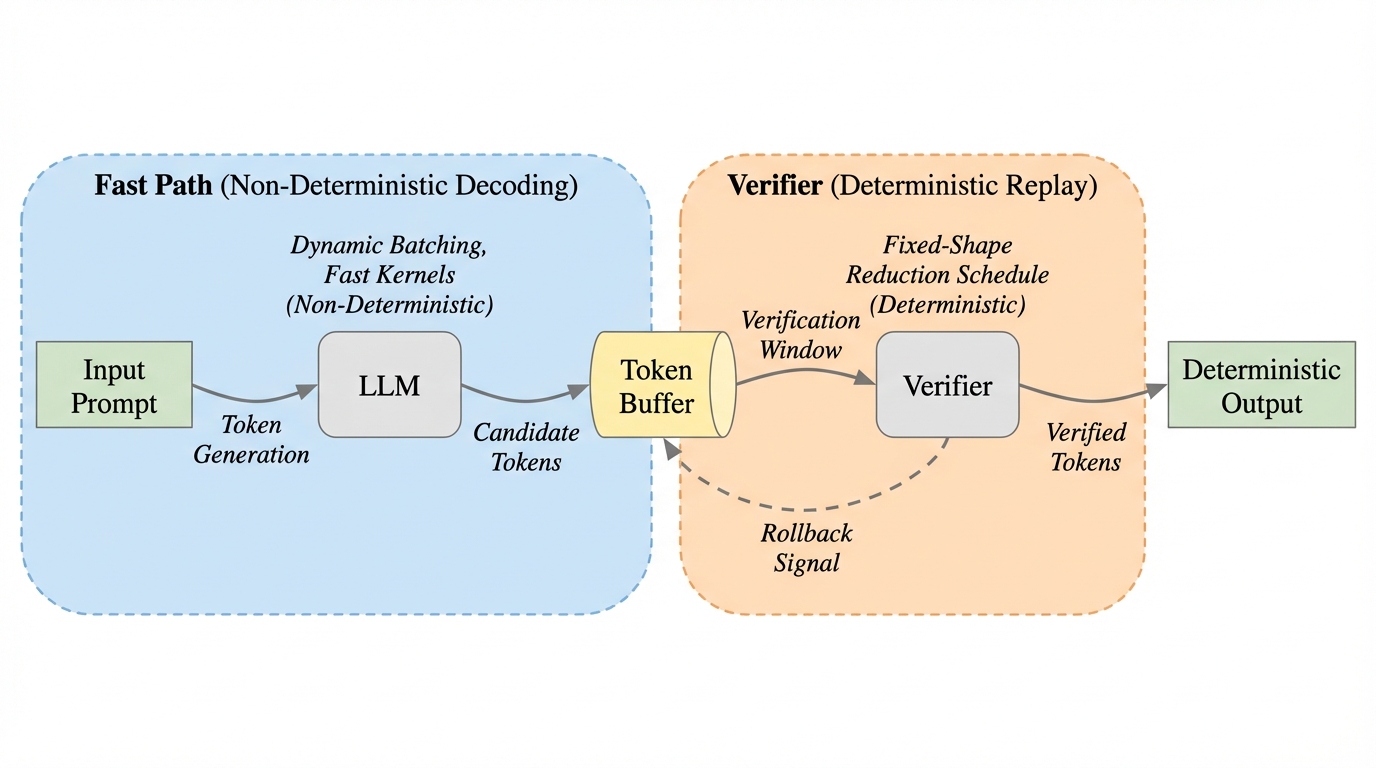
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。
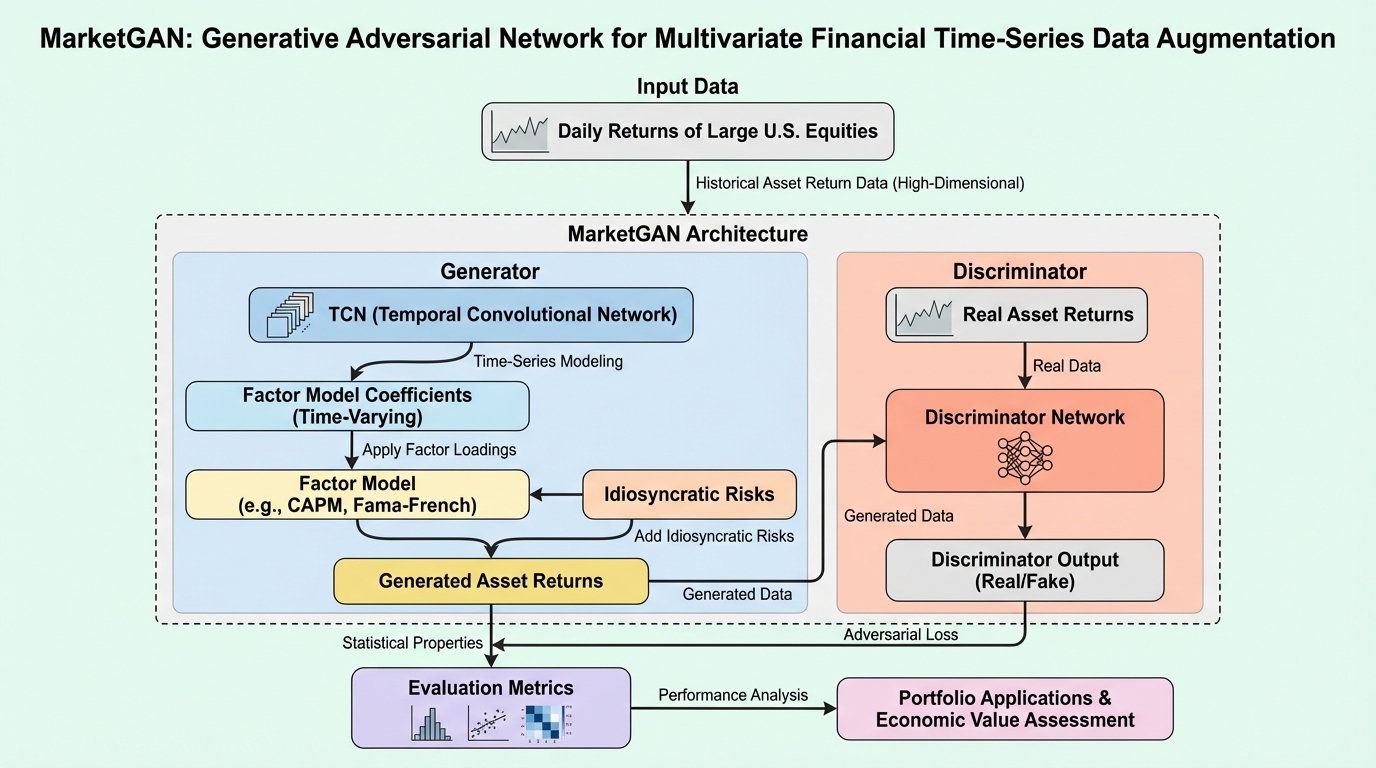
金融市場における高次元な資産収益率の生成は、利用可能なデータが限られているため、推定が極めて困難であるという課題に直面しています。 本研究で提案されたMarketGANは、資産価格モデルの要素構造を経済的なバイアスとして組み込み、時間的畳み込みネットワーク(TCN)を用いて動的な要因負荷量やボラティリティをモデル化する生成フレームワークです。 米国株式のデータを用いた検証では、従来のブートストラップ手法よりも高い精度で相関構造やテールの共動性を再現し、ポートフォリオ最適化においても優れた経済的価値を示すことが確認されました。
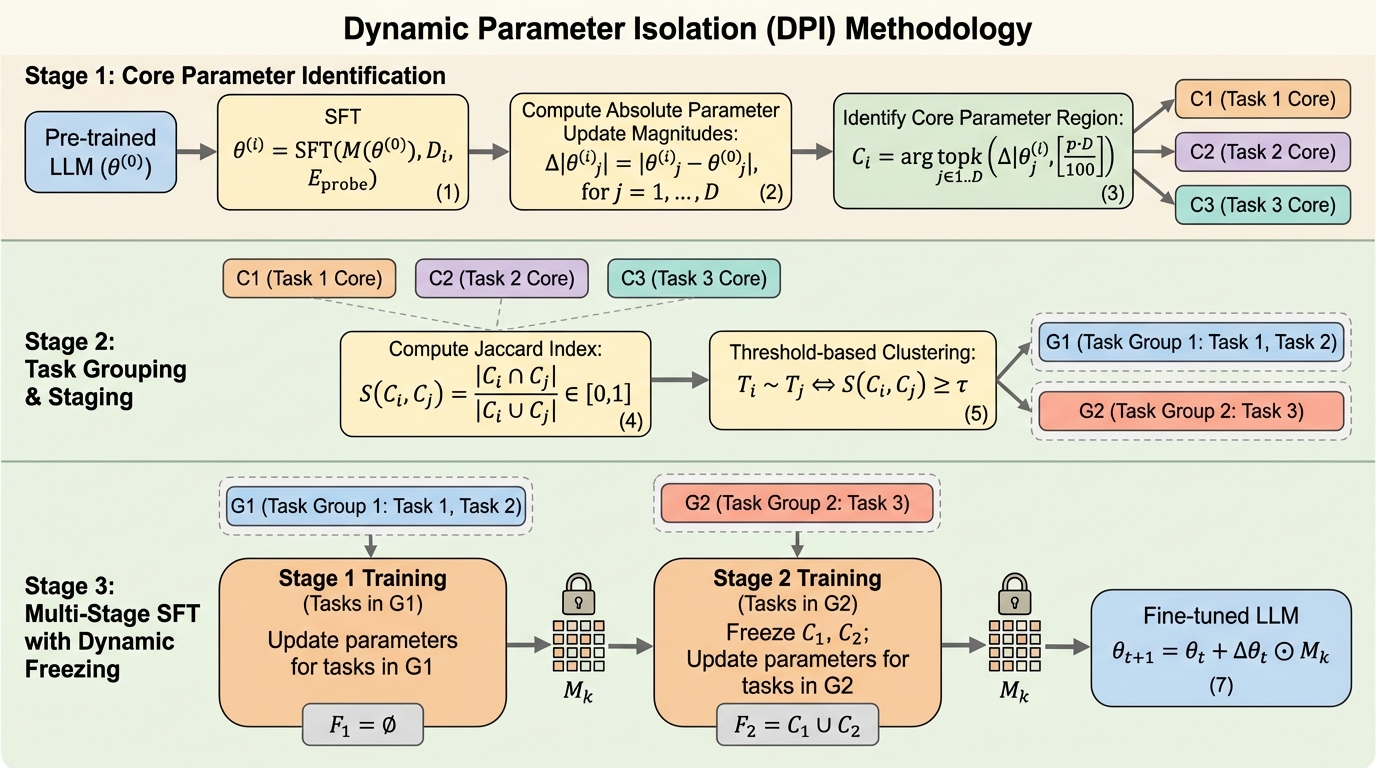
大規模言語モデル(LLM)の教師あり微調整(SFT)において、異なるタスク間の目的が衝突することで一方の性能が上がると他方が下がる「シーソー現象」を解決するため、タスクごとに依存するパラメータ領域が異なるという「パラメータの不均一性」に着目した新しい手法「DPI」が提案された。
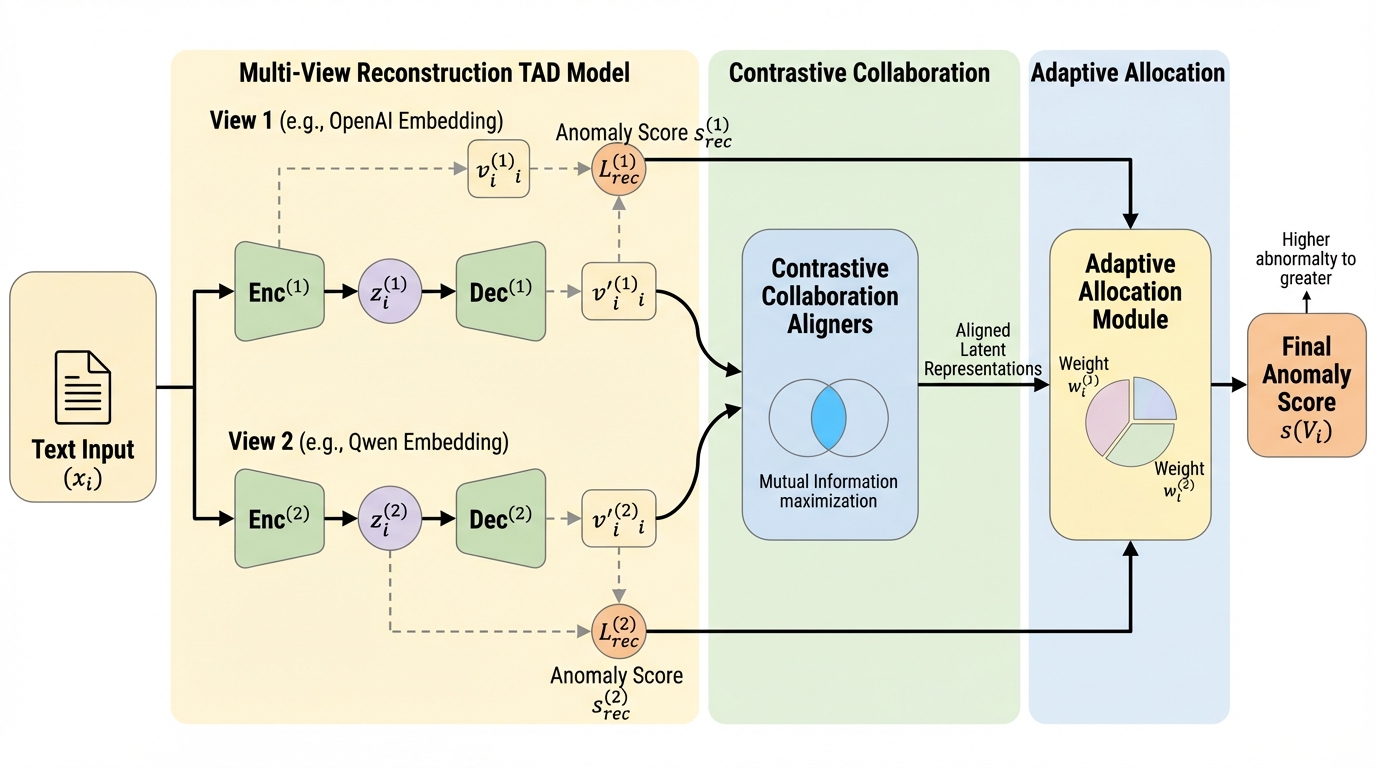
従来のテキスト異常検知は単一の埋め込みモデルに依存しており、特定のデータ分布への偏りや未知の異常に対する適応力の不足が大きな課題となっていましたが、本研究では複数の言語モデルの表現を統合する新しいフレームワークであるMCA²を提案しました。
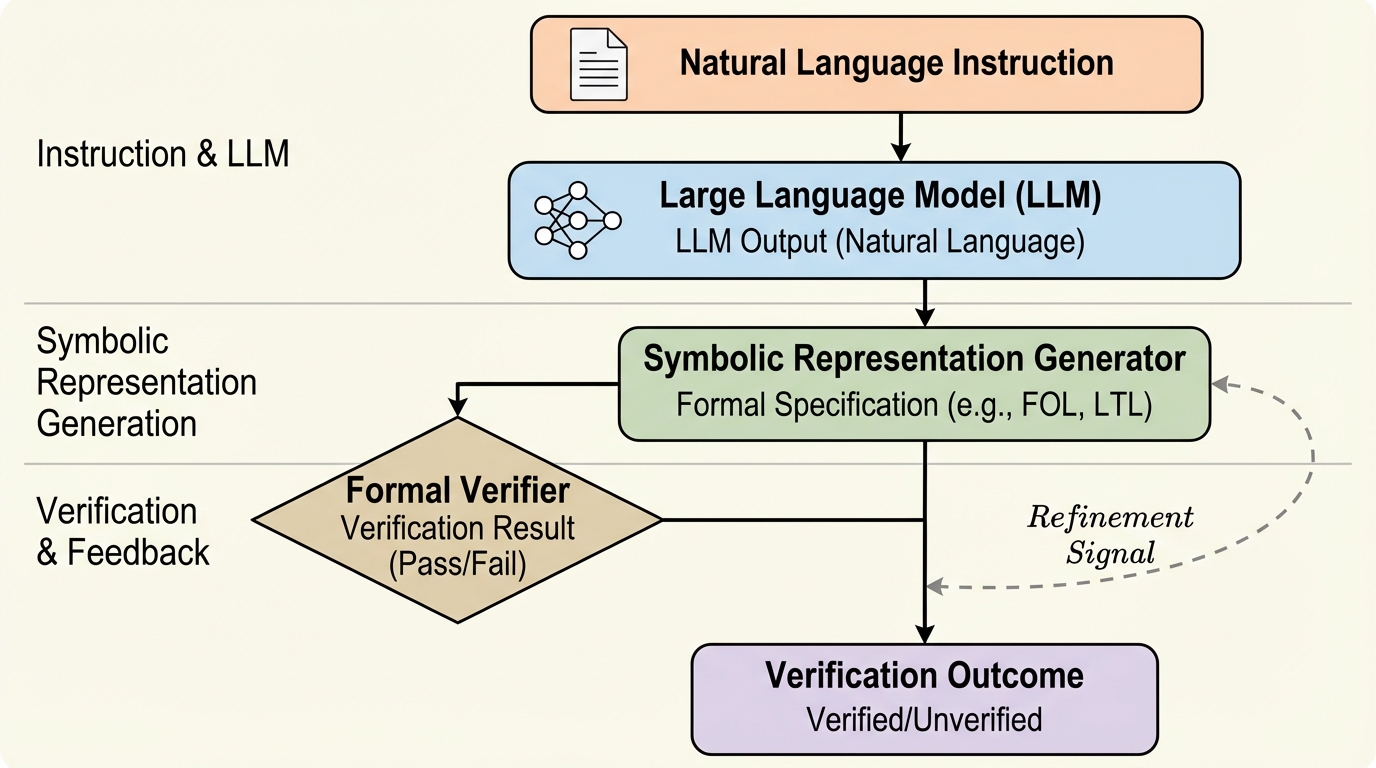
大規模言語モデル(LLM)が複雑な指示を誤解したり無視したりする問題に対し、指示を制約充足問題(CSP)として定式化し、論理的および意味的な制約の両面から出力を厳密に検証する汎用フレームワーク「NSVIF」が開発されました。
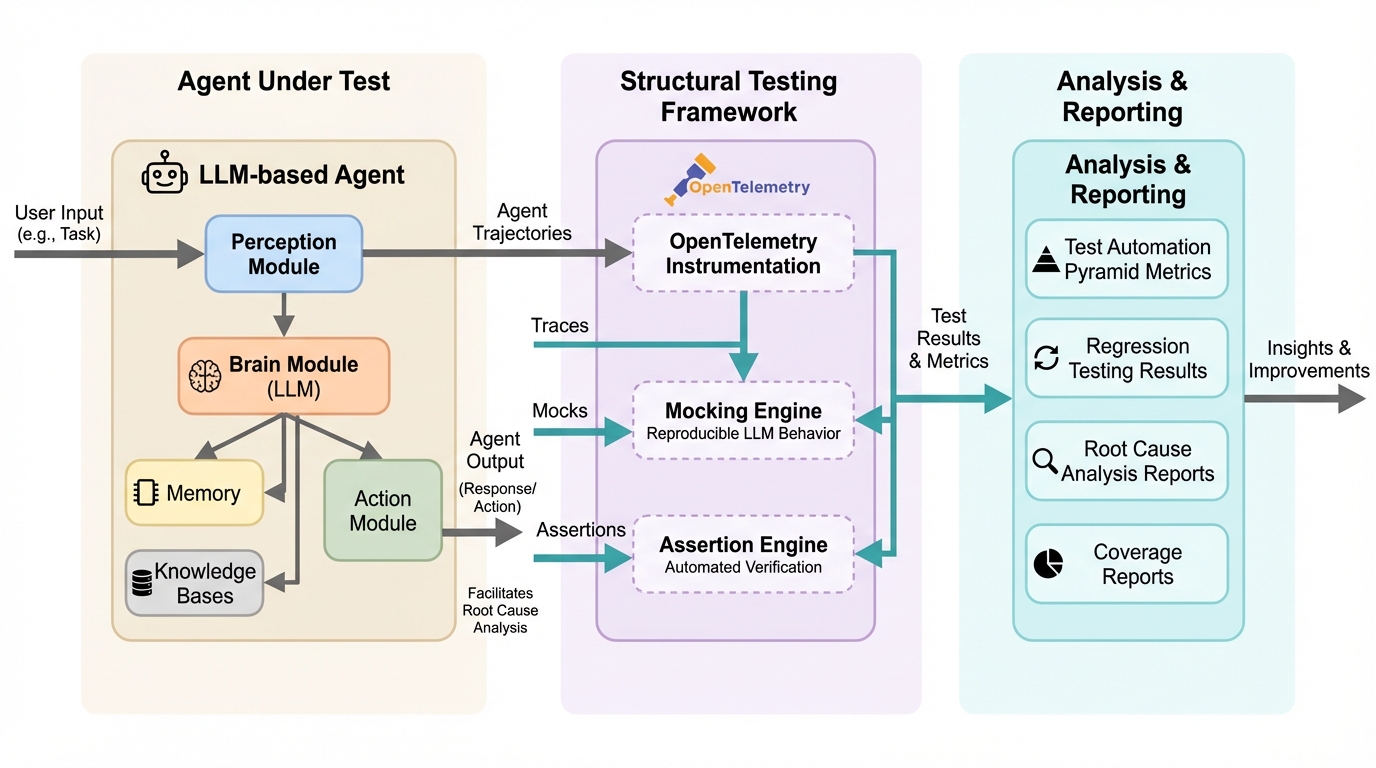
LLMエージェントの普及に伴い、従来のユーザー視点によるブラックボックス形式の受入テストだけでは、内部動作の不透明さや高コスト、再現性の欠如といった課題が顕在化している。 本研究では、OpenTelemetryを用いた実行トレースの取得、LLMの挙動を固定するモッキング、自動検証のためのアサーションを組み合わせた「構造テスト」の手法とフレームワークを提案し、技術的な深層レベルでの検証を可能にした。 このアプローチにより、テスト自動化ピラミッドやテスト駆動開発といったソフトウェア工学のベストプラクティスをエージェント開発に適用でき、品質向上と開発コストの削減、迅速な不具合原因の特定が実現されることを実証した。
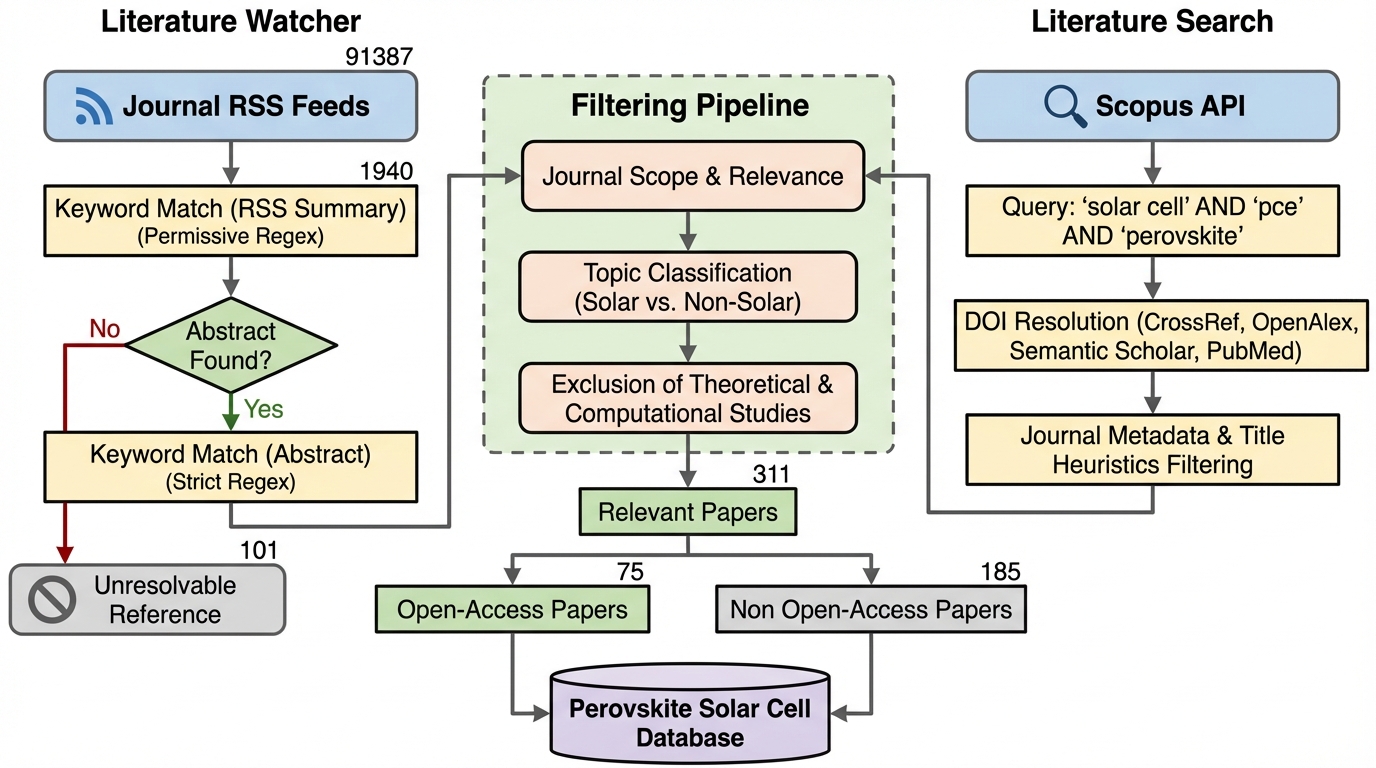
科学論文の指数関数的な増加により、手動でのデータ収集が限界に達し、主要なデータベースが2021年以降更新されないという深刻な知識の空白が生じていたが、本研究では大規模言語モデル(LLM)と物理的検証を統合した自律更新型データベース「PERLA」を開発した。
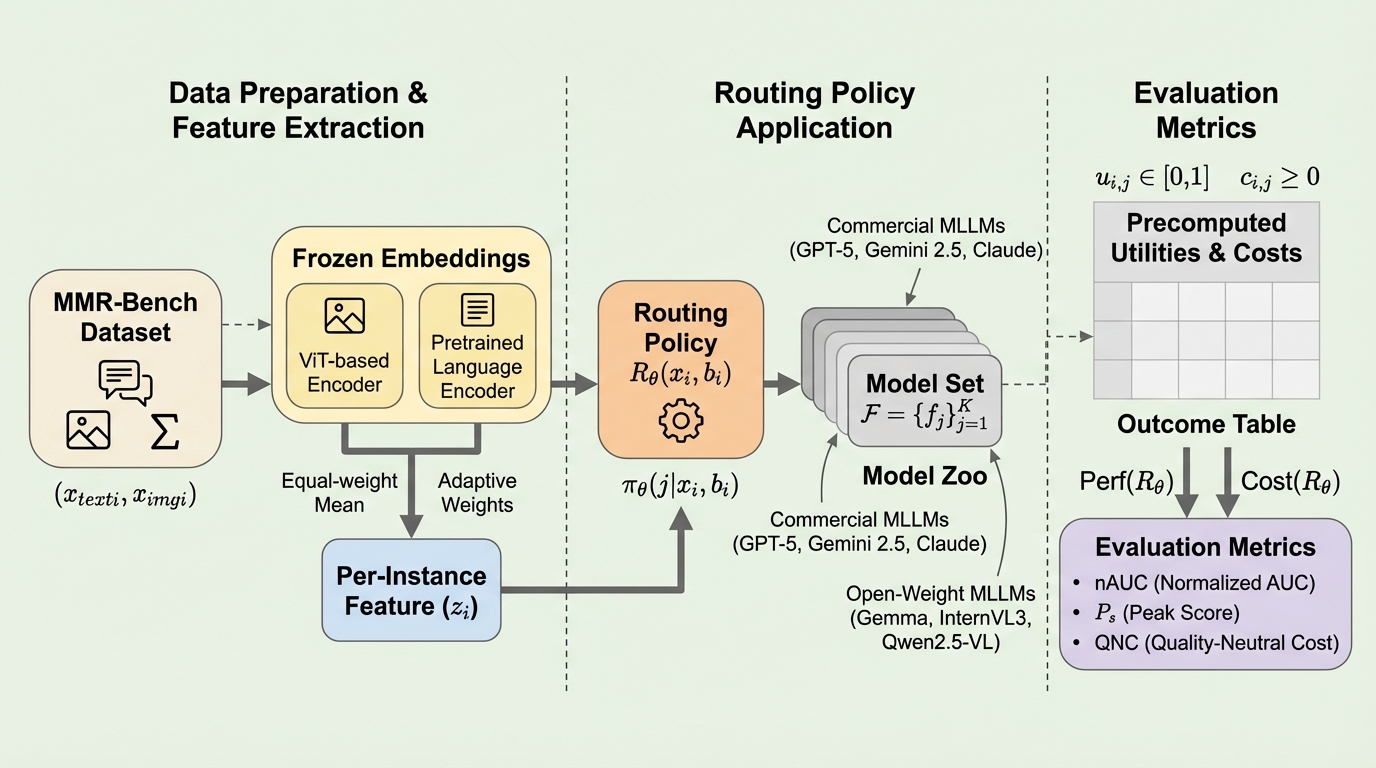
マルチモーダル大規模言語モデル(MLLM)の急速な発展に伴い、モデルごとの能力やコストの不均一性が顕著になっているが、本研究ではクエリごとに最適なモデルを選択して精度とコストのバランスを最適化する「ルーティング」のための包括的ベンチマーク「MMR-Bench」を提案した。