DIETA:イタリア語-英語機械翻訳のためのデコーダのみを用いたTransformerベースモデル
DIETAは、イタリア語と英語の双方向翻訳に特化して設計された、5億パラメータという比較的小規模なデコーダ専用Transformerモデルであり、大規模な精選コーパスと逆翻訳データを活用して構築されました。
TL;DR(結論)
DIETAは、イタリア語と英語の双方向翻訳に特化して設計された、5億パラメータという比較的小規模なデコーダ専用Transformerモデルであり、大規模な精選コーパスと逆翻訳データを活用して構築されました。 約2億700万組の高品質な並列文ペアと3億5200万組の合成データを学習に用い、最新の2025年ニュース記事を含む独自評価セットWikiNews-25においても、既存の大型モデルに匹敵する高い翻訳精度を確認しています。 32のシステムを対象とした評価において一貫して上位25〜50%にランクインし、30億パラメータ未満のモデルの多くを凌駕する性能を示す一方で、計算リソースの消費を抑えた効率的な翻訳ソリューションを提供します。
なぜこの問題か
自然言語処理の分野では、Transformerベースの大規模言語モデル(LLM)がテキスト分類や質問応答、機械翻訳などの多岐にわたるタスクで飛躍的な進歩を遂げました。しかし、イタリア語と英語のような特定の言語ペアにおける高品質なニューラル機械翻訳には、依然として解決すべき課題が残されています。汎用的な多言語システムは、数百の言語をカバーすることを優先するあまり、個別の言語ペアに対する翻訳品質の最適化が不十分になる傾向があります。これは、限られたモデル容量を多くの言語で共有しなければならないという、表現能力の競合が原因の一つと考えられます。 既存のイタリア語対応モデルには、MinervaやLLaMAntino、Cerbero、ModelloItaliaなどがありますが、これらは主に汎用的な言語モデルとして設計されており、翻訳タスクに特化して最適化されているわけではありません。また、広く利用されているOPUS-MTシリーズは軽量で導入しやすいものの、最新のLLMベースのシステムと比較すると、流暢さや多様な文脈への対応力の面で課題が見られます。…
核心:何を提案したのか
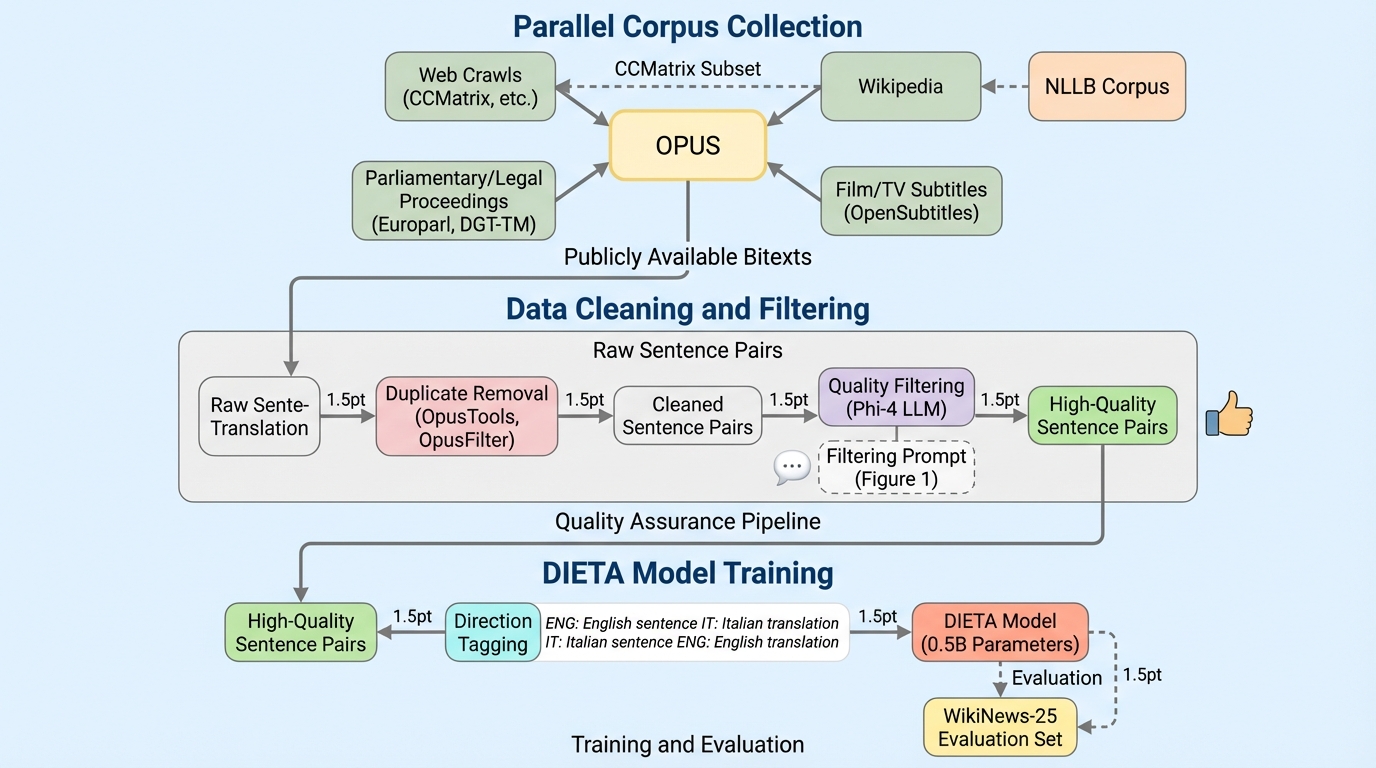
本論文では、イタリア語と英語の双方向翻訳のためにゼロからトレーニングされた、5億パラメータのデコーダ専用Transformerモデル「DIETA」を提案しています。このモデルの核心は、小規模なアーキテクチャでありながら、徹底的に精選された大規模な学習データセットを組み合わせることで、高い翻訳精度を実現した点にあります。研究チームは、まず公開されているリソースから、議会議事録(Europarl、DGT-TM)、法的文書、ウェブクロール(ParaCrawl)、字幕(OpenSubtitles)、百科事典(WikiMatrix)、文学作品など、多様なドメインにわたる約2億700万組の高品質なイタリア語・英語の並列文ペアを収集しました。 さらに、言語の多様性と時間的な関連性を強化するために、逆翻訳技術を用いた大規模な合成コーパスの構築を行いました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related