DPI:干渉のないファインチューニングのためのパラメータ不均一性の活用
大規模言語モデル(LLM)の教師あり微調整(SFT)において、異なるタスク間の目的が衝突することで一方の性能が上がると他方が下がる「シーソー現象」を解決するため、タスクごとに依存するパラメータ領域が異なるという「パラメータの不均一性」に着目した新しい手法「DPI」が提案された。
TL;DR(結論)
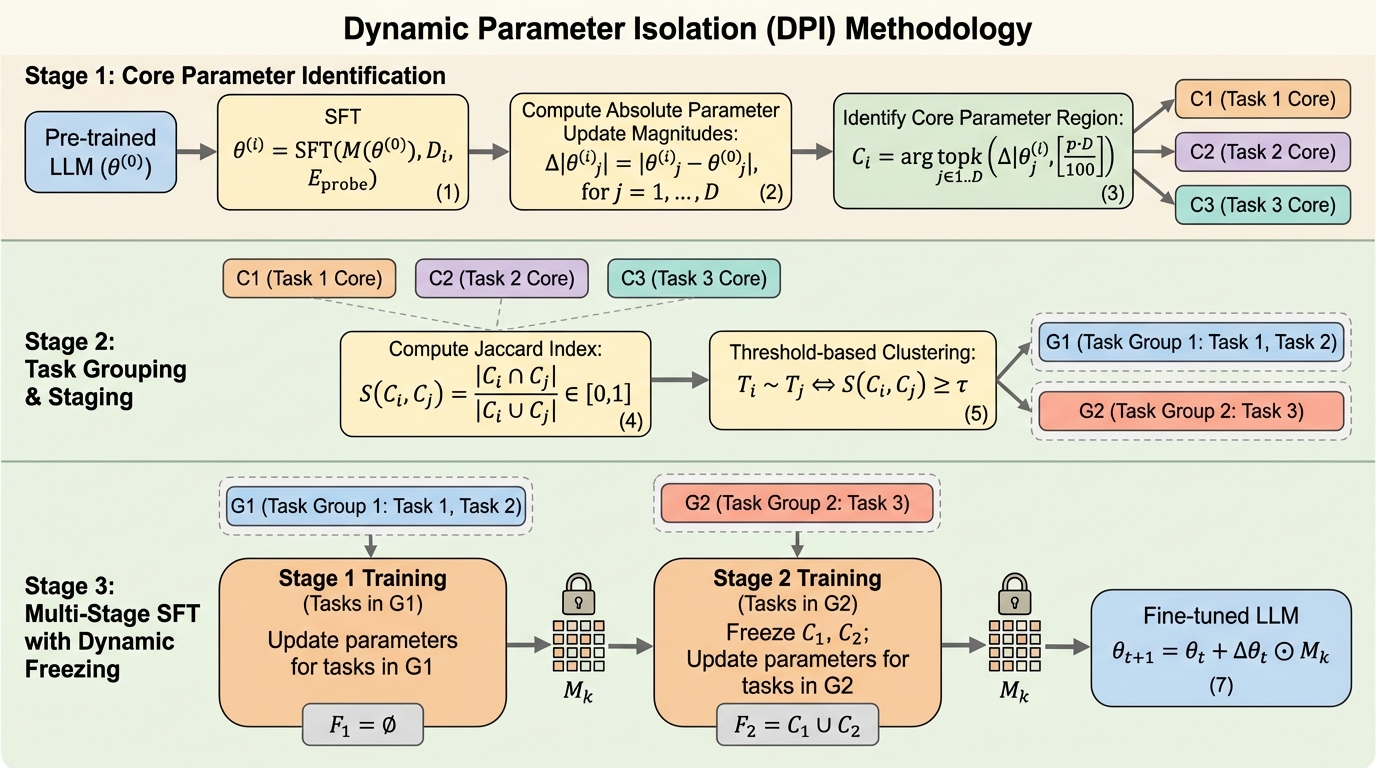
大規模言語モデル(LLM)の教師あり微調整(SFT)において、異なるタスク間の目的が衝突することで一方の性能が上がると他方が下がる「シーソー現象」を解決するため、タスクごとに依存するパラメータ領域が異なるという「パラメータの不均一性」に着目した新しい手法「DPI」が提案された。 DPIは、各タスクの学習で最も大きく更新される「コアパラメータ」を特定し、類似したタスクをグループ化して多段階で学習を進める際、以前の段階で学習したコアパラメータを凍結して保護することで、タスク間の干渉や既知の知識の忘却を効果的に防ぐ仕組みである。 複数の公開データセットを用いた検証の結果、DPIは数学的推論、コード生成、論理推論などの多様なタスクにおいて、従来のマルチタスク学習や単純な多段階学習を上回る性能を一貫して示し、モデルの規模やアーキテクチャを問わず有効であることが確認された。
なぜこの問題か
大規模言語モデル(LLM)を特定の用途に適応させ、人間の指示に従うように調整する手法として、教師あり微調整(SFT)は非常に重要な工程となっている。しかし、数学的推論、クリエイティブな文章作成、プログラミングコードの生成といった、性質の異なる多様なタスクを組み合わせて微調整を行う場合、大きな課題に直面する。それぞれのタスクは異なる目的や推論メカニズムを持っており、これらを同時に学習させようとすると、学習の勾配が互いに衝突し合うことがある。この結果、ある特定のタスクの性能が向上する一方で、別のタスクの性能が低下してしまう「シーソー現象」と呼ばれる問題が発生する。 従来の解決策として、複数のタスクを混合して学習するマルチタスク学習や、タスクを順番に学習させる多段階学習などが用いられてきた。マルチタスク学習では、全パラメータを一律に更新するため、異なるタスクの勾配が競合し、モデル全体の性能が最適化されない傾向がある。また、多段階学習では、ヒューリスティック(経験則)に基づいてタスクをグループ化し、順次学習を行うが、これはパラメータレベルでの干渉を根本的に解決するものではない。…
核心:何を提案したのか
本論文では、タスク固有のパラメータ領域を分離・隔離することで、干渉のない微調整を実現する「動的パラメータ隔離(DPI:Dynamic Parameter Isolation)」という手法を提案している。この手法の核心は、LLMのパラメータがタスクごとに異なる役割を担っているという性質をデータ駆動型で特定し、それを動的に保護する点にある。DPIは、追加のパラメータを一切導入することなく、既存のモデルパラメータの更新を制御するだけで、マルチタスク学習における性能低下と破滅的忘却の両方に対処する。 DPIのプロセスは大きく分けて3つの段階で構成されている。まず第1段階では、各タスクにとって最も重要な「コアパラメータ領域」を特定する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related