低リソース言語であるベンガル語におけるジェンダーバイアスの言語横断的プロービングおよびコミュニティに基づく分析
大規模言語モデル(LLM)におけるジェンダーバイアスの研究は英語に偏っており、ベンガル語のような低リソース言語かつ独自の文化背景を持つ言語での実態は十分に解明されていませんでした。 本研究では、翻訳、分類器、GPTによる生成、辞書ベースのマイニングなど多角的な手法を用いてベンガル語のバイアスを検証し、英語中心の検出枠組みをそのまま適用することの限界を明らかにしました。 農村部でのフィールド調査を含むコミュニティ主導のアプローチを導入することで、自動化システムでは捉えきれない文化特有のバイアスを特定し、より公平な自然言語処理システムの構築に向けた基盤を提示しました。
TL;DR(結論)
大規模言語モデル(LLM)におけるジェンダーバイアスの研究は英語に偏っており、ベンガル語のような低リソース言語かつ独自の文化背景を持つ言語での実態は十分に解明されていませんでした。 本研究では、翻訳、分類器、GPTによる生成、辞書ベースのマイニングなど多角的な手法を用いてベンガル語のバイアスを検証し、英語中心の検出枠組みをそのまま適用することの限界を明らかにしました。 農村部でのフィールド調査を含むコミュニティ主導のアプローチを導入することで、自動化システムでは捉えきれない文化特有のバイアスを特定し、より公平な自然言語処理システムの構築に向けた基盤を提示しました。
なぜこの問題か
自然言語処理(NLP)技術は、大規模言語モデルの登場によって翻訳や感情分析、質問回答などの分野で劇的な進歩を遂げましたが、これらのモデルには依然として社会的な不平等を助長する可能性のある本質的なバイアスが潜んでいます。特にジェンダーバイアスに関する研究の多くは英語や欧米の言語に集中しており、ベンガル語のようなグローバル・サウスの言語における言語的・文化的なバイアスについては、これまでほとんど調査が行われてきませんでした。ベンガル語は世界的に多くの話者を抱える言語でありながら、NLPのリソースが乏しい「低リソース言語」に分類されており、既存の英語中心のバイアス検出ツールをそのまま適用しても、言語構造の違いや社会文化的な背景の差異から正確に機能しないという課題があります。 ベンガル語は文法上の性別(文法ジェンダー)を持たないという特徴がありますが、それにもかかわらず、文化的な規範に根ざした暗黙的または明示的なバイアスが言語表現の中に埋め込まれています。例えば、代名詞自体はジェンダーニュートラルであっても、特定の職業や役割に関連付けられる文脈において、特定の性に偏ったステレオタイプが表現されることが少なくありません。…
核心:何を提案したのか
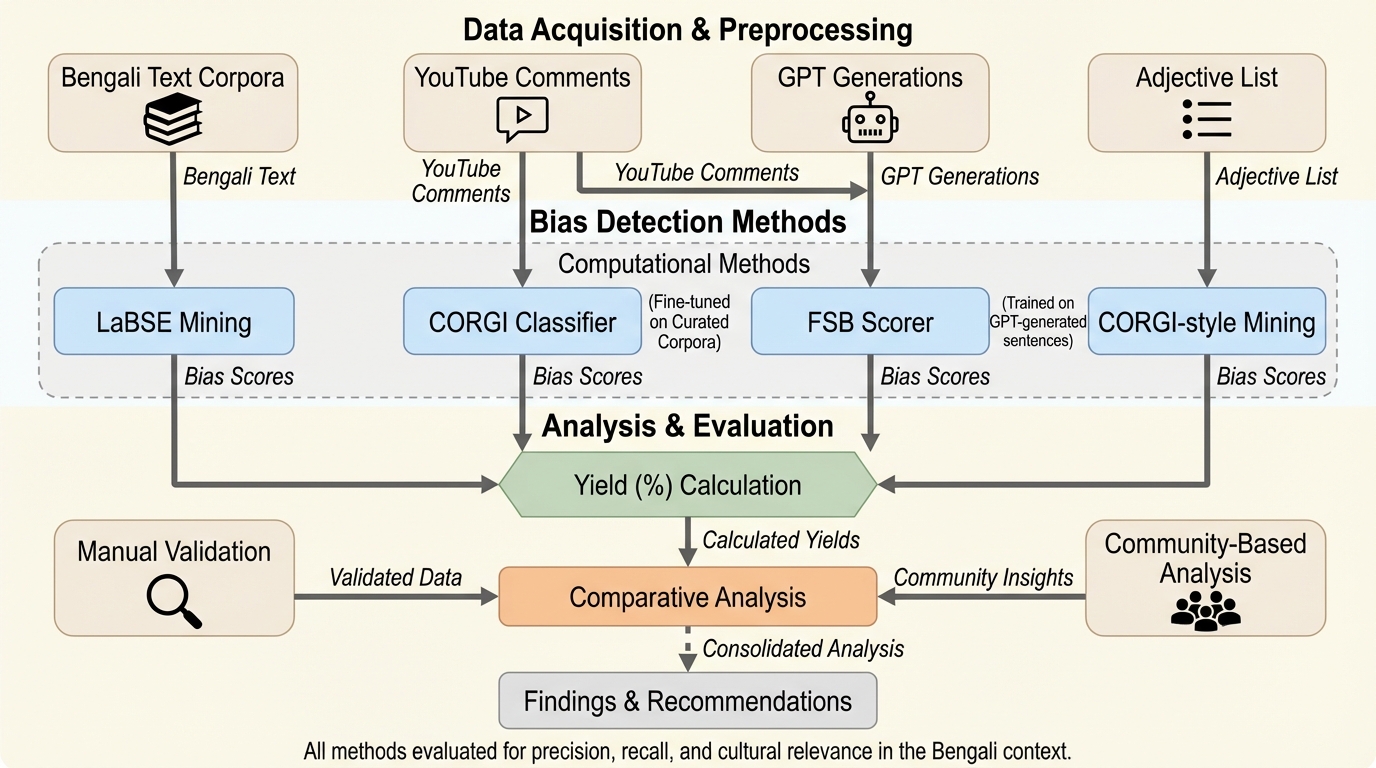
本研究の核心は、ベンガル語におけるジェンダーバイアスを特定するために、計算機的な手法とコミュニティ主導のフィールド調査を組み合わせた、多角的な言語横断的プロービング・フレームワークを提案した点にあります。具体的には、単一の手法に頼るのではなく、レキシコン(辞書)ベースのマイニング、機械学習による分類モデル、翻訳ベースの比較分析、そしてGPTを用いたバイアス生成という、性質の異なる複数のアプローチを統合して検証を行いました。これにより、意味論、構文論、語用論の各レベルでバイアスがどのように現れるかを包括的に診断することが可能になります。 また、本研究は自動化されたシステムによる分析にとどまらず、バングラデシュの農村部や低所得地域において2つのフィールド調査を実施しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related